快手 Keye 2.0 首次将 DSA 引入多模态,30B 参数打平 200B 开源模型
快手刚发布了新版多模态大模型 Keye-VL-2.0-30B-A3B,核心看点是把 DeepSeek 的稀疏注意力机制(DSA)搬到了多模态理解场景——这是业内首次。
这个动作不是为了炫技。DSA 解决的是长视频理解的算力瓶颈:传统 Full Attention 处理小时级视频时,计算量会指数级爆炸,而 Keye 2.0 通过稀疏注意力把 Prefill 成本直接砍掉 50%,Decode 阶段的成本曲线也变得极其平缓。结果是,30B 参数的模型在多项时序理解任务上,不仅吊打同级别开源基座,甚至跨级压制了 200B+ 的超大参数模型。
DSA 不是新东西,但用在多模态上是第一次
DSA 本身不新鲜。DeepSeek-V3 发布时就展示了稀疏注意力在纯文本场景的威力:通过让每个 token 只关注部分相关 token,而不是全局所有 token,大幅降低计算复杂度。但多模态场景更复杂——视频帧、图像 patch、文本 token 混在一起,时序信息、空间信息、语义信息交织,稀疏注意力怎么分配、哪些特征该保留、哪些该丢弃,都是新问题。
快手团队的做法是结合"时空统一编码"和"长时序特征聚合"。具体来说,他们先用 Slow-Fast 编码策略处理视频:对连续帧做 patch 级余弦相似度计算,相似度超过 95% 的判定为"快帧"(高帧数低分辨率),否则标记为"慢帧"(低帧数高分辨率)。慢帧保留高分辨率细节,快帧只分配慢帧 30% 的 token 预算。这样既保证了关键帧的信息密度,又控制了总 token 数。
然后在注意力层引入 DSA,让模型在处理超长序列时,能精准定位到真正重要的视觉特征和时序关系,而不是被大量冗余信息淹没。
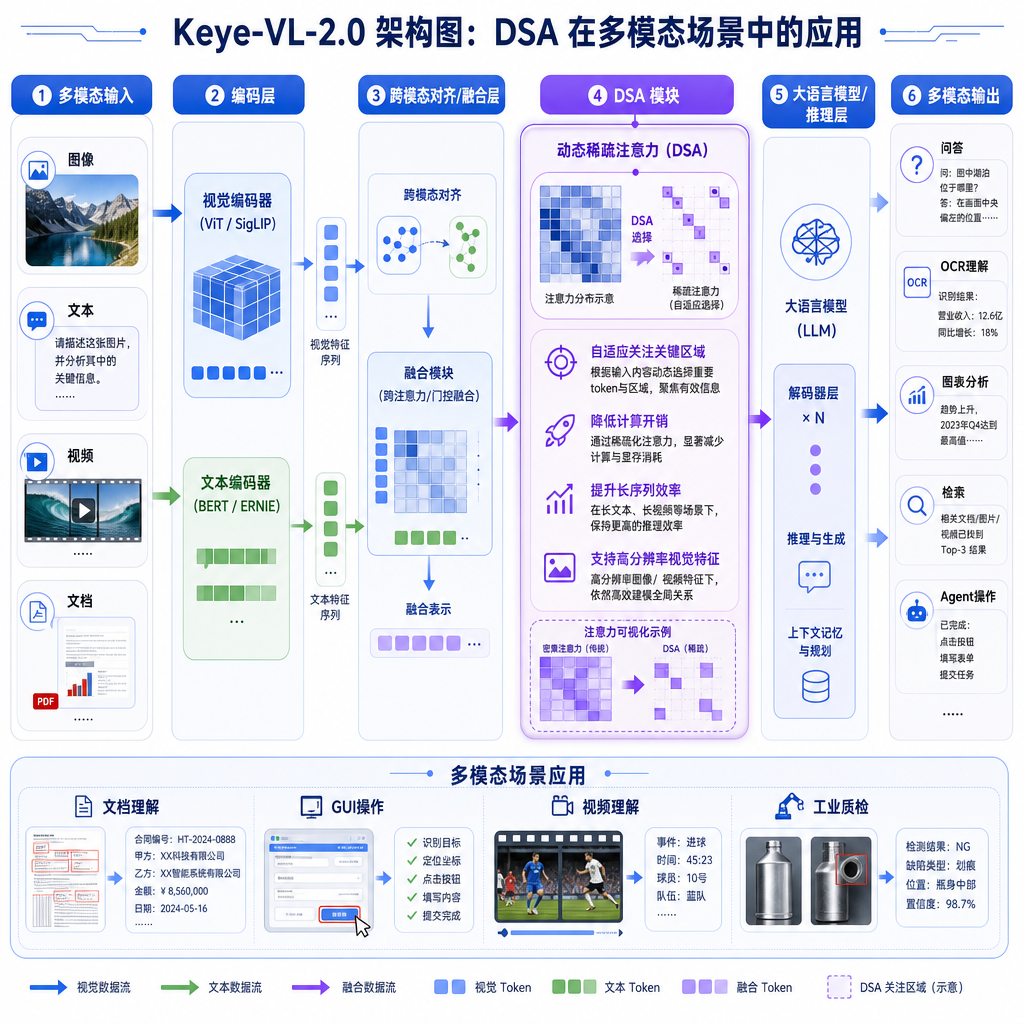
长视频理解:从"看得见"到"看得懂"
业内做长视频理解的模型不少,但大多数卡在两个问题上:一是"长上下文衰减"——输入帧数越多,注意力越稀释,准确率反而下降;二是只能做表层感知,缺乏深度推理能力。
