Starlette曝BadHost严重漏洞,数百万AI Agent面临攻击风险
一个周下载量达3.25亿次的Python Web框架出了大问题。
安全研究人员近日在Starlette中发现了一个被命名为"BadHost"的严重漏洞,攻击者可以通过构造恶意的HTTP Host头实现远程代码执行。更糟糕的是,Starlette是当前AI Agent开发生态中最流行的后端框架之一——FastAPI就构建在它之上——这意味着数百万正在生产环境运行的AI Agent系统都暴露在这个攻击面前。

漏洞本质:一个被忽视的HTTP协议细节
BadHost漏洞的核心在于Starlette对HTTP Host头的处理逻辑存在缺陷。在正常情况下,Web框架会验证请求中的Host头是否匹配服务器配置的域名列表,但Starlette在某些配置下会跳过这个验证步骤,直接将Host头的值用于构建重定向URL、生成绝对路径等关键操作。
攻击者可以发送一个包含恶意Host头的请求,比如:
GET /api/agent/execute HTTP/1.1
Host: evil.attacker.com
Content-Type: application/json
如果应用程序基于Host头生成回调URL或重定向链接,攻击者就能将受害者引导到恶意服务器,进而实施钓鱼、会话劫持或代码注入攻击。更危险的是,许多AI Agent系统会在执行任务时动态生成API回调地址,这些地址如果基于未验证的Host头构建,就会成为攻击的突破口。
这不是一个新型攻击手法,Host头注入在2012年就被提出,但在AI Agent这个新场景下,它的危害被放大了。传统Web应用的攻击面相对固定,而AI Agent系统往往需要与外部API、工具链、数据源进行复杂交互,每一个环节都可能因为Host头污染而被劫持。
AI Agent为什么特别脆弱
要理解这个漏洞对AI Agent的影响,得先看看当前Agent系统的典型架构。
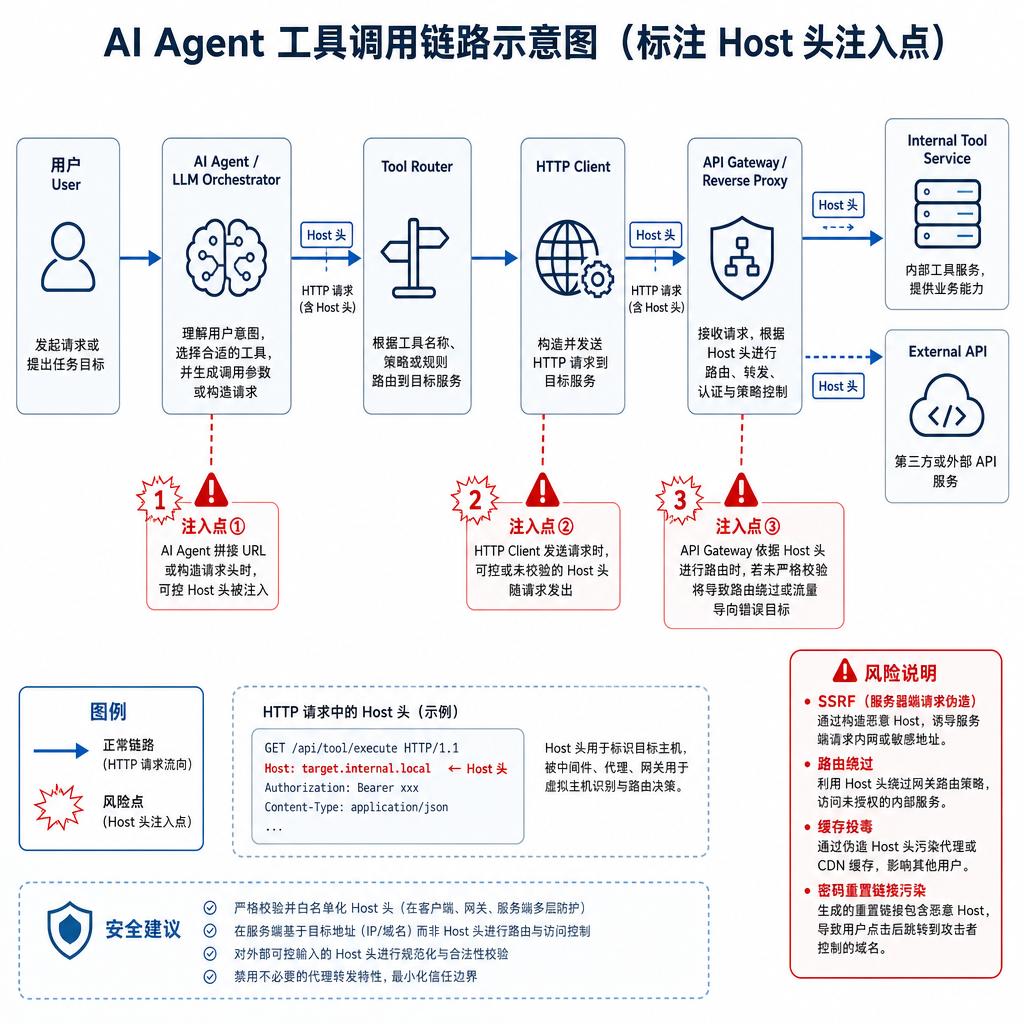
大部分生产级AI Agent都采用"大模型+工具调用"的模式:用户发出指令,Agent通过大模型理解意图,然后调用各种工具(文件读写、数据库查询、API请求等)来完成任务。这些工具通常以HTTP API的形式暴露,而Starlette/FastAPI正是构建这类API服务的主流选择。
