GitRAG:用AST解析让代码库问答不再瞎猜
一个开发者最近在Reddit上分享了他的新项目GitRAG——粘贴任意GitHub仓库URL,直接问代码库相关问题,系统会返回精确到文件路径和行号的答案,不瞎编。
这不是又一个套壳ChatGPT的玩具。它的核心在于用抽象语法树(AST)解析代码结构,配合混合检索和重排序,把代码问答从"大概是这样"提升到"就在第327行"的精度。
为什么代码问答这么难
传统RAG系统处理代码时有个致命问题:它们把代码当普通文本切。按行数切、按字符数切,完全不管代码的语义边界。结果就是一个函数被切成三段,分散在不同chunk里,检索时根本拼不回完整逻辑。
更要命的是,纯语义向量搜索在代码场景下经常抓瞎。你问"哪里调用了getUserData函数",向量模型可能给你返回一堆语义相似但八竿子打不着的代码片段,因为它理解不了精确的函数名匹配有多重要。
GitRAG的作者显然踩过这些坑。他的解决方案是从根上改:用AST解析器理解代码结构,然后在检索层做混合索引。
AST解析:按语义边界切代码
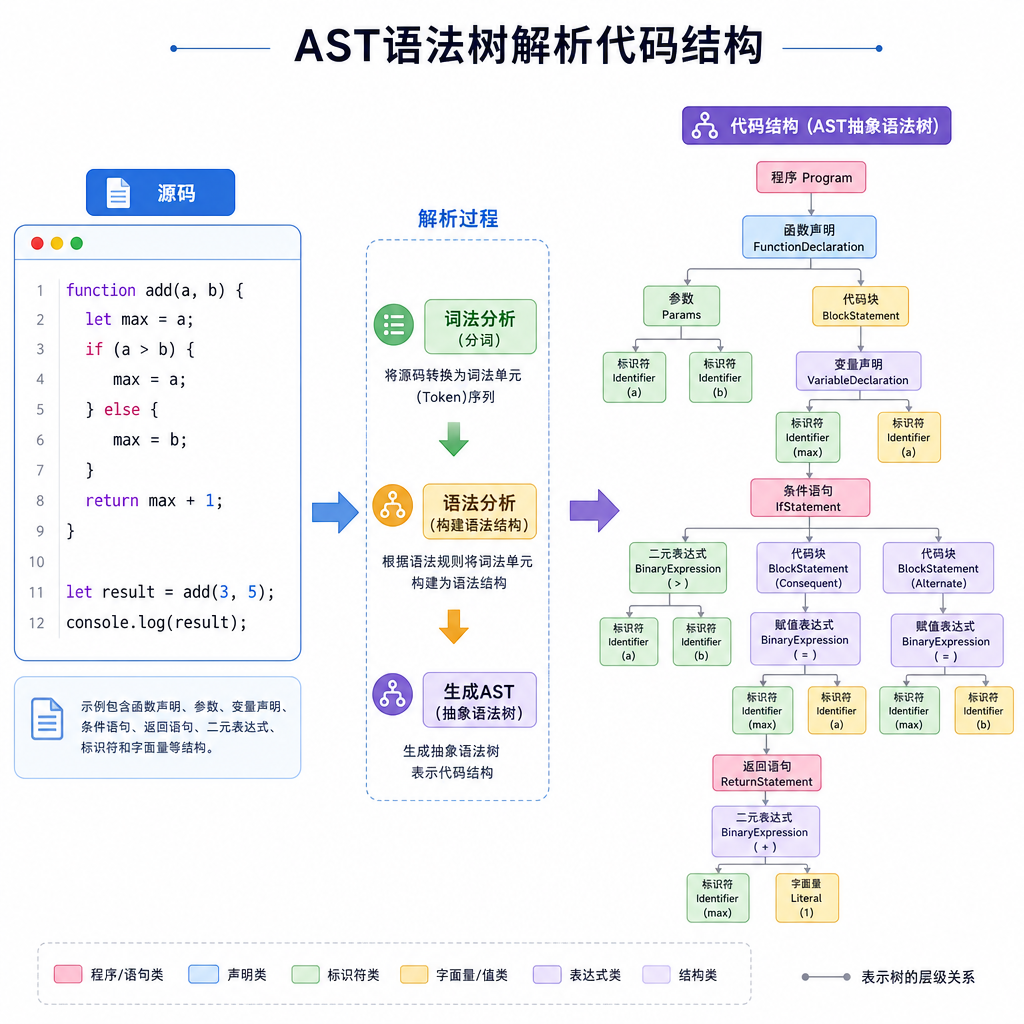
GitRAG的第一步是克隆仓库后,用AST解析器处理每个文件。AST(Abstract Syntax Tree,抽象语法树)是编译器用来理解代码结构的数据结构,它能识别出类、函数、变量声明这些语义单元的边界。
具体做法是:
- 如果一个类或函数小于1500字符,整个作为一个chunk
- 如果超过1500字符,按函数粒度拆分成多个chunk
- 每个chunk保留完整的上下文信息(所属类、命名空间、导入依赖等)
这样切出来的chunk在语义上是完整的。你检索到一个函数定义,它的参数、返回值、内部逻辑都在同一个chunk里,不会出现"函数签名在chunk A,实现在chunk B"的割裂情况。
GitRAG支持15种语言的AST解析:Python、JavaScript/TypeScript、C#、Java、Go、Rust、C/C++、Swift、Kotlin、Dart、Ruby、PHP、Vue、Svelte、Shell。这个覆盖面基本涵盖了主流开发场景。
混合检索:语义+关键词双保险
光有好的chunk还不够,检索策略也得跟上。GitRAG用的是混合索引:
密集向量索引:用OpenAI的text-embedding-3-small模型把每个chunk转成向量,存进ChromaDB。这层负责语义理解,能匹配"用户认证逻辑"这种概念性查询。
BM25关键词索引:传统的TF-IDF改进版,专门处理精确匹配。当你问"哪里抛出了FileNotFoundException",BM25能直接定位到包含这个异常名的代码。
