千问3.6-Plus杀入全球第二,国产代码模型的里程碑时刻

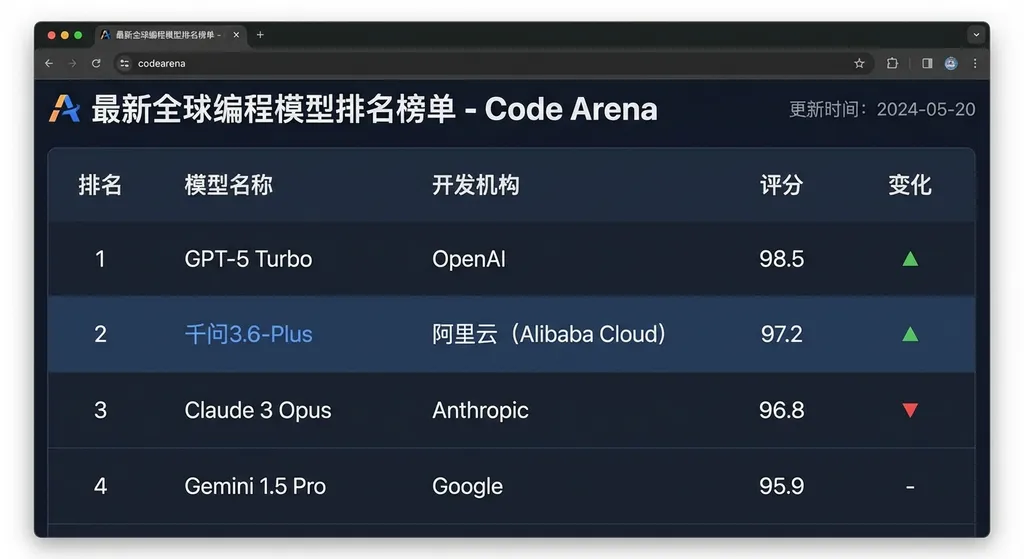
阿里千问3.6-Plus在全球权威编程盲测榜单Code Arena中拿下综合第二,仅次于Claude Opus 4.6,成为首个杀入该榜单前二的中国模型,标志着国产AI编程能力的关键突破。
千问3.6-Plus 登顶 Code Arena 全球第二:不是"接近",是真的打进去了
4月3日,全球知名大模型盲测平台 LMArena 旗下专注 AI 编程能力的 Code Arena 榜单更新了最新排名。阿里巴巴的 Qwen 3.6-Plus 拿下综合榜单全球第二,仅次于 Anthropic 的 Claude Opus 4.6。
排在它后面的,是 OpenAI、Google、xAI 这些名字。
这是国产大模型第一次在这个级别的全球编程盲测中杀入前二。不是中文编程榜,不是国内自建评测,是老外用户真刀真枪盲测投票出来的结果。
Code Arena 是什么?为什么这个榜单值得认真看?
先说背景。做开发的应该都知道 Chatbot Arena(现在叫 LMArena),它是目前业界公认最难"刷榜"的大模型评测体系——不靠跑分,靠真人盲测。两个模型匿名对战,用户不知道谁是谁,用完之后投票选更好的那个。ELO 评分体系,和国际象棋排名一个逻辑。
Code Arena 是它的编程专项分支,专门考察模型在真实编码场景下的表现。这里的"真实"不是刷 HumanEval 那种算法题,而是更贴近日常开发的任务:写业务逻辑、调试报错、重构代码、处理复杂的前端组件。
为什么说这个榜单比较靠谱?三个原因:
- 盲测机制杜绝了品牌效应。用户投票时不知道自己在用哪个模型,纯粹凭代码质量和交互体验判断。
- 样本量足够大。LMArena 累计投票数已经过百万量级,不是几十个评测样本能左右的。
- 没法针对性优化。不像固定 benchmark 可以"教模型做题",盲测的 prompt 来自真实用户,分布极其多样。
所以当千问 3.6-Plus 在这个榜单上拿到第二的时候,含金量是实打实的。
具体表现:React 专项榜单才是真正的硬仗
综合排名第二已经够亮眼了,但更值得关注的是 React 专项榜单的成绩。
Code Arena 下设多个细分方向,其中 React 专项被认为是目前 AI Coding 领域最前沿、挑战性最高的赛道。原因很直观——React 开发不是写个排序函数那么简单。它考察的是模型在真实复杂 Web 开发场景下的自主编码能力:
- 组件设计是否合理,状态管理是否清晰
- 能不能处理复杂的 props 传递和生命周期逻辑
- 样式、交互、数据流能不能一起搞定,而不是只会写半截
- 面对模糊需求时,能不能给出合理的架构决策
这些能力综合在一起,本质上考的是模型对"软件工程"的理解深度,而不仅仅是"会写代码"。
千问 3.6-Plus 在这个方向上同样斩获第二。对于一个国产模型来说,这个成绩放在一年前几乎不可想象。
从"能用"到"能打":国产编程模型的三级跳
把时间线拉长来看,国产模型在编程能力上的进化路径非常清晰。
第一阶段是"能跑通"。大概在 2024 年上半年,国产模型写代码还经常出现语法错误、逻辑混乱、上下文丢失等基础问题。让它写个完整的 CRUD 接口都费劲,更别提复杂业务逻辑了。那时候开发者的普遍感受是:国产模型聊天还行,写代码算了。
第二阶段是"能用"。2024 年下半年到 2025 年,以 DeepSeek Coder、千问 2.5-Coder 为代表,国产模型在编程任务上开始有了质的提升。简单到中等难度的编码任务基本能胜任,偶尔还能给出让人眼前一亮的解法。但跟 Claude、GPT-4 级别的模型比,在复杂推理、长上下文代码理解、架构设计等方面还有明显差距。
第三阶段就是现在——"能打"。千问 3.6-Plus 在 Code Arena 上的表现说明,国产模型在编程能力上已经不是"追赶者"的姿态了,而是真正有资格坐到牌桌上跟顶级选手掰手腕。
这个跨越的速度,说实话,比很多人预期的要快。
技术层面:千问 3.6 这一代做对了什么?