Keye 2.0 在 VideoMME V2 上彻底扭转了衰减趋势。当输入从 64 帧扩展到 512 帧时,模型的平均准确率不降反升,从 35.34% 飙到 42.44%,非线性得分(代表复杂逻辑深度)也从 18.54 涨到 24.19。这意味着模型不仅"看得见"更多帧,还真的"看得懂"了。
在 LongVideoBench 上,Keye 2.0 拿到 74.10 的高分,远超同级别开源模型,逼近顶级闭源巨头。快手团队测试了一段 8 分钟的"长白山云顶天宫雪雕重建"纪录片,要求模型做场景划分和叙事总结。结果模型不仅精准切分了 8 个核心场景,还准确识别了"百年不遇的冬雨导致雪体坍塌"这个关键转折点,甚至提取了画面中"振兴东北"的刻字,关联人物背景,总结出"冰雪项目承载着东北人振兴家乡的炽热情感"这种深层主题。
这不是简单的 OCR + 字幕拼接,而是真正的跨模态推理。
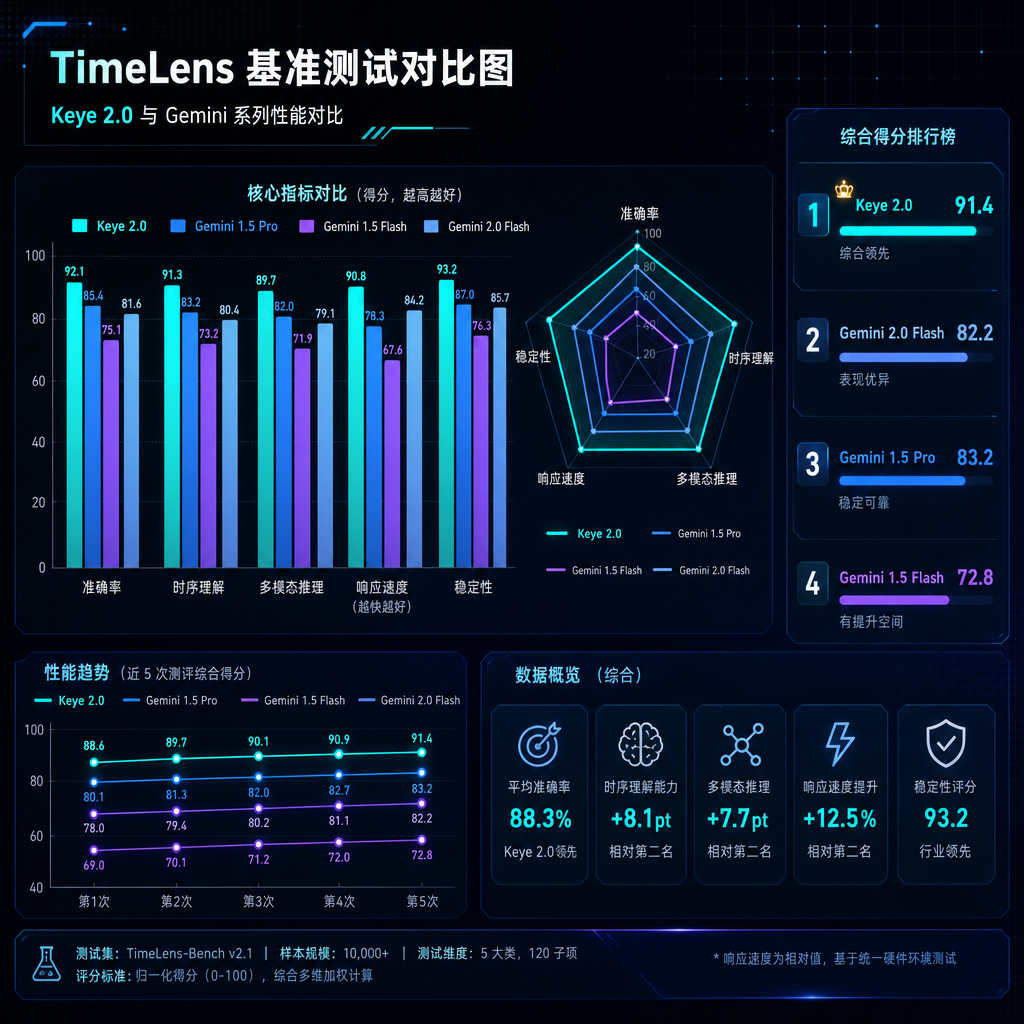
TimeLens 榜单:对标 Gemini 闭源模型
TimeLens 是业内公认最难的视频时序理解基准之一,要求模型不仅识别动作,还要给出精确的时间边界。Keye 2.0 在三个子任务上的表现:
- Charades-TimeLens(日常动作时序解析):mIoU 58.27,对标实测的 Gemini 3 Flash(61.19)和 Gemini 3.1 Pro(55.71)
- ActivityNet-TimeLens(视频动作定位):mIoU 58.54,全面超越官方数据 Gemini-2.5-Pro(58.1)以及实测的 Gemini 3 Flash(56.95)、Gemini 3.1 Pro(55.08)
- QVHighlights-TimeLens(高光时刻提取):mIoU 69.92,与顶尖闭源模型并驾齐驱,大幅超过实测的 Gemini 3 Flash(49.45)和 Gemini 3.1 Pro(46.09)
快手团队用一段制作陶杯的工艺流程视频做测试。从挖土、煅烧、水飞到修坯、配釉、陈茶,全程十几道工序,模型不仅全部识别,还把每个动作和视频时间轴做到了毫秒级对齐。这种细粒度的时序感知能力,在 30B 参数级别的开源模型里几乎看不到。
Agent 能力:从"观察者"到"行动者"
