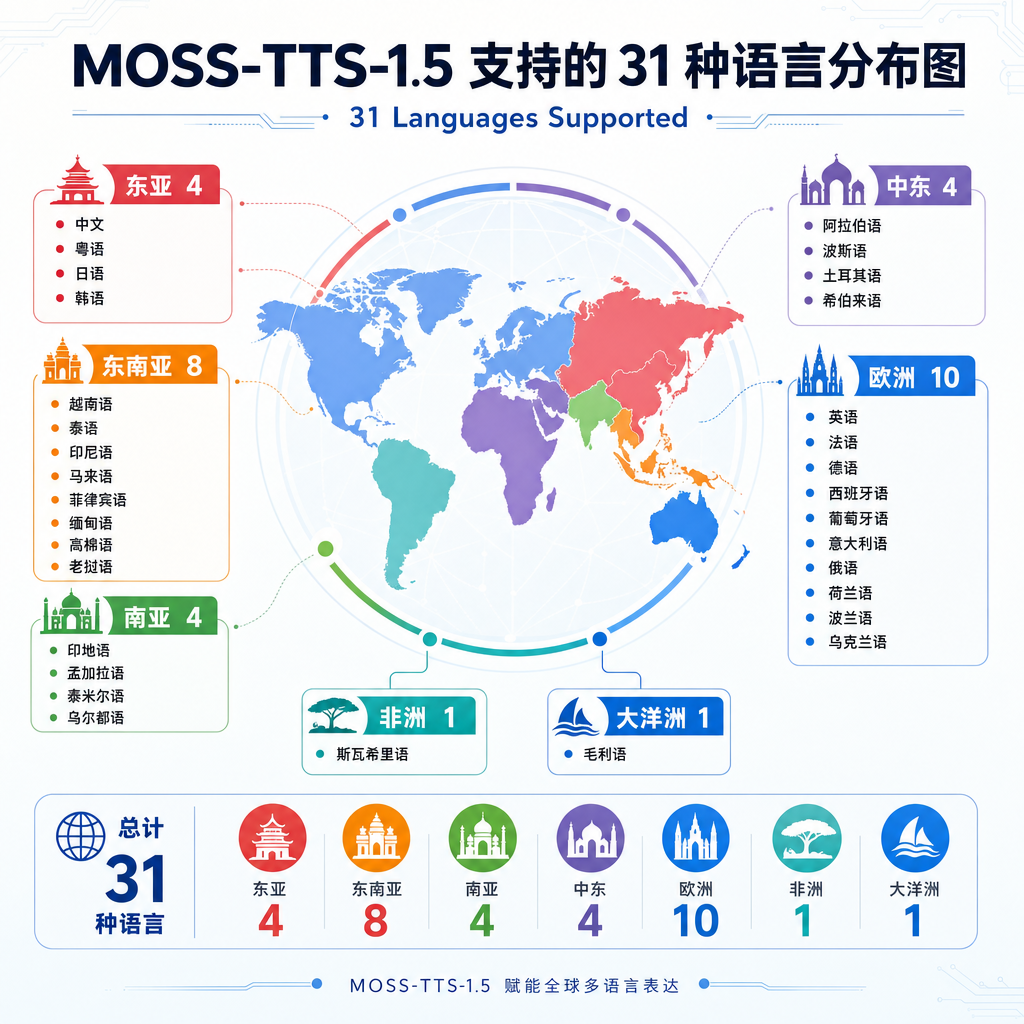
复旦 OpenMOSS 和 MOSI.AI 团队昨天把 MOSS-TTS-1.5 推上了 Hugging Face 和 GitHub。这是 MOSS-TTS Family 自今年 2 月首发、4 月放出 Nano 版本之后的第三次迭代,主线只有一件事:把语言覆盖从 20 种扩到 31 种。
听起来像是个例行更新,但对做多语种产品的开发者来说,这次补齐的几个语种相当关键。新增的 11 种语言是粤语、荷兰语、芬兰语、印地语、马其顿语、马来语、罗马尼亚语、斯瓦希里语、他加禄语、泰语和越南语。东南亚四件套(泰、越、马来、他加禄)齐了,南亚有了印地语,非洲拿到斯瓦希里语,欧洲补上荷兰语和北欧的芬兰语,再加上一直被中文 TTS 忽视的粤语,这套覆盖范围基本能撑起一个面向新兴市场的语音产品矩阵。
不是堆数据,是接着练
值得说一句的是 1.5 的训练方式。官方说明里写得很直白——保留 1.0 的 20 种语言能力,在原模型基础上继续训练扩展新语种。这和很多团队"重新洗牌"式的多语言扩展不一样,意味着原本英语、中文、日语、韩语这些主力语种的音质和稳定性不会因为新语种的加入而退化,至少理论上不会。
做过多语言 TTS 的人都知道这种"灾难性遗忘"的痛。Coqui XTTS 当年扩语种时就出现过英语音色变糊的情况,开发者要么忍着用,要么自己拉旧版本回退。MOSS-TTS 这次的做法更接近 LLM 圈常见的 continual pretraining,对工程化部署友好——你今天用的 1.0 链路,换上 1.5 权重大概率不需要重测原有语言。
MOSS-TTS Family 的产品线长什么样
顺便理一下这个家族目前的状态,因为有点容易混。
- MOSS-TTS-Nano(100M):4 月 10 日发布,4 月 17 日补了 ONNX 构建。1 亿参数、CPU 优先,4 核机器就能实时跑 48kHz 立体声,零样本声音克隆,Apache 2.0。这是冲着 Kokoro 那个生态位去的,但 Kokoro 主打英语,Nano 一开始就是 20 语种。
- MOSS-TTS-1.0 / 1.5:主力模型线,参数规模可扩到 80 亿,覆盖长文本、多说话人对话、音色设计、音效生成。
- 整个家族的定位是"实际应用的 TTS 基础模型",而不是单点 demo。
这次的 1.5 属于主力线的小版本升级。从 Hugging Face 仓库结构看,权重命名和加载接口都和 1.0 兼容,迁移成本基本为零。
31 种语言够用吗
直接对比一下当前的开源 TTS 第一梯队:
| 模型 | 语言数 | 参数量 | 许可证 |
|---|---|---|---|
| MOSS-TTS-1.5 | 31 | 主力线可至 8B | Apache 2.0 |
| XTTS v2 | 17 | 约 467M | CPML(非商业) |
| F5-TTS | 主要中英 | 330M | CC-BY-NC |
| Kokoro | 英日中等 | 82M | Apache 2.0 |
| ChatTTS | 中英 | 约 500M | AGPL |
31 这个数字目前在开源 TTS 里是头部水平,更重要的是许可证 Apache 2.0。XTTS v2 那个 CPML 一直是商用项目的雷区,F5-TTS 的 NC 也卡死了变现路径。MOSS-TTS 整个家族都走 Apache 2.0,这意味着你做 SaaS、做出海产品、做硬件嵌入都不用额外谈授权。
实际跑一下
仓库的接入路径没什么花活,标准 Hugging Face 流程:
git clone https://github.com/OpenMOSS/MOSS-TTS.git
cd MOSS-TTS
pip install -r requirements.txt
模型权重从 Hugging Face 拉:
from moss_tts import MOSSTTSPipeline
