一个 skill,让两个 AI 编程助手在同一个会话里互相审稿
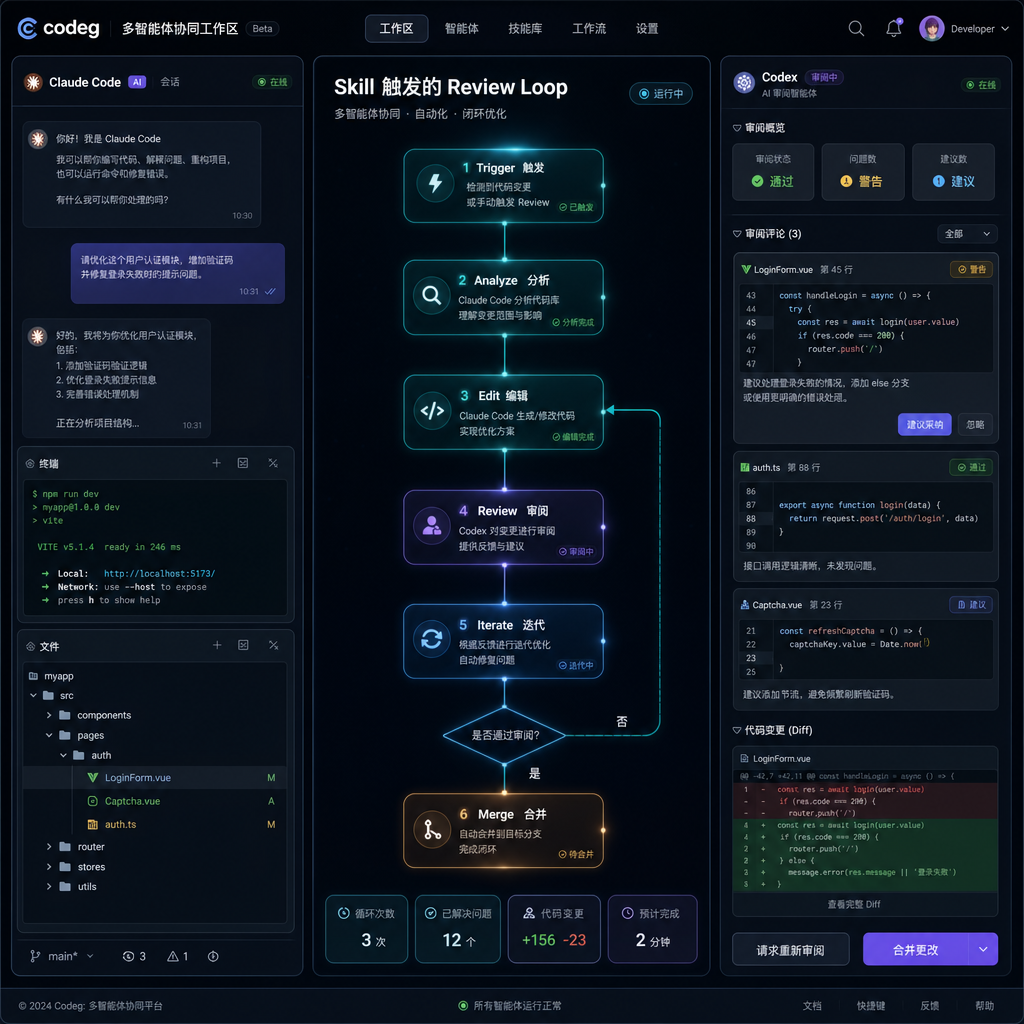
这两天 linux.do 上有篇帖子在开发者圈里被反复提起:一位用户晒出了自己在 Codeg 里写的一个 skill——sub-agent-review-loop,开启多智能体协同后,Claude Code 写完代码会自动喊 Codex 过来 review,发现问题直接修,修完再交给 Codex 二审,循环到 Codex 判定 "production-ready" 才算交卷。
听起来不复杂,但触动开发者的是它解决的那个具体痛点:以前你得自己在两个 AI 工具之间来回搬运 diff、复制 prompt、贴回意见,现在这套动作让 skill 自己跑完了。
这事值得说一说。它不是什么新模型发布,也不是什么概念性的多 Agent 框架,而是一个非常落地的工程化案例——多智能体协同从 demo 阶段走到 "我每天写代码都用得上" 的样子。
skill 干了什么:把 review loop 写成确定性流程
先把这个 skill 的内容贴出来看看(节选自原帖):
---
name: sub-agent-review-loop
description: Use when any task could modify code, tests, config, schemas, migrations, deps, build/deploy scripts, artifacts, or behavior before completion
---
# Sub-Agent Review Loop
## Overview
Use Codex as an independent reviewer after work that can modify artifacts or behavior. Loop until the latest result is production-ready.