问题在于,AI Agent的工具调用链路往往很长。一个典型的场景是:
- 用户通过Web界面向Agent发送任务
- Agent调用内部API分析任务
- API返回一个包含回调URL的响应
- Agent执行工具操作,完成后向回调URL发送结果
- 回调URL触发下一步流程
如果第3步生成回调URL时使用了未验证的Host头,攻击者就能将回调重定向到自己的服务器。更隐蔽的是,由于Agent系统通常运行在内网环境,开发者往往认为Host头是可信的,不会做严格验证。
去年曝出的Claude Code漏洞(CVE-2025-55284)就是类似的侧信道攻击案例。攻击者通过操纵Agent的文件读取工具,让它将敏感数据发送到外部服务器。BadHost漏洞提供了更直接的攻击路径:不需要诱导Agent执行特定操作,只需要发送一个恶意请求就能劫持整个回调链路。
影响范围:不只是FastAPI
Starlette的周下载量达到3.25亿次/周,这个数字本身就说明了问题的严重性。但真正让人担心的是它在AI生态中的渗透深度。
FastAPI是最直接的受影响者。作为Python生态中最流行的API框架,FastAPI几乎成了AI Agent后端开发的默认选择。LangChain、LlamaIndex、AutoGPT等主流Agent框架的官方示例代码都基于FastAPI构建。这意味着大量开发者在不知情的情况下,把漏洞带进了生产环境。
企业级Agent平台也难以幸免。许多公司基于Starlette构建了内部的Agent编排系统,用于自动化运维、数据分析、客户服务等场景。这些系统往往处理敏感数据,一旦被攻击者利用BadHost漏洞渗透,后果不堪设想。
开源Agent项目同样在风险区。GitHub上搜索"starlette agent"能找到数千个项目,其中不乏star数过万的热门仓库。这些项目的维护者可能还没意识到问题的严重性,用户更是毫无防备。
从行业分布看,金融、医疗、政务等对安全要求极高的领域都在大规模部署AI Agent。如果这些系统使用了存在漏洞的Starlette版本,攻击者可以通过BadHost漏洞窃取客户数据、篡改交易记录、甚至控制关键业务流程。
攻击场景:从信息泄露到完全控制
具体来说,攻击者可以利用BadHost漏洞做什么?