pipe = MOSSTTSPipeline.from_pretrained(
\"OpenMOSS-Team/MOSS-TTS-v1.5\",
device=\"cuda\"
)
# 粤语测试
audio = pipe.synthesize(
text=\"今日天气唔错,去边度行下啊?\",
language=\"yue\",
reference_audio=\"path/to/speaker.wav\", # 零样本克隆
)
audio.save(\"output.wav\")
# 越南语
audio_vi = pipe.synthesize(
text=\"Hôm nay thời tiết rất đẹp.\",
language=\"vi\",
reference_audio=\"path/to/speaker.wav\",
)
推理显存这块,主力模型在单卡 24GB 上跑长文本流式没压力,Nano 走 ONNX 路径在 CPU 上就能撑住实时率。如果你只是要做客服机器人这种场景,Nano 版本就够,1.5 留给需要更高表现力或者更准发音的场合,比如有声书、配音、教育类内容。
那些没说但值得关注的点
几个我自己实测和翻 issue 时注意到的细节:
第一,词元级时长控制。 这是 MOSS-TTS 1.0 就有的特性,1.5 继承下来。意思是你可以精确指定某个字、某个词读多长,对做视频配音对轴、做歌词级别的语音合成是刚需。市面上大部分开源 TTS 只能给整句加语速参数,做不到这个粒度。
第二,多说话人对话场景。 不是简单的多说话人合成,而是真正的对话——一段输入里多个角色交替发言,模型保持音色一致性和对话节奏。这点在播客生成、有声小说这类场景上是杀手特性。
第三,环境音效生成。 Family 里另一条线是音效生成模型,可以和 TTS 配合做带环境氛围的语音内容。1.5 这次没动这部分,但接口预留了。
第四,新增的小语种音质如何。 这是我最关心也是最不确定的。荷兰语、芬兰语这种数据相对充足的还好说,但马其顿语、斯瓦希里语、他加禄语这些低资源语言的训练语料质量直接决定了输出可用性。从社区已有的几条试听反馈看,泰语和越南语的声调处理基本到位,粤语的九声六调还在测,建议做粤语产品的开发者自己跑一遍 benchmark 再下结论。
TTS 这一年
从去年下半年到现在,开源 TTS 圈的迭代节奏明显快了起来。F5-TTS、CosyVoice 2、Spark-TTS、Kokoro、IndexTTS、再到 MOSS-TTS Family,每个月都有新东西出来。一个判断是 TTS 正在重走 LLM 走过的路:模型越来越小(Kokoro 82M、Nano 100M)、推理越来越快(CPU 实时)、许可证越来越宽松(Apache、MIT 替代 CC-NC),但天花板还没到。
语音克隆的零样本质量、长文本的稳定性、情感和风格控制、流式延迟,这几个维度都还有不小空间。MOSS-TTS-1.5 这次没有在这些方向上做大动作,只补语种,看得出团队的节奏是把基础能力先铺稳,后面 2.0 大概率会在表现力或者多模态控制上发力。
对开发者来说,现在选型 TTS 比一年前轻松太多。如果你在做出海、做小语种、做对许可证敏感的商业产品,MOSS-TTS-1.5 应该直接进候选名单。如果只是中英文场景且不在意商用授权,CosyVoice 2 或 IndexTTS 也都是不错的选择。
TTS 的"白菜化"看起来真的要来了。
参考来源
- MOSS-TTS-1.5 开源发布讨论 - linux.do — 社区首发讨论帖,含语言列表
- OpenMOSS/MOSS-TTS GitHub 仓库 — 主仓库,包含安装和使用文档
- MOSS-TTS-v1.5 Hugging Face 模型页 — 模型权重下载与使用说明
- MOSS-TTS-Nano GitHub 仓库 — Nano 版本独立仓库,CPU 部署参考