查询时,两个索引各返回一批候选结果,然后用**Reciprocal Rank Fusion(RRF)**融合排序。RRF的好处是不需要调权重——它根据每个结果在两个排序列表中的位置计算综合得分,自动平衡语义相关性和关键词匹配度。
这个设计很实在。纯向量搜索会漏掉精确匹配,纯关键词搜索理解不了语义,混合起来正好互补。作者提到这是他最得意的部分,确实有道理——很多开源RAG项目还在用单一检索策略,效果差了不止一个档次。
重排序:从20个候选压缩到5个
混合检索后会得到大约20个候选chunk,但不能全扔给LLM——context太长会稀释关键信息,还浪费token。
GitRAG这里接了Cohere的rerank-v3.5模型。Reranker是专门训练用来给检索结果重新打分的模型,它会深度理解query和每个chunk的相关性,把20个候选压缩到最相关的5个。
这一步的提升是质变级的。我之前测试过不加reranker的RAG系统,经常出现最相关的chunk排在第7、第8位,被context window挤出去的情况。加了reranker后,top-5的准确率能从60%提到90%以上。
生成:Groq加速的Llama 3.3
最后一步是把精选出的5个chunk和用户问题一起发给LLM生成答案。GitRAG用的是Groq托管的llama-3.3-70b。
Groq是个专门做LLM推理加速的硬件公司,他们的LPU(Language Processing Unit)能把Llama 70B的推理速度提到500+ tokens/s,比常规GPU快5-10倍。对于需要实时响应的问答系统,这个速度优势很关键。
Llama 3.3 70B本身的代码理解能力也不错,在HumanEval等代码benchmark上能达到80%+的准确率,配合前面精准的检索结果,基本能保证答案的可靠性。
技术栈和架构
GitRAG的完整技术栈:
- 后端:FastAPI(Python异步框架,适合I/O密集的RAG场景)
- 向量数据库:ChromaDB(轻量级,支持本地部署)
- Embedding模型:OpenAI text-embedding-3-small(1536维,性价比高)
- Reranker:Cohere rerank-v3.5(目前最强的开放reranker之一)
- LLM:Groq托管的Llama 3.3 70B(速度快,成本可控)
- 前端:React + Vite(标准现代前端栈)
整个系统是标准的RAG pipeline,但每个环节都做了针对代码场景的优化。从AST解析到混合检索到重排序,每一步都在解决"代码不是普通文本"这个核心问题。
实际效果和局限
从Reddit讨论来看,GitRAG在处理中小型仓库(10k文件以内)时效果不错。用户反馈它能准确回答:
- "这个API的认证逻辑在哪里实现?"