阿里没有公开千问 3.6 的完整技术细节,但从公开信息和实际使用体验来看,有几个方向上的改进比较明显。
首先是代码理解的深度。3.6 这一代在处理大型代码库时,对上下文的把握能力有了显著提升。举个例子,你给它一个几百行的 React 组件让它重构,它不再是机械地逐行改写,而是能理解组件之间的依赖关系,给出结构性的优化建议。这说明模型在训练阶段对代码的"语义理解"做了大量工作,而不仅仅是学会了语法模式。
其次是指令遵循的精确度。编程场景下,指令遵循比聊天场景重要得多。你说"只改这个函数,别动其他地方",模型就得严格执行。你说"用 TypeScript 写,不要 any",它就不能偷懒。3.6-Plus 在这方面的表现明显比上一代更稳定。
第三是多步推理能力。复杂的编程任务往往需要模型先理解需求、再拆解步骤、然后逐步实现、最后自查。这个链条上任何一环掉链子,最终输出的代码都会有问题。3.6-Plus 在多步推理上的改进,直接体现在它处理复杂任务时的"完成度"上——给出的代码更完整,需要人工修补的地方更少。
跟 Claude Opus 4.6 的差距在哪?
拿了第二,那跟第一名差多少?这个问题值得诚实地聊一聊。
Claude Opus 4.6 目前在 Code Arena 上的领先优势依然明显,尤其体现在几个方面:
一是超长代码的处理能力。当代码量超过几千行时,Claude 对上下文的保持能力仍然是业界天花板。千问 3.6-Plus 在中等长度的代码任务上已经非常接近,但在超长上下文场景下还有差距。
二是"代码品味"。这个词听起来有点玄,但做过开发的人都懂——同样是能跑的代码,有的写得优雅、可维护性强,有的就是能用但看着难受。Claude 在代码风格、命名规范、架构选择上的"品味",目前仍然是最好的。千问 3.6-Plus 在这方面进步很大,但还没到同一水平线。
三是边缘场景的鲁棒性。遇到不常见的框架、冷门的 API、或者故意刁难的需求时,Claude 的容错能力更强。千问 3.6-Plus 在主流技术栈上表现出色,但在长尾场景下偶尔会"露怯"。
不过话说回来,能跟 Claude Opus 4.6 放在一起比较本身就说明了问题。半年前,这个对话根本不会发生。
对开发者意味着什么?
