DeepSeek V4 本月发布:万亿参数开源,价格只有 GPT-4o 的五分之一

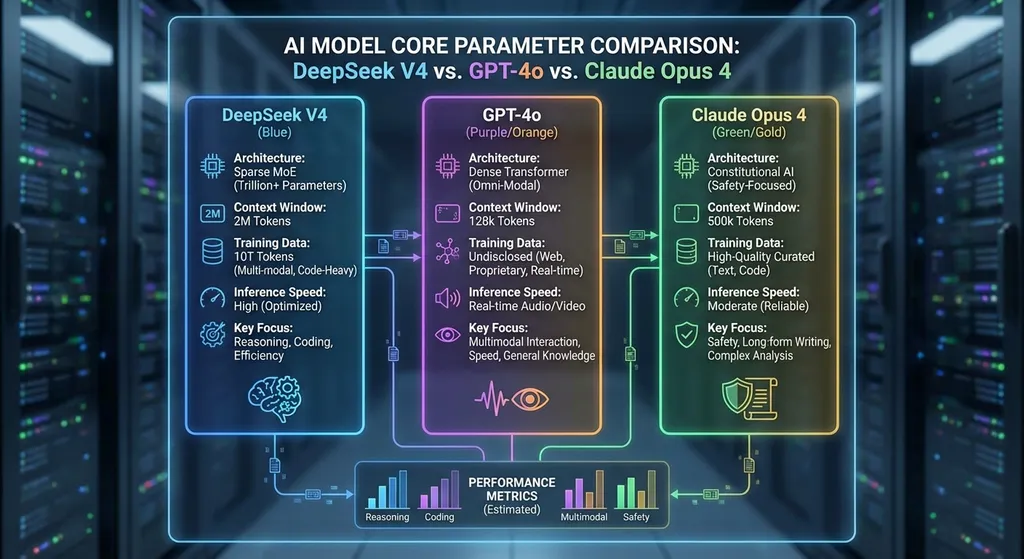
DeepSeek V4 确认 2026 年 4 月发布,万亿参数、百万 Token 上下文、原生多模态,Apache 2.0 开源,API 输入价格仅 $0.5/百万 Token,编程跑分超越 GPT-5 和 Claude Opus。
DeepSeek V4 定了,就在这个月。
经历了春节前后的跳票之后,梁文锋团队终于给出了明确信号:2026 年 4 月正式发布。万亿参数,百万 Token 上下文,原生多模态,Apache 2.0 开源。这不是某个维度的小幅迭代——这是一次把牌全摊在桌面上的代际升级。
更刺激的是价格:API 输入每百万 Token 仅 0.5 美元。GPT-4o 是 2.5 美元,Claude Opus 4 是 15 美元。换句话说,同样的预算,你用 V4 能跑的量是 Opus 的 30 倍。
这篇文章拆解 V4 的核心技术突破,聊聊它对开发者意味着什么,以及为什么这次「延期」反而是个好信号。
先说跳票这件事
原定春节前后发布的 V4 大参数版本,推迟到了 4 月。今年 1 月,小参数版本已经提前流入开源社区做适配,大版本却迟迟没来。
据接近项目的人士透露,延期的核心原因是梁文锋团队在过去半年里集中精力补齐技术短板,尤其是长期记忆(LTM)和多模态融合这两块硬骨头。这不是「做不出来」,而是「不想半成品上线」。
从 V1 到 V4,DeepSeek 只用了两年,团队不到 200 人。这个节奏在全球范围内都算激进。选择在最后关头踩一脚刹车,说明他们对 V4 的定位不只是「比 V3 好一点」——而是要一步到位,把开源模型的天花板直接顶上去。
万亿参数 + 百万 Token 上下文:不只是数字大
先说参数量。V4 总参数达到万亿级别,但这不意味着推理时要把一万亿参数全跑一遍。DeepSeek 从 V2 开始就在用 MoE(Mixture of Experts)架构,V4 大概率延续这个路线——万亿总参数,实际激活的可能只是其中一部分。这也是它能把 API 价格压到 0.5 美元的底层逻辑。
再说上下文窗口。100 万 Token 是什么概念?大约等于 750 万个英文单词,或者一次性塞进去整部《三体》三部曲外加几十万行代码。
对开发者来说,这意味着几件事:
- 大型代码库可以整体喂进去做分析、重构、漏洞检测,不用再手动切片
- 长文档处理(法律合同、研报、技术文档)告别分段拼接的 workaround
- Agent 场景下,对话历史和工具调用记录可以完整保留,不用反复做 summarization
与 V3 相比,上下文窗口的扩展不是简单的「把数字调大」。传统 Transformer 的注意力机制是 O(n²) 复杂度,100 万 Token 如果硬算,推理成本会爆炸。V4 在这里做了架构级的改动,这就引出了它最核心的技术突破。
长期记忆(LTM):这可能是 V4 最被低估的能力
大模型的「记忆力」一直是个老大难问题。上下文窗口再大,也是「工作记忆」——对话结束就没了。你跟 GPT 聊了三个月的项目细节,换个 session 它一个字都不记得。
V4 的做法是自研了一套叫 Engram(记忆印迹)的条件记忆机制,把知识存储和动态推理在架构层面解耦。
翻译成人话:模型有了一个独立的「长期记忆模块」,可以永久保存对话历史和知识库信息,检索复杂度接近 O(1)。这不是 RAG(检索增强生成)那种外挂方案,而是模型原生支持的能力。
这对 Agent 开发者来说是个大事。当前 Agent 架构的一个核心痛点就是状态管理——你得自己搞一套外部记忆系统,把关键信息存起来,下次对话再塞回去。V4 如果真能在模型层面解决这个问题,Agent 的开发复杂度会大幅下降。
当然,「接近 O(1)」这个说法需要等实际发布后验证。Engram 机制的具体实现细节目前还没有公开论文,到底是在 attention 层面做了稀疏化改造,还是引入了外部记忆网络,暂时只能等。但如果效果真如内部测试所示,这会是 V4 最有长期价值的技术贡献。
编程能力:跑分登顶,但更值得看的是工程化
跑分先摆出来:
| 基准测试 | DeepSeek V4 | GPT-5 | Claude Opus 4 | |---------|------------|-------|---------------| | HumanEval | 87.6%+ | — | — | | SWE-Bench Verified | 83.7% | < 83.7% | < 83.7% | | Design2Code | 92% | — | — |