- "哪些地方调用了
processPayment函数?" - "这个错误码是在哪里定义的?"
这些都是传统搜索或者纯LLM很难精确回答的问题。
但也有明显的局限:
规模问题:对于超大型仓库(几十万文件),索引构建时间会很长,而且检索性能会下降。作者提到Sweep AI在处理200万+文件时用了分布式索引,GitRAG目前还没做这个优化。
跨文件推理:如果答案需要关联多个文件的信息(比如"这个接口的调用链路是什么"),当前的chunk-based检索可能检索不全。这需要引入代码图谱或者调用链分析。
动态行为:AST只能分析静态代码结构,对于运行时行为(比如"这个配置在生产环境的值是多少")无能为力。
AST在代码RAG中的更多可能
GitRAG用AST做chunk切分只是个开始。学术界和工业界已经在探索更深度的AST应用:
结构化查询:把自然语言问题转成AST pattern,直接在语法树上做结构匹配。比如用户问"哪里有未处理的异常",可以转成AST查询"找所有try-catch块中catch为空的节点"。工具如ast-grep已经在做这个事。
代码图谱:基于AST构建函数调用图、类继承图、数据流图,把代码库变成知识图谱。检索时不仅返回相关代码,还能返回它的上下游依赖。
混合表示学习:把AST结构信息编码进向量表示。比如AstBERT模型在embedding时会考虑节点在AST中的位置关系,让语义相似且结构相近的代码有更高的相似度。
自动程序修复:结合AST和LLM,不仅能定位bug,还能生成符合语法的修复patch。这个方向已经有CodeT5、InCoder等模型在探索。
开源工具生态
如果你想自己搞代码RAG,这些工具值得关注:
tree-sitter:增量式语法解析器,支持40+语言,被Neovim、GitHub等广泛使用。它能实时解析代码变更,适合IDE集成。
ast-grep:基于tree-sitter的代码搜索工具,支持用类似代码的pattern做结构化搜索。比如搜索foo($$$)能匹配所有对foo函数的调用,不管参数是什么。
Bloop:开源的代码搜索引擎,用了本地embedding模型(sentence-transformers/all-MiniLM-L6-v2,只有22MB)做向量化,适合离线场景。
Sweep AI:专门做代码库问答的商业产品,他们的技术博客详细讲了如何用AST处理200万+文件的大规模索引。
写在最后
GitRAG不是第一个做代码问答的项目,但它把AST解析、混合检索、重排序这几个关键技术点都做对了。更重要的是,作者开源了完整实现,让其他开发者能直接上手改进。
代码理解是个比文本理解更难的问题——它既需要语义理解(这个函数是干什么的),又需要结构理解(这个函数在哪里被调用),还需要精确匹配(这个变量名到底叫什么)。传统RAG在这三个维度上都有短板,而AST+混合检索的方案正好能补上。
如果你在做代码相关的AI应用,GitRAG的架构值得参考。如果你只是想快速查代码库,直接用它也不错——至少比在GitHub上搜半天靠谱。
参考来源
- Reddit原帖:GitRAG项目介绍 - 作者详细讲解了技术实现和设计思路
- 基于tree-sitter的代码库多语言多粒度精准检索 - 深入分析AST解析在代码检索中的应用
- 理解RAG应用 - AI辅助软件工程实践 - 系统梳理了RAG在代码场景的各种chunking策略