漏洞挖掘的下一个分水岭:让Agent自己把PoC也写了
5 月底,arXiv 上挂出的一篇论文在安全圈悄悄刷屏——FuzzingBrain V2,一个面向自动化漏洞发现与复现的多智能体 LLM 系统。这并不是又一个"LLM 帮你写 fuzz harness"的小修小补,而是把"挖洞"和"复现"这两件历来割裂的事,用 Agent 协作的方式接到了一条流水线上。
用一句话总结作者要回答的问题:能不能让 LLM 多智能体在大型 C/C++ 项目里既挖出深层漏洞、又同时吐出一个能跑起来的 PoC 输入,而不是甩出一堆"看起来像漏洞"的报告让人工再花一周去验证?
这件事过去几年没人解决好,是因为它确实难。看完论文再对照过去半年业界的相关工作,这次的方案值得展开讲讲。
为什么这事在 2026 年才被认真做出来
回头梳理一下自动化漏洞挖掘的范式跃迁,你会发现 FuzzingBrain V2 站在的位置并不偶然。
- 2022 年之前:传统 fuzzing 主导。AFL、libFuzzer、syzkaller 解决的是"输入空间爆炸"的问题,但对深层逻辑漏洞基本无能为力,且高度依赖人工写 harness。
- 2023 年:Google OSS-Fuzz 的 AI-Powered Fuzzing 第一次把 LLM 嵌进 fuzzing 流程,让模型生成 fuzz target。这一年 LLM 的角色是"增强工具",不是"替代工具"。
- 2024 年:Claude 3.5、LangGraph 之后 Agent 工程化成熟。OSS-Fuzz 的 Leveling Up Fuzzing 在 272 个 C/C++ 项目里靠 LLM agent 生成 harness、自动修编译错误,最终从 OpenSSL 里挖出了埋了二十年的 CVE‑2024‑9143。这是 Agent 真正开始打出战绩的拐点。
- 2025 年:Anthropic 推出 Automated Security Reviews with Claude Code,SCONE-bench 用来评估智能合约场景的 agent 能力;腾讯 atum 团队公布在主流开源仓库年挖 60+ 真实漏洞、过半高危的成绩。
这条曲线非常清楚:LLM 不再是辅助工具,而开始接管"决策"层。但即便如此,绝大多数系统仍止步于"报告漏洞",没有去交付一份能跑的 PoC。而在工业界,没有 PoC 的漏洞报告几乎等于没报告——SRE 不会信、产品不会修、CVE 评审也很难给高分。
FuzzingBrain V2 的价值,就在于明确把"可复现"作为第一目标。
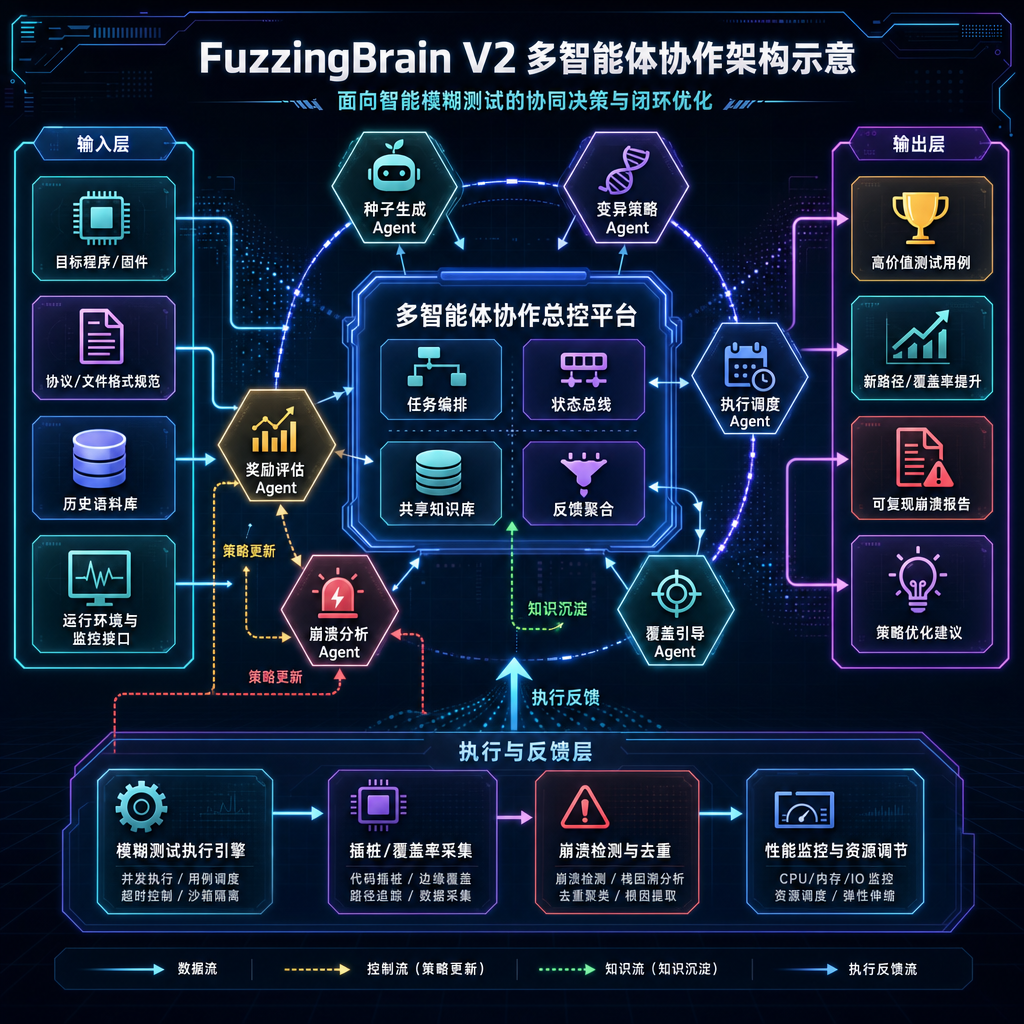
系统怎么搭的:分工大于通才
论文里最值得抄作业的设计哲学,是拒绝让一个超级 Agent 干所有事。这跟过去半年很多人用单 Agent + 长 prompt 硬怼漏洞挖掘的思路完全不一样。
大致的 Agent 分工可以梳理成几类:
- Recon Agent(侦察):负责吃下代码仓库,定位高风险区域。它做的事情更接近一个静态分析工程师——看 Makefile、看入口函数、识别哪些 parser、哪些 IPC 边界值得重点关照。
- Hypothesis Agent(假设):基于 Recon 的输出提出具体漏洞假设。比如"这个
parse_header()在长度字段 == 0 时可能整数下溢"。这一步是 LLM 做得最擅长的——结合上下文模式匹配 + 经验直觉。 - Harness Agent(构造):把假设翻译成可执行的 fuzz harness 或定向输入构造逻辑。这里复用了 OSS-Fuzz 那一脉积累的工程经验,包括自动修编译错误、自动找头文件依赖。
- Executor / Sanitizer Agent(执行与裁决):跑 fuzzing、跑 sanitizer(ASan/UBSan/MSan),从崩溃中区分真假阳性。
- Reproducer Agent(复现):拿到崩溃后,最小化输入、生成稳定可复现的 PoC,并附上调用栈、触发条件说明。
这套架构最关键的 insight 不是"多 Agent",而是用工具调用、消息传递把"模型的判断"和"工具的事实"清晰分开。LLM 负责猜,sanitizer 负责判,fuzzer 负责跑——每一步都有 ground truth 可以回灌。这才是 agentic 安全研究和"prompt 工程"的本质区别。
黑白盒的边界正在被抹掉
奇安信的安全团队在最近一篇技术分享里提到一个类似观察:MCP、RAG 这些工程化能力成熟后,黑盒和白盒分析的边界其实在被 Agent 模糊掉。FuzzingBrain V2 是个非常典型的例子——
- 它能像白盒工具一样读源码、做数据流推理;
- 又能像黑盒 fuzzer 一样疯狂打输入、看运行时反馈;
- 还能像安全研究员一样,看完崩溃日志反过来修正自己的假设。
过去做漏洞挖掘平台,工程师要决定"我这个项目要不要符号执行""要不要插桩""要不要先做污点分析"。现在 Agent 自己根据上下文决定要用哪个工具——这是 LLM Agent 在安全方向落地最值钱的部分。
几个值得划重点的细节
读论文的时候,有几个工程细节其实比"我们挖到了 N 个 CVE"更值得注意:
- 崩溃去重与归因。任何跑过 fuzzing 的人都知道,1 万个崩溃可能只对应 3 个真漏洞。FuzzingBrain V2 让 LLM 在去重时直接读 backtrace 语义,而不是简单 hash 调用栈顶几帧——这对宏多、inline 多的 C/C++ 项目特别有用。
- PoC 最小化是单独建模的。传统 delta debugging 在结构化输入(比如 protobuf、媒体格式)上效果一般,作者让一个专门的 Reproducer Agent 理解格式语义后做最小化,PoC 体积显著下降。
- 失败案例也被分析了。论文里没有回避 LLM 经常"幻觉漏洞"的现实,单独给出了哪些类别的漏洞 Agent 仍然搞不定,比如跨模块的并发竞争、长生命周期堆腐败——这部分坦诚得有点出乎意料。