说点实际的。
如果你是日常使用 AI 辅助编程的开发者,千问 3.6-Plus 进入全球第二梯队意味着你多了一个靠谱的选择。尤其是以下几个场景:
对中文语境的理解天然更好。写代码虽然是英文,但需求描述、注释、文档往往是中文。国产模型在理解中文技术需求时的准确度,确实比海外模型更有优势。你不用费劲把需求翻译成英文再喂给模型。
性价比可能更优。虽然具体定价还要看各平台的策略,但国产模型在 API 调用成本上通常比同级别的海外模型更有竞争力。对于需要大量调用编程模型的团队来说,这是个实实在在的考量。
延迟更低。如果你的服务器在国内,调用千问的 API 响应速度天然比调用海外模型快。编程辅助场景下,几百毫秒的延迟差异在高频交互时体感非常明显。
如果你想快速试试千问 3.6-Plus 的编程能力,通过 OpenAI Hub 可以直接用兼容 OpenAI 格式的接口调用,不用单独对接阿里的 SDK。一个简单的示例:
from openai import OpenAI
client = OpenAI(
api_key="你的 OpenAI Hub API Key",
base_url="https://api.openai-hub.com/v1"
)
response = client.chat.completions.create(
model="qwen-3.6-plus",
messages=[
{
"role": "system",
"content": "你是一个资深全栈工程师,擅长 React 和 TypeScript。"
},
{
"role": "user",
"content": "帮我写一个带虚拟滚动的 Table 组件,要求支持列排序、固定列和自定义单元格渲染。用 TypeScript,不要 any。"
}
],
temperature=0.2,
max_tokens=4096
)
print(response.choices[0].message.content)
// Node.js / TypeScript 版本
import OpenAI from 'openai';
const client = new OpenAI({
apiKey: '你的 OpenAI Hub API Key',
baseURL: 'https://api.openai-hub.com/v1',
});
const response = await client.chat.completions.create({
model: 'qwen-3.6-plus',
messages: [
{
role: 'system',
content: '你是一个资深全栈工程师,擅长 React 和 TypeScript。',
},
{
role: 'user',
content:
'重构这段代码,把状态管理从 useState 迁移到 Zustand,保持类型安全。',
},
],
temperature: 0.2,
});
console.log(response.choices[0].message.content);
接口格式完全兼容 OpenAI SDK,切换模型只需要改 model 参数,Claude、GPT、Gemini、DeepSeek 都能用同一套代码调。
更大的图景:OpenRouter 登顶与 Code Arena 第二
值得一提的是,千问 3.6-Plus 最近还登上了 OpenRouter 全球模型调用量排行榜的榜首。OpenRouter 是全球最大的 AI 大模型 API 聚合平台,Claude、GPT、千问、DeepSeek、GLM 等主流模型都在上面提供服务。
调用量第一意味着什么?意味着全球开发者在"用脚投票"。不是评测机构说你好,是真金白银的 API 调用量说你好。
把这两件事放在一起看:Code Arena 盲测第二证明了能力上限,OpenRouter 调用量第一证明了实际采用度。一个是"能打",一个是"有人用"。两个维度同时突破,这在国产模型历史上是第一次。
这也从侧面反映了一个趋势:全球开发者对模型的选择正在变得更加务实。品牌光环在消退,实际效果在说话。当千问在盲测中能打出跟 Claude 接近的水平、同时价格更有竞争力时,开发者的选择是很自然的。
冷静看:一次排名不等于全面超越
最后说几句不那么兴奋的话。
Code Arena 的排名是动态的。模型在持续迭代,今天的第二不代表永远的第二。OpenAI 的下一代模型、Google 的 Gemini 系列、xAI 的 Grok 都在快速演进。这是一场没有终点的竞赛。
而且,榜单成绩和实际生产环境的表现之间,永远存在一个 gap。Code Arena 的测试场景再真实,也无法完全覆盖企业级开发中遇到的各种复杂情况:遗留代码的维护、多人协作的代码风格统一、跟 CI/CD 流程的集成等等。
另外,编程模型的竞争已经不仅仅是"模型本身"的竞争了。IDE 集成体验、Agent 能力、工具链生态,这些"模型之外"的东西越来越重要。Cursor、Windsurf、GitHub Copilot 这些产品的竞争力,很大程度上来自于它们把模型能力包装成了顺滑的开发体验。千问要把 Code Arena 上的成绩转化为开发者的日常生产力,还需要在工具链层面下更多功夫。
但无论如何,千问 3.6-Plus 在 Code Arena 上的这个第二名,是一个值得记录的节点。它证明了国产模型在最硬核的编程能力评测中,已经具备了全球顶级的竞争力。
接下来的问题是:这个位置能守多久,以及能不能更进一步。
参考来源
- 自立自强再落一子:中国AI编程能力实现重要跨越 — 百度百家号,关于千问3.6-Plus在CodeArena登顶国产最强编程模型的综合报道
- 阿里千问3.6Plus大模型登顶全球模型调用排行榜首 — 百度百家号,关于千问3.6-Plus在OpenRouter调用量登顶的报道
- 全球权威大模型盲测榜单公布,阿里千问3.6登顶中国最强编程模型 — 百度百家号,Code Arena榜单详细排名及React专项成绩分析
- 全球权威大模型盲测榜单公布 阿里千问3.6登顶中国最强编程模型 — 财联社报道,4月3日榜单更新的即时消息
- 阿里千问3.6-Plus登顶Code Arena中国最强编程模型 — 东方财富网,React专项榜单技术方向解读
- 全球权威大模型盲测榜单公布 阿里千问3.6登顶中国最强编程模型 — 同花顺财经,榜单排名及行业影响分析