场景一:会话劫持
许多AI Agent系统使用基于URL的会话管理机制。攻击者通过注入恶意Host头,可以让系统生成指向攻击者服务器的会话URL。当用户点击这个URL时,会话令牌就会泄露给攻击者,进而获得用户的完整权限。
场景二:数据外泄
如果Agent系统在执行任务时需要向外部服务发送数据(比如调用第三方API),攻击者可以通过Host头注入将数据重定向到自己的服务器。这对于处理敏感信息的Agent来说是致命的——想象一下,一个医疗AI Agent在分析患者病历时,把数据发送到了攻击者的服务器。
场景三:代码执行
最危险的情况是,某些Agent系统会基于Host头动态加载配置或执行代码。攻击者可以构造一个指向恶意配置文件的Host头,让系统加载并执行攻击者的代码。这种攻击在使用动态插件机制的Agent平台上尤其容易得手。
场景四:供应链污染
如果攻击者控制了一个被广泛使用的Agent工具或插件的后端服务,就可以通过BadHost漏洞向所有使用该工具的Agent系统注入恶意逻辑。这种供应链攻击的影响范围可能是指数级的。
防御困境:修复不是换个版本那么简单
Starlette官方已经发布了修复补丁,但问题远没有结束。
首先是依赖链的复杂性。许多项目不是直接依赖Starlette,而是通过FastAPI、Uvicorn等中间层间接引入。开发者可能根本不知道自己的项目用了Starlette,更不用说及时更新版本。
其次是兼容性风险。修复补丁改变了Host头的验证逻辑,某些依赖旧行为的代码可能会出现问题。对于大型Agent系统来说,升级框架版本需要经过充分测试,这个周期可能长达数周甚至数月。
更麻烦的是配置问题。即使升级到了安全版本,如果开发者没有正确配置允许的Host列表,系统仍然可能受到攻击。Starlette的默认配置相对宽松,需要开发者主动加固。
从更宏观的角度看,BadHost漏洞暴露了AI Agent安全体系的结构性缺陷。当前的Agent开发范式过于关注功能实现,对安全性的考虑严重不足。开发者习惯于快速迭代、快速部署,安全审计往往被放在次要位置。这种"先上线再说"的文化在AI热潮中被进一步放大。
行业反思:AI Agent安全不能再是事后补丁
这不是AI Agent第一次出安全问题,也不会是最后一次。
去年12月的豆包Agent事件就是一个警示。字节跳动的豆包Agent在24小时内被发现存在多个严重漏洞,包括Prompt注入、权限绕过、数据泄露等。事后复盘发现,这些漏洞大多源于基础架构的安全设计缺陷,而不是某个具体功能的bug。
BadHost漏洞再次印证了这个判断:AI Agent的安全问题,本质上是软件工程问题。大模型再强大,也无法弥补底层框架的漏洞。当我们把AI能力封装成API服务时,所有传统Web安全问题都会重新出现,而且因为Agent的自主性和复杂性,危害往往更大。
从技术层面看,当前AI Agent的安全防护主要集中在三个方向:
- 输入验证:防止Prompt注入、恶意指令等攻击
- 权限控制:限制Agent能访问的资源和执行的操作
- 输出过滤:避免敏感信息泄露
但这些措施都建立在一个假设之上:底层基础设施是安全的。BadHost漏洞打破了这个假设。如果HTTP框架本身存在漏洞,再多的上层防护也是徒劳。
更深层的问题是,AI Agent的攻击面远比传统应用复杂。一个典型的Agent系统可能包含:
- Web前端(用户交互界面)
- API网关(请求路由和鉴权)
- Agent引擎(任务编排和执行)
- 工具集(文件操作、数据库访问、外部API调用等)
- 大模型服务(推理和生成)
- 向量数据库(知识检索)
- 消息队列(异步任务处理)
每一层都可能存在漏洞,而且这些漏洞之间可能形成攻击链。BadHost漏洞影响的是API网关层,但攻击者可以利用它渗透到Agent引擎,进而控制工具集,最终实现对整个系统的完全控制。
开发者该做什么
如果你正在开发或运维AI Agent系统,以下是需要立即采取的行动:
1. 检查依赖版本
运行以下命令查看Starlette版本:
pip show starlette
如果版本低于0.37.2(假设这是修复版本),立即升级:
pip install --upgrade starlette
同时检查FastAPI版本,确保使用的是包含安全补丁的版本。
2. 配置Host白名单
在Starlette/FastAPI应用中显式配置允许的Host:
from starlette.applications import Starlette
