微软 MAI-Image-2.5 冲上 Arena 第三:文字渲染和商业化能力双突破
微软研究院昨天(5 月 26 日)发布了 MAI-Image-2.5,这是其自研图像生成系列的最新版本。发布当天,该模型在 Arena 文生图榜单上升至第 3 名,仅次于 Google Gemini 3.1 Flash 和 OpenAI GPT Image 1.5。这是微软在图像生成领域的又一次发力,也标志着其自研模型能力已经接近行业顶尖水平。
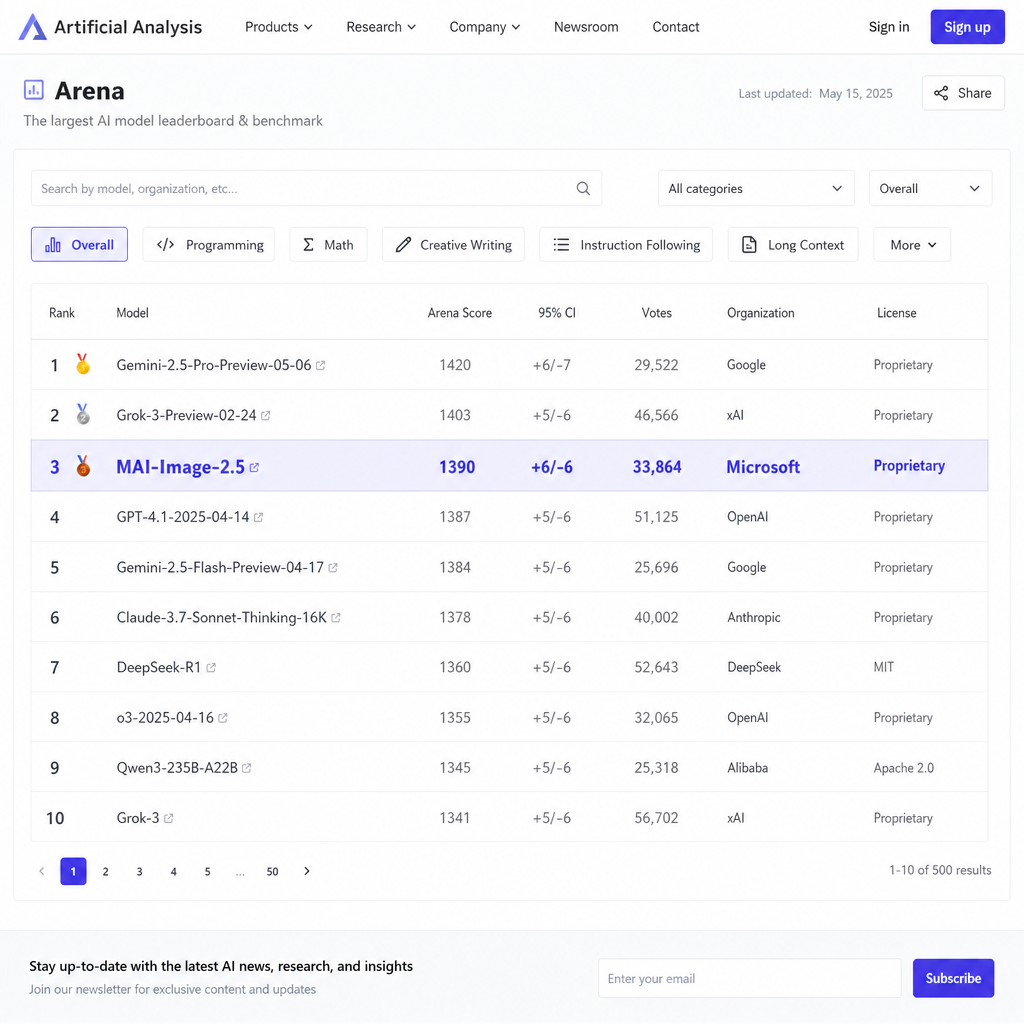
从依赖 OpenAI 到自研登顶前三
一年前,微软的 Bing Image Creator 和 Copilot 几乎完全依赖 OpenAI 的 DALL-E 3 和 GPT-4o 来生成图像。去年 5 月,微软发布了第一代 MAI-Image,这是其首个完全自研的图像生成模型,并开始在产品中与 OpenAI 模型并行使用。
现在,MAI-Image-2.5 的发布意味着微软不仅摆脱了对外部模型的依赖,还在技术能力上追平了竞争对手。Arena 榜单是目前业内最权威的文生图模型评测平台之一,采用人类评分员的盲测对比方式,能够较为客观地反映模型的实际表现。MAI-Image-2.5 能够挤进前三,说明其在图像质量、指令理解和细节表现上已经达到了商业级水准。
核心升级:文字渲染不再是短板
相比前代 MAI-Image-2,MAI-Image-2.5 最显著的提升是文字渲染能力。这一直是图像生成模型的老大难问题——大多数模型在生成包含文字的图像时,要么字体扭曲变形,要么拼写错误,要么干脆无法准确呈现用户指定的文本内容。
MAI-Image-2.5 针对这一痛点做了专项优化。微软表示,该模型现在可以胜任信息图、海报、产品包装、标签等需要准确呈现文字的任务。这意味着设计师和营销人员可以直接用它生成带有品牌名称、产品说明、价格标签的视觉素材,而不需要在后期用 Photoshop 手动添加文字。
这个能力的商业价值不言而喻。电商平台的商品主图、社交媒体的宣传海报、线下活动的物料设计,这些场景都需要大量带文字的图像。如果 AI 能够一次性生成可用的成品,而不是只能提供一个需要二次加工的半成品,那么整个内容生产流程的效率会有质的提升。
商业场景打磨:不只是好看,还要能用
微软在博文中特别强调 MAI-Image-2.5 是"更接近可商用"的模型。这个表述很微妙——不是说"可以商用",而是"更接近"。这说明微软对模型的定位很清醒:它已经足够好,但还没到可以完全替代人类设计师的程度。
