一个让LLM接管ComfyUI的开源方案出现了
5月25日,linux.do上一个叫comfyui-good-anima的项目刷了屏。作者ShiroEirin的吐槽很直白:兄弟们玩Anima这个base模型半天,还在ComfyUI里手动拖节点连线,活像原始人。于是他干脆把自己用LLM全自动构图的整套skills开源了。
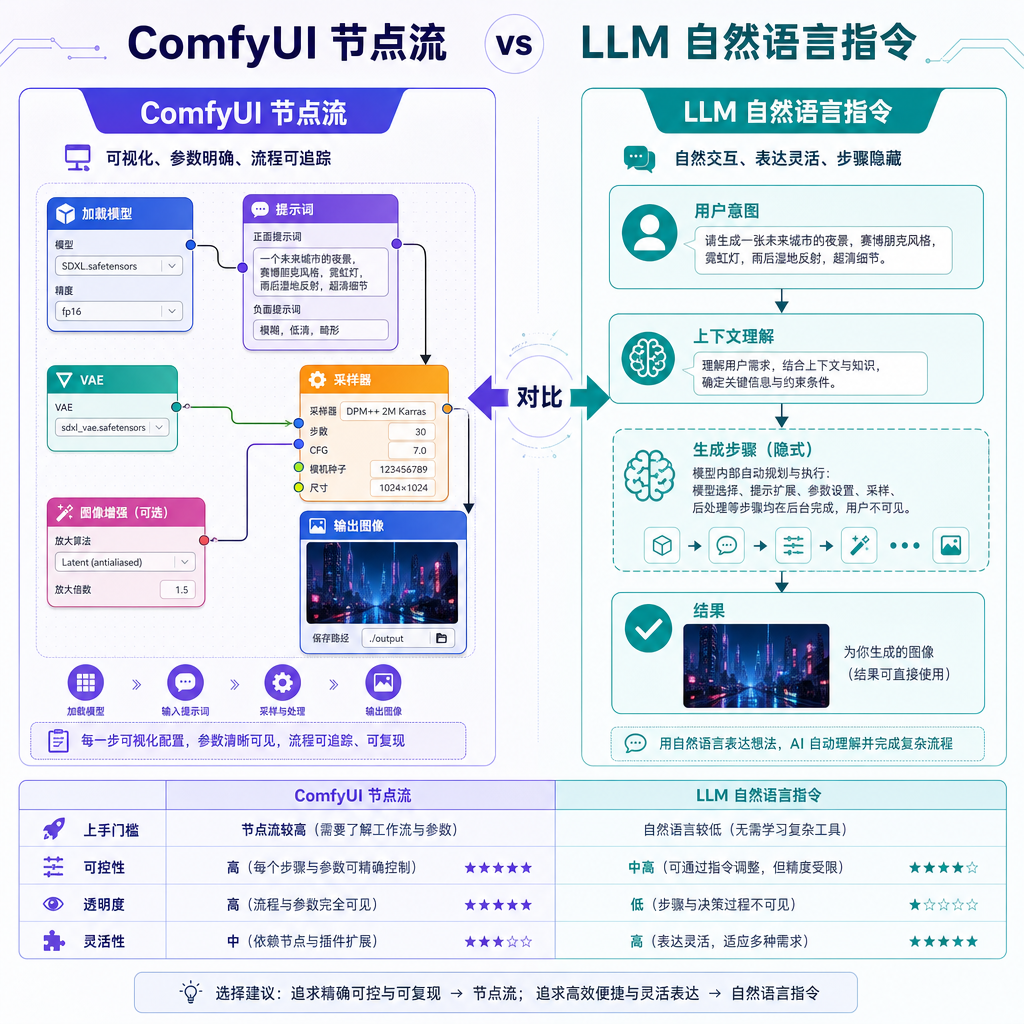
这事其实点中了AI绘画圈的一个长期痛点——ComfyUI的节点流是给工程师看的,不是给创作者看的。一张图从想法到出图,要在十几个节点之间来回调参,写prompt还得记一堆Danbooru tag的精确拼写,错一个字符就少一个特征。而LLM明明已经能理解"想画一个赛博朋克风格的少女站在霓虹街道上"这种自然语言,为什么还要让人去当中间的翻译层?