Keye 2.0 是 Keye 家族首次内建 Agent 协作机制的版本。这意味着模型不再只是被动回答问题,而是能主动规划任务、调用工具、执行操作。
在 Code Agent 方面,模型在 LivecodeBench v6 拿到 77.10 分,OJBench 39.20 分,不仅领先同级别参数模型,甚至超过了部分 200B 参数的开源基座。在更贴近真实业务的 SWE-bench Verified 任务中,模型跑通了 62.00 的基线成绩,具备了定位并修复代码 Issue 的能力。
Tool Agent 方面,模型在 TAU2-Bench 拿到 82.58 分,BFCL-V4 65.72 分,VITA-Bench 33.12 分。快手团队测试了一个复杂指令:查询指定标签门店、测算经纬度配送距离、筛选商品、创建酒店及配送订单。模型自主规划并按序调用了 get_delivery_store_info、longitude_latitude_to_distance、create_hotel_order 等十余次 API,全程没有崩溃或调用错误。
这种多步任务分解和工具调度能力,对于实际业务场景至关重要。快手内部已经在用 Keye 2.0 做智能剪辑、内容审核、搜索推荐等任务,Agent 能力让这些流程从"人工+AI 辅助"变成了"AI 主导+人工监督"。
技术细节:MOPD 解决多任务遗忘
多任务学习最大的坑是"灾难性遗忘"——模型学会新任务后,旧任务的性能会显著下降。快手团队用了一个叫 MOPD(多专家策略蒸馏/合并)的技术来解决这个问题。
核心思路是:先训练多个"同质模型"(相同网络结构,不同数据配比或随机种子)和"异质模型"(针对 OCR、数学等薄弱项单独强化的专家权重),然后通过分桶优势缩放(Bucket Advantage Scaling)方法,从 Token 级别对结构组织、教师表达、感知表征、推理运算进行细粒度建模,最后把这些权重融合起来。
这个方法的好处是,模型在学习新能力时,不会以牺牲通用底座能力为代价。Keye 2.0 最终定版在 Video、Agent、Math & Reasoning、STEM、Instruction Following 等维度都实现了全面爆发,没有明显短板。