从实际能力来看,MAI-Image-2.5 在以下几个商业场景做了针对性优化:
品牌视觉与产品展示
模型在生成品牌相关图像时,对风格一致性、色彩搭配、构图平衡的把控更加成熟。这对于需要维护品牌调性的企业来说很重要——你不希望 AI 生成的图像每次风格都不一样,或者色调偏离品牌规范。
风格化插画
相比写实风格,插画对创意和风格化表达的要求更高。MAI-Image-2.5 在这方面的表现比前代更稳定,能够更准确地理解用户对风格的描述(比如"扁平化设计"、"赛博朋克风格"、"水彩插画"),并生成符合预期的结果。
商业物料
无论是 PPT 配图、宣传册插图,还是网站 Banner,MAI-Image-2.5 生成的图像在完成度和精致度上都有明显提升。微软提到模型的"画面完成度更高",这意味着生成的图像不再需要大量后期调整就能直接使用。
视觉推理能力:理解场景,而不只是拼凑元素
微软特别提到了 MAI-Image-2.5 的视觉推理能力。这是一个容易被忽视但非常关键的指标。
早期的图像生成模型往往只是把用户描述的元素堆砌在一起,但对这些元素之间的空间关系、物理逻辑、光照一致性缺乏理解。比如你让它生成"一个人站在树下",它可能会把人画得比树还大,或者人的影子方向和树的影子方向不一致。
MAI-Image-2.5 在这方面有明显改进。微软表示,模型在物体、场景结构、光照、比例以及空间关系等方面表现更强。这意味着即使用户给出的描述比较简单,模型也能自动补全合理的细节,生成结构完整、逻辑连贯的图像。
举个例子,如果你输入"一个咖啡杯放在木桌上,旁边有一本打开的书",模型不仅要画出这三个物体,还要理解:
- 咖啡杯应该是竖直放置的,不能倾斜
- 书是打开的,所以应该有两页可见
- 桌子的材质是木头,所以表面应该有木纹
- 光源从某个方向照射,三个物体的阴影方向应该一致
- 咖啡杯和书的比例应该符合现实
这些细节用户不会在提示词里明确说明,但模型需要自己推理出来。MAI-Image-2.5 在这方面的能力提升,意味着用户可以用更自然、更简洁的语言描述需求,而不需要像写代码一样精确地指定每一个细节。
落地节奏:Arena 已上线,两周内进入 MAI Playground
目前,用户已经可以在 Arena 平台上体验 MAI-Image-2.5。Arena 是一个开放的模型评测平台,用户可以在不知道模型名称的情况下对比不同模型的生成结果,然后投票选出更好的那个。这种盲测机制能够避免品牌效应的干扰,让评测结果更加客观。