HumanEval 87.6%、SWE-Bench Verified 83.7%,据称超越了 GPT-5 和 Claude Opus。Design2Code(设计稿转代码)准确率 92%。
但跑分只是一面。更值得关注的是 V4 在工程化编程上的能力跃升:
- 支持 338 种编程语言
- 可一次性理解数十万行跨文件代码库(配合百万 Token 上下文)
- 自动完成项目重构、漏洞检测、测试用例生成
这意味着 V4 不只是「帮你写函数」的 Copilot,而是能理解整个项目上下文、做系统级操作的工程伙伴。对于日常要处理大型 monorepo 的开发者来说,这个能力的实用价值远比 HumanEval 多几个百分点重要得多。
SWE-Bench Verified 83.7% 这个数字尤其值得注意。SWE-Bench 测的是模型解决真实 GitHub issue 的能力——给你一个 bug report,你得定位问题、改代码、跑通测试。这比 HumanEval 那种「写个函数」的题目难一个量级,也更接近开发者的真实工作场景。
原生多模态:不是「加个视觉模块」
V4 的多模态不是后期拼接的,而是原生统一架构,文本、图像、视频在底层做端到端语义融合。
具体能力包括:
- 基于 DeepSeek-OCR 技术,精准理解复杂图表、数学公式、扫描文档
- 工业质检图像识别
- 直接支持图像生成、视频理解、多模态问答
- 高精度 SVG 图形生成
「原生多模态」和「外挂多模态」的区别在哪?打个比方:外挂方案像是给一个只会读文字的人配了个翻译,先把图片翻译成文字描述,再让他处理;原生方案是这个人本身就能同时看图和读字,信息损失小得多。
对开发者来说,这意味着你不需要在 pipeline 里单独跑一个视觉模型再把结果喂给语言模型——一个 API 调用搞定。
国产算力适配:华为昇腾的存在感
一个容易被忽略的细节:V4 优先适配了华为昇腾等国产芯片,算力利用率达到 85%,部署成本据称仅为英伟达方案的三分之一。
基于数万张 CPU+DCU 集群,DeepSeek 已初步完成万亿参数模型的稳定运行验证。这对国内企业的意义不言而喻——在芯片供应链不确定性持续存在的背景下,一个能在国产算力上高效跑起来的万亿参数模型,本身就是战略级资产。
自研的 mHC 架构号称能把推理成本降低 90%。如果这个数字属实,那 V4 的 0.5 美元定价就不只是「烧钱补贴」,而是有真实的成本结构支撑。
价格战的新阶段
把价格再拉出来看一眼:
| 模型 | 输入价格(每百万 Token) | |------|------------------------| | DeepSeek V4 | $0.5 | | GPT-4o | $2.5 | | Claude Opus 4 | $15 | | Qwen 3.6-Plus | — |
V4 是 GPT-4o 的五分之一,Opus 的三十分之一。而且它还开源。
Apache 2.0 协议意味着:自由商用,无用户量门槛,你可以拿去微调、部署、卖服务,不用给 DeepSeek 交一分钱。Hugging Face 联合创始人称之为「重大里程碑」。
这对 API 服务市场的冲击是直接的。当一个万亿参数、跑分登顶的模型以 $0.5 的价格开放 API,同时还完全开源,其他厂商的定价逻辑就得重新算了。Token 消耗增速正在超越算力建设增速,云计算的商业模式可能要重新算账。
值得一提的是,阿里的 Qwen 3.6-Plus 最近刚登顶 OpenRouter,日调用量达到 1.4 万亿 Token。国产模型在全球开发者社区的存在感越来越强,V4 的加入只会加速这个趋势。
对开发者意味着什么
如果你现在在做 AI 应用开发,V4 发布后有几件事值得立刻关注:
- Agent 架构可能要重构。如果 LTM 能力如宣传所述,你现在那套外部记忆管理的代码可能可以大幅简化。
- 长文档处理的 pipeline 可以简化。百万 Token 上下文 + 低价格,意味着很多之前需要做 chunking + retrieval 的场景可以直接「全塞进去」。
- 多模态应用的开发成本下降。原生多模态意味着少维护一个视觉模型的调用链路。
- 私有化部署有了新选择。Apache 2.0 + 国产算力适配,对数据合规要求高的企业来说是个利好。