**Core principle:** Work is not complete until Codex approves the latest fixed version as production-ready.
## Required Loop
1. Finish the implementation and run the relevant local checks.
2. Call Codeg MCP `delegate_to_agent` with `agent_type: "codex"`, absolute `working_dir`, and a self-contained `task` containing the request, changed files or diff/SHAs, checks run, and constraints.
3. Require this quality bar: **production-ready**
关键设计有几处。
触发条件写得很死。 description 里明确列了一长串触发场景:动到代码、测试、配置、schema、迁移脚本、依赖、构建/部署脚本、产物或行为,任何一个沾边就走 review loop。这不是模糊的 "觉得需要的时候",而是工程意义上的硬约束——只要落盘的东西可能影响线上行为,就必须过 Codex 这一关。
Codex 不是建议者,是 gate keeper。 loop 的 exit condition 写得很狠:"Work is not complete until Codex approves the latest fixed version as production-ready"。Claude Code 自己说改完了不算,得 Codex 点头。这跟传统的 self-critique(让模型自己检查自己)有本质区别——评审方是另一个独立模型、独立上下文,不会被 Claude Code 自己的推理路径带偏。
delegate 的载荷是结构化的。 调用 Codeg MCP 的 delegate_to_agent 时,要求传入绝对路径的 working_dir、自包含的 task 描述、改动文件清单或 diff/SHA、本地已跑过的检查、以及约束条件。这意味着 Codex 接到任务时拿到的是完整上下文,不需要去猜 Claude Code 在干嘛。
这个设计的价值,在于把 "两个 AI 互相 review" 这件以往依赖人类胶水的事,变成了 skill 文件里几行声明式描述。
为什么是 Codex 来审 Claude Code
开发者圈里有个共识:Claude 系列在长上下文工程任务、复杂重构上手感更顺,但偶尔会出现自信过头、跳过边界条件的情况;Codex(GPT-5 系的代码推理)在挑刺、找逻辑漏洞、抠测试覆盖上更冷静。两者搭配是有互补性的——一个负责往前推进,一个负责往后看。
这个 skill 案例其实把这个直觉做了产品化。原帖作者也提了一句:"如果使用其它子智能体 review 的话,可以把 skill 里面的 codex 替换一下"——也就是说这是个开放架构,谁审谁不是钉死的,按你对模型特性的理解来配。
这点很重要。多智能体协同这个概念过去两年被讲得太多,但落到工程实践里,大部分方案要么是把多个 Agent 串成 pipeline(缺乏弹性),要么搞成黑盒 supervisor 调度(不可控)。Codeg 这套 skill + MCP 的玩法走的是另一条路:协同关系由开发者自己用 skill 描述,谁该在什么时候被 delegate 出去,是配置出来的,不是黑魔法。
解决的真正痛点:人作为胶水的疲劳
用过 Claude Code 配合 Codex(或者反过来)的开发者大概都有过这个体感:
你在 Claude Code 里让它实现一个功能,它写完了,你不放心,复制 diff 到 Codex CLI 让它审;Codex 列了三条建议,你再复制回 Claude Code,让它针对这三条修;修完再 diff,再过 Codex……一两轮还行,三轮以上人就开始焦虑——上下文在两个工具之间断裂,你得不停地组织 prompt、贴文件路径、解释背景。
这个过程的本质是,人类成了 AI 之间的消息总线,而且是个高延迟、低带宽、容易出错的总线。
sub-agent-review-loop 这个 skill 把消息总线换成了 Codeg MCP。Claude Code 在自己的会话里直接通过 delegate_to_agent 把任务推给 Codex,Codex 跑完了把结论推回来,Claude Code 根据结论决定继续修还是收工。整个过程在一个会话上下文里完成,开发者只需要看最终结果。
原帖作者用了 "效率拉满" 四个字来形容这个变化,不夸张。从 "我得在两个终端窗口之间手动同步状态" 到 "我说一句话,两个 Agent 自己谈完了告诉我结果",这是质变。
Codeg 是什么:把分散的编码 Agent 收到一个工作区
稍微补一点 Codeg 本身的背景。这是个今年 4 月开始进入开发者视野的产品,定位是 企业级多智能体编程工作区——把 Claude Code、Codex CLI、Gemini CLI、OpenCode、Cline 这些本地 AI 编程工具的会话日志统一聚合到一个界面里,支持桌面应用、独立服务器和 Docker 三种部署。