快手团队还首次将 MOPD 引入重复崩溃治理。长序列生成时,模型容易陷入重复循环或输出崩溃,传统方法只能给一个模糊的负向反馈。MOPD 通过多粒度识别和精确定位,把负向反馈转化为可追溯的优化信号,显著提升了长序列生成的鲁棒性。
Post-training:Context-RL 压制幻觉
后训练阶段,快手团队设计了一套多模态强化学习体系,核心是 Context-RL 奖励机制。
传统 RLHF 在多模态场景容易出问题:模型可能会"脑补"一些视频里根本没有的内容,或者在多步推理时逻辑断层。Context-RL 的做法是强制模型严格锚定输入信息,不允许发散。具体来说,奖励函数会同时考虑规则奖励(通过正则和 AST 解析检查 JSON、Markdown 等结构)、生成式奖励(由外部大模型评估逻辑一致性)、模型奖励(来自 Keye-Reward 模型的细粒度偏好分)。
为了保证数据质量,团队设计了极为严格的筛选流程:先自动生成带步骤的解答,再由第二模型逐步打分分级,中档样本经人工精修后复审,高分样本直接入库。这种"高信噪比数据 + 高精度奖励"的组合,彻底打破了 RL 训练中的作弊和坍塌问题。
结果是,Keye 2.0 在视觉感知和多模态推理中的幻觉倾向被大幅压制,长程推演的决策稳定性实现了质的飞跃。
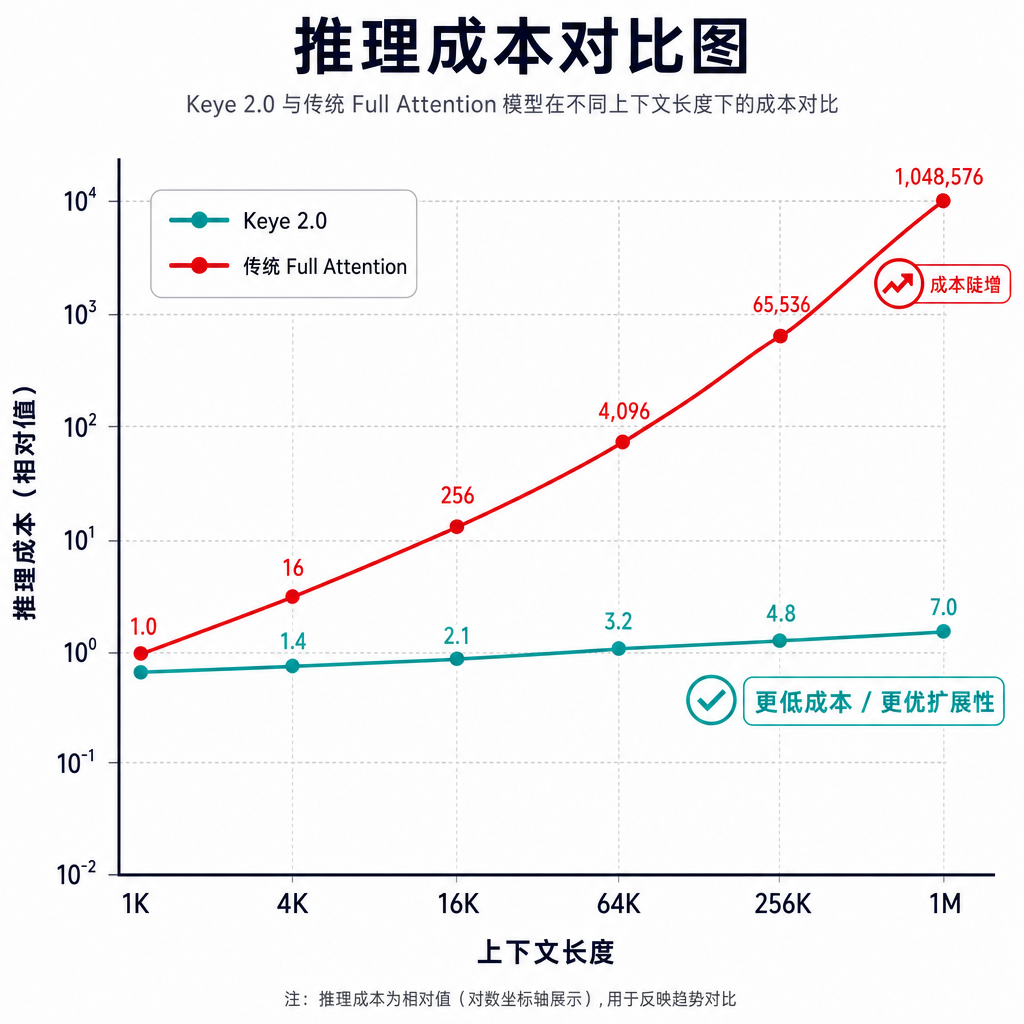
算力效能:推理成本降低 50%
引入 DSA 架构和系统级工程优化后,Keye 2.0 的长序列 Prefill 阶段成本降低了 50%。更重要的是,随着输入视频上下文拉长,传统 Full Attention 的 Decode 计算量会指数级暴增,而 Keye 2.0 基于 DSA 的 Decode 成本曲线极其平缓。
快手团队还做了一系列系统级优化:
- ExtraIO 架构:将 IO 独立部署、按需扩容,消除视频解码和抽帧带来的 IO 瓶颈
- ViT-LM 异构并行 + 两级负载均衡:破解长视频、变长序列下计算/显存的均衡难题
- ViT 激活值零显存优化(Recompute/Offload):进一步降低显存占用
这些优化让 30B 参数的 Keye 2.0 在推理效率上远超 200B+ 参数的开源模型,为超长视频的大规模落地提供了极具竞争力的低成本方案。
业务落地:不只是 Benchmark 刷分