跟同期工作怎么比
顺手对比一下今年看到的几个方向:
| 系统 / 工作 | 主要目标 | LLM 角色 | 是否产出可复现 PoC |
|---|---|---|---|
| OSS-Fuzz Leveling Up (2024) | 自动生成 harness | 单 Agent + 工具 | 部分 |
| IVAgent (看雪) | 二进制/源码混合漏洞挖掘 | 多分析引擎调度 | 部分 |
| Claude Code Security Review | 代码审计 | 审计员 | 否(偏报告) |
| FuzzingBrain V2 | 挖洞 + 复现一体 | 多 Agent 分工 | 是,且最小化 |
横向看下来,FuzzingBrain V2 不一定在某个单点指标上最强,但它是少数几个把"产出可验证的 PoC"作为硬指标的系统。这件事的工程价值,可能比刷 benchmark 还重要。
这套思路对开发者意味着什么
如果你在做的是普通业务开发,别误以为这跟你无关。两个方向值得关注:
- CI 里嵌入 Agent 化的安全审查会越来越普遍。不是"跑个 SAST 工具",而是有一个 Agent 在 PR 上下文里思考"这次改的 parser 改了边界处理逻辑,要不要顺手 fuzz 一下"。这种能力 2026 下半年大概率会进主流 DevSec 工具链。
- 漏洞情报会被反向打通。今天的 CVE 报告大多还是人类语言。当 PoC 能由 Agent 自动产出,下一步就是 CVE → 自动复现 → 自动定位 → 自动修复 patch 的全链路,把漏洞响应时间从天级压到小时级。
一点冷静的判断
要说不足,也得讲一句。Agent 系统的成本不便宜——FuzzingBrain V2 这种多 Agent + 长上下文 + 反复工具调用的流程,跑一个中型项目消耗的 token 量相当可观。这也是为什么这类工作目前更多在论文和大厂内部跑,普通团队短期内复现一套类似系统的门槛不低。
但方向已经非常清楚:漏洞挖掘正在从"工具 + 专家"过渡到"Agent + 工具 + 专家",专家在链条里的位置正在上移——从写 harness、调 fuzzer,变成定义目标、审查结论。这不是替代关系,是分工重排。
做模型选型时顺带说一句,多 Agent 安全研究这类场景对模型的代码理解、长上下文稳定性、工具调用准确率都很挑剔,Claude、GPT、Gemini、DeepSeek 在不同环节的优势并不一样,团队里同时备几个模型轮换跑实验是常态。OpenAI Hub 这类用一个 Key 就能同时调主流模型的聚合接口,对这种需要横向对比的研究和工程工作来说,能少踩很多账号和网络上的坑。
至于 LLM 多智能体能不能最终接管漏洞挖掘?看 2026 年下半年各家在真实开源仓库上交出的 CVE 战绩就知道了。
参考来源
- IVAgent - Multi-Agent 驱动的漏洞挖掘 Agent(看雪论坛):基于 LLM 的多分析引擎漏洞挖掘 Agent 实现,可与本文方案对照阅读。