它的几个能力跟今天这个 skill 案例直接相关:
- 多智能体会话聚合:自动从
~/.claude/projects、~/.cline/data/tasks这些路径摄取本地对话日志,结构化呈现历史交互。这意味着不同模型、不同 CLI 工具产生的痕迹是可被检索、可被 skill 利用的。 - MCP 与 skill 管理:内置 MCP 服务器扫描器和注册表,全局和项目级管理 skill。今天这个 review loop skill 就是直接通过 skill 管理面板加进去的。
- 并行 Git Worktree:同一项目同时跑多个分支,不同 Agent 部署到独立 worktree,避免 stash/checkout 互相打架。
- 远程聊天频道:通过 Telegram、Lark、iLink(微信) bridge 出去,可以在手机上看 Agent 跑到哪一步,需要批准敏感操作时直接在聊天窗口确认。
架构上是 Rust 核心(Tauri 2/Axum)+ React 19/Next.js 16 前端,数据走 SeaORM 落到本地 SQLite,本地优先。这套技术选型对开发者来说友好,意味着所有上下文都在你机器上,不会偷偷上云。
这类 skill 案例为什么值得追:可复制的工程范式
这次曝光的 review loop skill 之所以引发讨论,不只是因为它好用,更因为它揭示了一种 可被广泛复制的工程范式:
任何 "应该有人审一眼" 的环节都可以被 skill 化。
顺着这个思路往下推,开发者完全可以照葫芦画瓢写出一堆 skill:
- db-migration-guard:动到数据库迁移脚本时,自动 delegate 给另一个 Agent 检查向后兼容、锁表风险、回滚路径。
- security-review-loop:触发条件是改到认证、授权、加密相关代码,让一个专门提示词调教过的 Agent 过一遍 OWASP 清单。
- test-coverage-gate:写完功能后,让 reviewer Agent 检查测试是否覆盖了边界条件,没覆盖就要求补。
- doc-sync-check:API 改动后,自动检查相关文档是否需要更新,不一致就生成 diff 提示。
这些场景过去要么靠 CI 阶段的静态规则(粒度粗、误报多),要么靠人类 reviewer(注意力有限、易疲劳)。skill + 多 Agent delegation 给了第三个选项:在创作阶段就嵌入语义级的把关流程,由另一个独立模型实时执行。
几个值得提醒的点
当然,这套玩法不是没有代价。
Token 消耗会显著增加。 一次任务原本只需要 Claude Code 跑一遍,现在要 Claude Code 写、Codex 审、Claude Code 修、Codex 再审……review loop 跑三轮,token 至少翻三倍。如果用的是按调用计费的 API,账单会有感。
循环不收敛的风险。 skill 写的是 "Loop until production-ready",但万一两个 Agent 对什么算 production-ready 理解不一致,可能会陷入反复修改的死循环。生产实践里建议加一个 max iterations 的兜底(比如最多 5 轮,超过就要求人工介入)。
delegation 的载荷质量决定上限。 如果 Claude Code 传给 Codex 的 task 描述里漏了关键约束,Codex 的 review 就会跑偏。这个 skill 的设计已经强调了 "self-contained task",但实际效果取决于 Claude Code 当时对上下文的把握。
顺带一提,这种多模型协同的方式对 API 接入也提出了要求——你需要同时能调 Claude、Codex、Gemini 这些不同家的模型。OpenAI Hub 这类聚合平台一个 Key 调所有主流模型、兼容 OpenAI 格式、国内直连的特性,在这种场景下就比较合用,不用为了调 Codex 和 Claude 在两边各开一套账号管两套额度。
一个信号:AI 编程进入 "协议层" 阶段
往后看一步,今天这个 skill 案例其实在说一件更大的事:AI 编程工具的竞争重心,正在从单点模型能力转向协同协议层。
2024 年开发者关心的是哪个模型写代码更准。2025 年关心的是哪个 Agent 框架(Claude Code、Codex、Cursor)体验更好。到了 2026 年,很多人发现单一 Agent 的天花板就在那,真正能拉开生产力差距的,是这些 Agent 之间怎么协同——谁负责什么、什么时候 delegate 给谁、上下文怎么传递、结果怎么裁决。
MCP 协议在这一层提供了基础设施,Codeg 这类工作区在这一层提供了组织界面,skill 这种声明式描述在这一层提供了配置语法。当三者凑齐,多智能体协同从论文里的概念变成了开发者每天工程实践的一部分。
linux.do 这位开发者分享的 skill 看起来只是一个小 trick,但它示范了一个 "以后开发应该这么干" 的样本。复刻起来不难,下载 Codeg、配好 Claude Code 和 Codex、把 skill 贴进 skill 管理面板就行。值得花十分钟试一下。
参考来源
- 分享一个 Codeg 多智能体协同下的 skill 案例 - linux.do:原帖作者放出 sub-agent-review-loop 完整 skill 内容并对比效果差异,本文核心信息来源。