V4 发布后,通过 OpenAI Hub 这类兼容 OpenAI 格式的聚合平台,开发者可以用同一套代码无缝切换到 DeepSeek V4,不用改接口。下面是一个调用示例:
from openai import OpenAI
client = OpenAI(
api_key="your-openai-hub-key",
base_url="https://api.openai-hub.com/v1"
)
# 文本推理 —— 利用百万 Token 上下文处理大型代码库
response = client.chat.completions.create(
model="deepseek-v4",
messages=[
{
"role": "system",
"content": "你是一个资深软件工程师,擅长代码审查和重构。"
},
{
"role": "user",
"content": "请分析以下代码库的架构问题并给出重构建议:\n\n"
+ open("entire_codebase.txt").read() # 百万 Token 上下文,整个代码库一次性塞入
}
],
max_tokens=8192
)
print(response.choices[0].message.content)
# 多模态调用 —— 原生图像理解,无需额外视觉模型
response = client.chat.completions.create(
model="deepseek-v4",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "这张架构图有什么设计问题?请指出潜在的单点故障。"},
{
"type": "image_url",
"image_url": {"url": "https://example.com/architecture-diagram.png"}
}
]
}
],
max_tokens=4096
)
print(response.choices[0].message.content)
模型名称以实际上线为准,但接口格式不会变——这就是用标准 OpenAI 兼容格式的好处,切模型只改一个字符串。
冷静看几个问题
在兴奋之余,有几个点需要保持清醒:
第一,跑分和实际体验之间永远有 gap。HumanEval 和 SWE-Bench 的分数很亮眼,但真实开发场景的复杂度远超基准测试。V4 在处理模糊需求、跨领域知识整合、长链路推理上的表现,要等社区大规模使用后才能下结论。
第二,百万 Token 上下文的实际可用性。窗口大不等于「大海捞针」能力强。之前不少模型号称支持超长上下文,但在窗口后半段的信息检索准确率会明显下降。V4 的 Engram 机制能否真正解决这个问题,是个关键验证点。
第三,开源不等于好用。万亿参数的模型,私有化部署的硬件门槛不低。虽然有国产算力适配和推理成本优化,但对中小团队来说,API 调用可能仍然是更现实的选择。好在 V4 还提供了多个参数规格的版本——1 月流出的小参数版本中,E2B 最低 1.5GB 内存就能跑,31B Dense 版本在 AIME 数学测试中从 20.8% 飙到 89.2%,覆盖了从端侧到工作站的不同场景。
第四,生态成熟度。模型能力再强,如果周边工具链(微调框架、推理引擎、部署方案)跟不上,开发者的迁移成本就会很高。DeepSeek 1 月提前放出小参数版本给社区适配,说明他们意识到了这个问题,但生态建设不是一朝一夕的事。
写在最后
从 V1 到 V4,两年时间,不到 200 人的团队。DeepSeek 的节奏在全球 AI 公司里都算异类。
这次 V4 的发布,如果各项能力如内部测试所示,那它不只是「又一个开源模型」——它会实质性地改变开发者选择模型时的成本计算方式。当一个跑分登顶、价格最低、还完全开源的模型摆在面前,「为什么不试试」会变成一个很难回答的问题。
4 月具体哪天发布还没有确切消息。但可以确定的是,这个月的 AI 圈不会平静。
参考来源
- 万亿参数还开源?DeepSeek V4 来了,这次真的不一样 — 知乎专栏,V4 核心参数与定价分析
- DeepSeek V4 拟 4 月上线!长期记忆、编程与多模态能力全面跃升 — 新浪科技,技术突破详细解读
- DeepSeek V4 拟 4 月上线(ZAKER 转载) — LTM、编程、多模态三大方向技术细节
- DeepSeek-V4 百度百科 — V4 与 V3 代际升级对比
- DeepSeek V4 被曝 4 月上线,但有个坏消息 — 网易,延期原因与国产算力适配分析
- 环闻财经微博 — V4 核心突破与国产芯片适配信息