comfyui-good-anima给出的答案是:那就别让人当翻译了,让LLM直接调ComfyUI。
它到底做了什么
项目的定位很明确——这不是又一个ComfyUI插件,而是一套给AI助手(Snow、Claude Code、Codex这类Agent)用的Skill定义。LLM读完这套Skill的描述后,就能理解从构图到出图的完整流程,不需要用户手撸prompt,也不需要去碰ComfyUI的界面。
整套流程拆成四件事:
1. 构图规划
LLM拿到用户的需求后,先做的不是写tag,而是做导演该做的事:
- 画幅比例选择:竖构图还是横构图,9:16还是3:2,这取决于内容
- 镜头远近:full body、cowboy shot、upper body、portrait,每一种带来的信息密度完全不同
- 构图方式:三分法、对称、引导线、留白
- 光影方向:顺光、逆光、侧光、rim light
这一步是最容易被新手忽略的。多数人写prompt直接堆形容词和角色tag,最后出图永远是站桩正面照。把构图决策交给LLM意味着它会先想清楚"这张图要表达什么",再去想"用什么tag来实现"。
2. 标签检索
这是整套方案里最实用的部分。Danbooru的tag体系是出了名的反人类——角色名要用日文罗马音,画师tag的下划线和括号位置必须分毫不差,写错一个字符整个特征就消失了。
comfyui-good-anima做了个索引,LLM不是凭记忆瞎猜tag,而是去查索引拿到经过验证的有效tag。比如你说"画一个初音未来风格的角色",它会去查到hatsune_miku这个准确写法,而不是猜成hatsune miku或者miku_hatsune。画师风格同理,(artist_name)这种带括号的tag格式由索引保证正确。
这一步直接干掉了Anima使用者最大的一个学习曲线。
3. Prompt 组装
Anima作为一个基于Illustrious架构的anime base模型,对prompt有自己的偏好规范——质量tag放在哪、负向prompt怎么写、各部分的权重怎么分配。LLM按照官方推荐的模板把正向和负向prompt拼好,避免新手常见的"质量tag放反位置"、"负向prompt漏关键词"之类的坑。
4. 工作流执行
最后一步是真正调起ComfyUI。项目集成了出图、放大、缓存的完整pipeline,LLM通过ComfyUI的API直接提交任务,拿到结果。换句话说,用户从头到尾只需要说一句中文需求,剩下的所有事LLM都做了。
为什么选Anima
这里要稍微说一下Anima这个模型。它属于近一年来Illustrious生态里成长很快的二次元base模型,特点是对Danbooru tag的响应度高、角色还原准、画师风格能区分得很细。社区里玩得深的人都知道它潜力大,但也都知道它对prompt质量极度敏感——一个好tag和一个错tag出来的画面可能天差地别。
这也解释了为什么作者要做这套工具:模型越强,prompt门槛越高。如果不能把prompt工程交给LLM,这个模型的能力上限就被使用者的tag水平限制住了。
实际体验和工程思路
从代码组织上看,这个项目走的是Anthropic提倡的Skill(技能)模式——把领域知识、工具调用、流程编排打包成LLM可以理解和调用的单元。Claude Code、Codex这类编程Agent天然就支持这种模式,把Skill装上去,Agent就立刻获得了对应领域的专业能力。
对比之前社区里的方案,比如comfyui_LLM_party走的是"在ComfyUI里集成LLM节点"的思路,本质上还是要在ComfyUI里搭工作流,只是把LLM作为流程中的一个环节。而comfyui-good-anima反过来——让LLM成为主调度方,ComfyUI只是被调用的执行引擎。
这两种思路的区别在场景上体现得很明显:
- 前者适合那些已经有固定工作流、需要LLM在某个节点做文本处理的场景
- 后者适合"我有个想法,你给我出图"这种从0到1的创作场景
后者显然更接近大多数用户的真实使用习惯。
部署和使用
项目托管在GitHub上(ShiroEirin/comfyui-good-anima),安装思路大致是:
# 1. clone 仓库到你的 AI 助手 skills 目录
git clone https://github.com/ShiroEirin/comfyui-good-anima
# 2. 确保本地 ComfyUI 已经跑起来,并安装好 Anima 模型
# ComfyUI 默认 API 端口 8188
# 3. 让 Claude Code / Codex / Snow 加载这个 skill
# 具体方式取决于你用的是哪个 Agent
之后就可以直接对Agent说"画一张xxx",Agent会自己完成构图决策、查tag、组装prompt、调API、等结果、返回图片这一整套动作。
需要注意几个前置条件:
- 本地要有跑得动的ComfyUI:这个项目不解决算力问题,模型推理还是在本地或你自己的GPU服务器上跑
- 要装好Anima模型:项目针对Anima的prompt规范做了优化,换其他anime模型可能效果打折
- Agent要支持长上下文和工具调用:构图规划+tag检索会消耗一定的token,建议用Claude Sonnet/Opus或者GPT-4级别的模型来驱动,小模型可能hold不住整个流程
这套思路能延伸到哪
看这个项目,让人想到的不只是"AI画图变方便了"这件事,而是LLM作为工作流编排层这个更大的趋势。
过去两年里,ComfyUI、SD WebUI这类工具的复杂度一直在爆炸式增长——节点越来越多、参数越来越细、生态插件越来越分散。这是一种典型的"专家工具螺旋",强是真的强,但门槛也是真的高。LLM的出现给了另一条路:不是简化工具本身,而是在工具上面加一层语义抽象。
comfyui-good-anima证明了这条路在AI绘画领域是可行的。同样的思路完全可以复制到视频生成(Wan、Hunyuan的工作流同样复杂)、3D生成、音乐生成等任何被节点化工具统治的创作领域。可以预见接下来会有一波类似的Skill项目出现。
对于个人开发者来说,这也是一个值得参考的开源策略——不重复造轮子,而是给现有强大工具加一个LLM友好的接口层。投入产出比远高于自己从头写一个新的UI。
一些遗留问题
当然这套方案也不是完美的:
- 可控性是双刃剑:把构图决策交给LLM,意味着你失去了对每个细节的精确控制。专业插画师可能还是会觉得不够顺手
- Tag索引的维护成本:Danbooru每天都有新tag,画师也在不断更新,索引需要持续维护才能保持有效
- 多轮迭代的体验:生图本质是个反复调整的过程,目前这套Skill在"基于上一张图微调"的场景下还有优化空间
- 依赖具体Agent:Skill的实现方式跟Agent的能力强相关,换Agent可能需要重新适配
但这些都是工程问题,不是路线问题。作者在帖子里也提了,欢迎大家提issue。
对ComfyUI玩家来说,这是一个能立刻上手、立刻提升生产力的开源项目。对Agent开发者来说,这是一个值得拆开看看的Skill设计案例。
参考来源
- linux.do 原帖:【开源-comfyui-good-anima】一个让LLM帮你从提示词构图到最终调用comfyui的一整套解决方案 — 作者ShiroEirin的首发帖,包含项目介绍和讨论
- GitHub - ShiroEirin/comfyui-good-anima — 项目源码仓库,含Skill定义和使用文档
- GitHub - heshengtao/comfyui_LLM_party — 另一种思路的参考项目,把LLM作为ComfyUI内节点集成