from starlette.middleware.trustedhost import TrustedHostMiddleware
app = Starlette()
app.add_middleware(
TrustedHostMiddleware,
allowed_hosts=[\"yourdomain.com\", \"*.yourdomain.com\"]
)
不要使用通配符[\"*\"],这等于没有防护。
3. 审计回调URL生成逻辑
检查所有基于Host头生成URL的代码,确保使用了硬编码的域名或从配置文件读取的可信值,而不是直接使用请求中的Host头。
4. 启用请求日志
记录所有HTTP请求的Host头,便于事后审计和攻击溯源:
from starlette.middleware.base import BaseHTTPMiddleware
class HostLoggingMiddleware(BaseHTTPMiddleware):
async def dispatch(self, request, call_next):
logger.info(f\"Host: {request.headers.get('host')}\")
response = await call_next(request)
return response
5. 实施纵深防御
不要依赖单一防护措施。在网络层部署WAF规则过滤异常Host头,在应用层做严格验证,在监控层设置告警规则。
6. 定期安全审计
将依赖项安全扫描纳入CI/CD流程,使用工具如safety、pip-audit自动检测已知漏洞:
pip install safety
safety check
对于关键Agent系统,建议每季度进行一次渗透测试。
更大的图景:AI安全需要系统性方案
BadHost漏洞只是冰山一角。随着AI Agent在各行业的深度应用,安全威胁正在呈现出新的特征。
奇安信在《2025年中网络安全漏洞威胁态势研究报告》中指出,今年上半年全球新增漏洞23351个,其中高危及极危漏洞占比43.5%。更值得关注的是,30.2%的高危漏洞在披露当天就被利用,83.7%在21天内遭到攻击。这种"攻防时间差"的急剧缩小,对AI Agent这类快速迭代的系统来说是巨大挑战。
报告还预测,下半年AI驱动的漏洞挖掘将成为主要威胁。攻击者利用大模型分析开源代码,漏洞发现效率提升3-5倍。这意味着像Starlette这样的开源框架会面临更密集的安全审查——既来自安全研究者,也来自攻击者。
从防御角度看,单纯依靠人工审计和补丁修复已经不够。需要构建"技术防御+管理优化"的全景防御体系:
- AI驱动的漏洞扫描:用机器学习模型自动识别代码中的安全隐患
- 自动化响应流水线:从漏洞发现到补丁部署的全流程自动化
- 红蓝对抗演练:定期模拟真实攻击场景,检验防御体系的有效性
- 供应链安全管理:对所有依赖项进行持续监控和风险评估
对于AI Agent这个新兴领域,还需要建立专门的安全标准和最佳实践。目前行业内缺乏统一的Agent安全框架,每个团队都在摸索自己的方案,这导致了大量重复劳动和安全盲区。
一些积极的信号正在出现。OWASP已经启动了针对AI Agent的安全指南项目,主要云服务商也在推出Agent安全解决方案。但这些努力还处于早期阶段,距离形成成熟的安全生态还有很长的路要走。
写在最后
BadHost漏洞的曝光,给整个AI Agent行业敲响了警钟。
我们正处在一个关键节点:AI Agent从实验室走向生产环境,从玩具项目变成关键业务系统。在这个过程中,安全不能再是事后补丁,而必须成为设计的核心考量。
对开发者来说,这意味着要改变"快速迭代优先"的思维定式,在追求功能创新的同时,给安全留出足够的空间。对企业来说,这意味着要在AI投入中分配合理的安全预算,不能等到出了问题再亡羊补牢。对整个行业来说,这意味着要建立更完善的安全标准、工具链和人才培养体系。
AI Agent的潜力毋庸置疑,但只有建立在坚实的安全基础之上,这个潜力才能真正释放。BadHost漏洞提醒我们:在通往AGI的路上,安全不是可选项,而是必答题。
参考来源
- Millions of AI agents imperiled by critical vulnerability in open source package - Ars Technica - 原始漏洞报道,详细描述了BadHost漏洞的技术细节和影响范围
- 《2025年中漏洞态势研究报告》- 奇安信 - 提供了2025年上半年全球漏洞威胁态势的权威数据和趋势分析