微软表示,MAI-Image-2.5 将在未来两周内上线 MAI Playground 和 Foundry。MAI Playground 是微软提供的图像生成体验平台,类似于 OpenAI 的 DALL-E 网页版。Foundry 则是微软的 AI 模型部署平台,企业用户可以通过 Foundry 将 MAI-Image-2.5 集成到自己的应用中。
值得注意的是,微软并没有提到 MAI-Image-2.5 何时会进入 Copilot 和 Bing Image Creator。考虑到这两个产品的用户量巨大,微软可能会先在小范围平台上测试稳定性,然后再逐步推广到主流产品中。
竞争格局:微软、Google、OpenAI 三足鼎立
从 Arena 榜单来看,目前图像生成领域的第一梯队只有三家:Google、OpenAI 和微软。
Google Gemini 3.1 Flash 排名第一,这是 Google 在多模态能力上的集中体现。Gemini 系列本身就是一个统一的多模态模型,图像生成只是其能力的一部分。Google 的优势在于数据积累和基础设施——YouTube、Google Photos、Google Search 提供了海量的图像数据,这是其他公司难以匹敌的。
OpenAI GPT Image 1.5 排名第二。OpenAI 在图像生成领域起步最早,DALL-E 系列一直是行业标杆。GPT Image 1.5 是 OpenAI 将图像生成能力整合进 GPT 系列的最新尝试,用户可以在对话中直接生成图像,而不需要切换到单独的工具。
微软 MAI-Image-2.5 排名第三,但考虑到它是微软完全自研的模型,这个成绩已经相当不错。微软的优势在于产品整合能力——Copilot、Bing、Office 365、Azure 构成了一个庞大的生态系统,MAI-Image-2.5 可以无缝嵌入到这些产品中,触达数亿用户。
其他玩家,比如 Midjourney、Stable Diffusion、Adobe Firefly,虽然在特定场景下表现出色,但在综合能力和商业化落地上还有差距。Midjourney 的艺术风格化能力很强,但在文字渲染和商业场景上不如 MAI-Image-2.5。Stable Diffusion 是开源模型,灵活性高,但需要用户自己调参和部署,门槛较高。Adobe Firefly 专注于创意工作流,但模型能力本身并不突出。
技术路线猜测:扩散模型 + 强化学习?