快手内部已经在三个维度全面应用 Keye 2.0:
1. 内容理解与推荐
Keye 2.0 的细粒度长视频感知和图文解析能力,被融入到生成式推荐、内容生态治理、商业化定向投放等核心链路。模型能像人类一样精准捕捉视频的"弦外之音"和时序逻辑,大幅提升了推荐系统的分发命中率,也在广告营销的精细化标签提取上取得了显著的商业收益转化。
2. 自动化生产流水线
"精准多模态理解 + Agent 自动化调度"的组合,打造了端到端的全自动闭环工作流。从海量视频库的智能检索、关键高光切片提取,到基于逻辑演进的自动化剪辑包装,再到契合爆款逻辑的营销文案生成,Keye 2.0 大幅降低了优质内容的生产门槛。
3. 安全治理
快手安全算法团队用 Keye 2.0 做内容审核,模型不仅能识别违规画面,还能理解上下文语境,判断是否存在隐晦的违规表达。这种深度理解能力,让审核准确率和召回率都有明显提升。
开源模型的新标杆
Keye 2.0 的成功,证明了一件事:在多模态理解这个赛道上,参数规模不是唯一变量,架构创新和工程优化同样重要。30B 参数打平 200B 开源模型,甚至在部分任务上逼近 Gemini 这种顶级闭源模型,靠的是 DSA 稀疏注意力、Slow-Fast 编码、MOPD 多任务融合、Context-RL 幻觉压制等一系列技术组合拳。
快手团队表示,Keye 2.0 的成功经验会继续向更大规模的模型迁移,目标是真正的原生多模态(Native Multimodal)和端到端深度融合。从目前的表现来看,这个方向值得期待。
Keye-VL-2.0-30B-A3B 现已开源,支持 256K 超长上下文,开发者可以直接用来做长视频理解、多模态推理、Agent 协作等任务。对于需要处理小时级视频、追求低成本高效能的场景,这个模型是个不错的选择。
参考来源
- 快手自研多模态大语言模型成功引入DSA - Linux.do - 社区讨论帖,包含模型核心特性概述
- 十分钟读懂DeepSeek-V3.2 稀疏注意力DSA - 知乎专栏 - DSA 技术原理解析
- Keye-VL-2.0-30B-A3B - Hugging Face - 模型权重和技术文档
- Keye GitHub 仓库 - 开源代码和使用指南