微软没有公开 MAI-Image-2.5 的技术细节,但从能力表现来看,可以做一些合理推测。
首先,模型大概率基于扩散模型(Diffusion Model)架构。这是目前图像生成领域的主流技术路线,DALL-E 3、Stable Diffusion、Midjourney 都采用了类似的架构。扩散模型的优势在于生成质量高、可控性强,缺点是推理速度慢、计算成本高。
其次,文字渲染能力的提升可能来自两个方向:
- 专门的文字渲染模块:在扩散模型的基础上,增加一个专门处理文字的子网络,负责识别用户指定的文本内容,并在生成过程中精确控制文字的位置、字体、大小。
- 更强的指令理解能力:通过强化学习或人类反馈(RLHF)训练,让模型更准确地理解用户对文字的要求。比如用户说"在左上角写上'50% OFF'",模型需要理解"左上角"的空间位置、"50% OFF"的具体内容、以及这段文字应该醒目突出。
第三,视觉推理能力的提升可能得益于更大规模的预训练数据和更强的多模态对齐。微软在 GPT-4o 和 Copilot 的开发过程中积累了大量图像-文本配对数据,这些数据可以用来训练 MAI-Image-2.5,让它更好地理解图像中的物理规律和空间关系。
商业化前景:企业市场是关键
微软对 MAI-Image-2.5 的定位是"更接近可商用",这说明它的目标用户不是普通消费者,而是企业客户。
对于企业来说,图像生成 AI 的价值不在于生成几张好看的图片,而在于能否融入现有的工作流程,提升整体效率。MAI-Image-2.5 在文字渲染、品牌视觉、商业物料等方面的优化,都是围绕企业需求展开的。
微软的优势在于它已经有了一个成熟的企业服务体系。通过 Azure 和 Foundry,企业可以快速部署 MAI-Image-2.5,并将其集成到自己的应用中。通过 Copilot,企业员工可以在日常工作中直接使用图像生成能力,而不需要学习新的工具。
相比之下,OpenAI 和 Google 在企业市场的布局相对薄弱。OpenAI 的主要产品是 ChatGPT 和 API,缺乏像 Office 365 这样的企业级应用入口。Google 虽然有 Workspace,但在企业市场的份额远不如微软。
如果 MAI-Image-2.5 能够在企业市场站稳脚跟,微软在 AI 领域的竞争力将进一步增强。图像生成只是一个切入点,背后是整个多模态 AI 能力的较量。
开发者视角:API 何时开放?
目前,微软还没有公布 MAI-Image-2.5 的 API 开放计划。对于开发者来说,这是一个关键问题——如果只能通过 Copilot 或 Bing Image Creator 使用,那么应用场景会受到很大限制。
参考 MAI-Image-2 的发布节奏,微软可能会先在 Azure Foundry 上提供企业级 API,然后再考虑是否开放公共 API。企业级 API 的定价通常较高,但提供更好的 SLA 保障和技术支持。公共 API 的定价会更灵活,但可能有调用频率限制。
如果 MAI-Image-2.5 的 API 最终开放,它将与 OpenAI 的 DALL-E API、Google 的 Imagen API 形成直接竞争。微软的优势在于价格和生态整合,劣势在于品牌认知度——在开发者社区,OpenAI 的影响力仍然更大。
未来展望:多模态统一模型是终局?
从行业趋势来看,图像生成模型正在从单一功能工具向多模态统一模型演进。
OpenAI 的 GPT-4o 和 Google 的 Gemini 都是多模态模型,可以同时处理文本、图像、音频、视频。用户可以在一个对话中完成"理解图像 → 生成文本 → 生成新图像"的完整流程,而不需要在不同工具之间切换。
微软的 MAI-Image-2.5 目前还是一个专门的图像生成模型,但未来很可能会整合进更大的多模态系统中。微软已经在 Copilot 中展示了多模态能力的雏形——用户可以上传图像让 Copilot 分析,也可以让 Copilot 生成图像。MAI-Image-2.5 的发布,意味着 Copilot 的图像生成能力将进一步增强。
长期来看,图像生成 AI 的竞争不会停留在"谁生成的图片更好看"这个层面,而是会转向"谁能提供更完整的多模态解决方案"。微软、Google、OpenAI 都在朝这个方向努力,而 MAI-Image-2.5 只是微软在这条路上迈出的一步。
小结
MAI-Image-2.5 的发布标志着微软在图像生成领域的自研能力已经达到了行业顶尖水平。从依赖 OpenAI 到自研登顶前三,微软只用了一年时间。
模型在文字渲染、商业场景、视觉推理等方面的提升,都是围绕"可商用"这个核心目标展开的。微软的策略很明确:不追求艺术性和创意性的极致,而是专注于企业客户的实际需求,让 AI 真正融入工作流程。
接下来两周,MAI-Image-2.5 将上线 MAI Playground 和 Foundry,届时我们可以更直观地体验它的实际能力。如果表现符合预期,微软在企业 AI 市场的竞争力将进一步增强。
对于开发者来说,更关键的问题是 API 何时开放、定价如何、以及能否与现有的 Azure 服务无缝集成。这些问题的答案,将决定 MAI-Image-2.5 能否真正成为一个被广泛采用的商业级图像生成解决方案。