阿里语音大模型杀进 Speech Arena 全球前五,三个赛道国内通吃
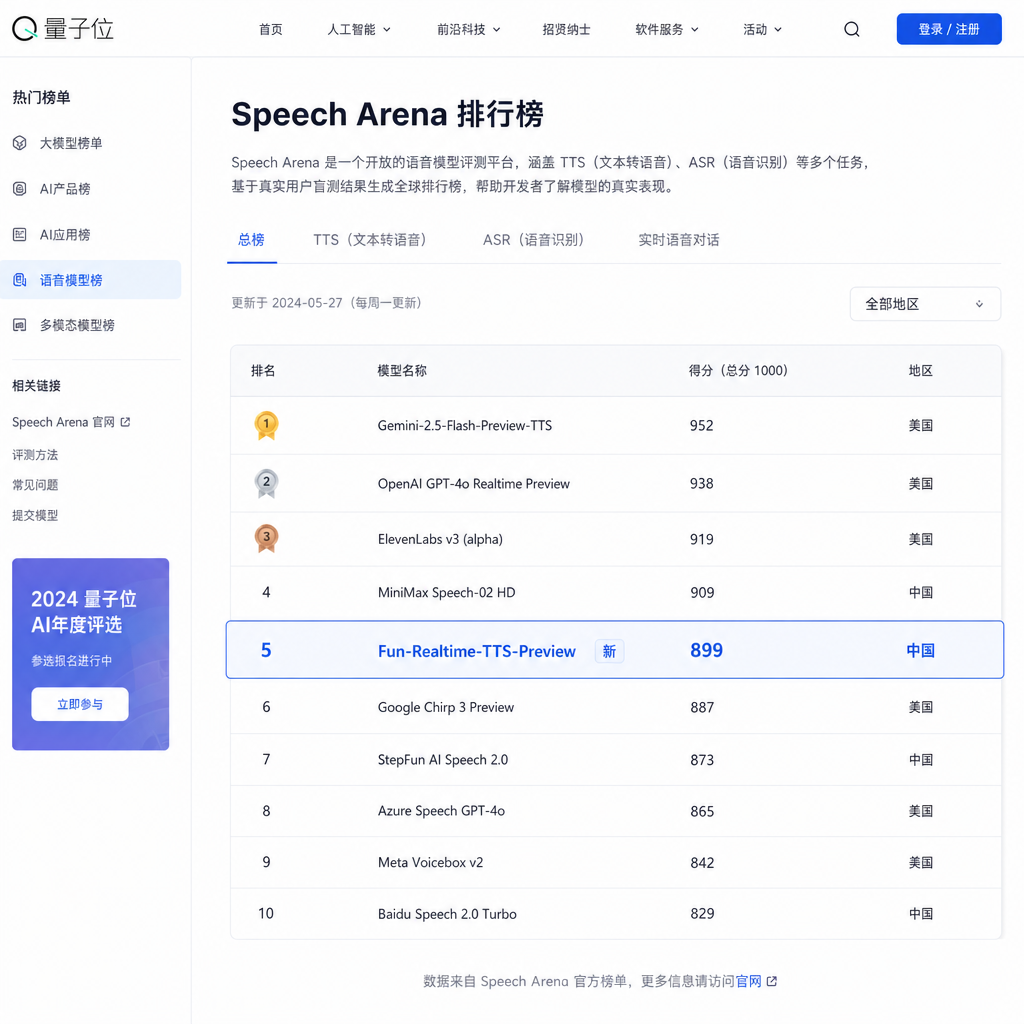
5 月 28 日,Artificial Analysis 的 Speech Arena 排行榜更新,阿里巴巴的语音大模型 Fun-Realtime-TTS-Preview 拿到 1190 分 Elo,全球第五、国产第一。同一份榜单上,ASR(语音转文字)、Chat(端到端语音对话)、TTS(文字转语音)三个子赛道,阿里都是国内第一。
这件事单看排名并不算惊天动地——前面还压着 OpenAI、ElevenLabs,以及不久前刚冲上 TTS 榜首的 MiniMax Speech-02-HD。但放在国内语音赛道的语境里看,意义不太一样:过去一年,国内做语音大模型的厂商里能在三个细分能力上同时进决赛圈的,几乎没有。阿里这次是一个模型把三件事都做了,而且没有明显的偏科。
Elo 1190 是什么水平
先解释一下榜单的玩法,免得数字看着没感觉。
Artificial Analysis 的 Speech Arena 走的是和 LMSYS Chatbot Arena 同一套思路——盲测加 Elo。用户在网页上输入一段文本或者上传一段音频,平台同时调两个模型生成结果,匿名展示,用户投票选哪个更好。所有投票汇总后用 Elo 算法滚动更新分数。
这种打分方式有几个特点:
- 不依赖某个固定测试集,所以很难靠刷题刷上去;
- 结果受用户偏好影响,自然语气、情感表达这些不太能被 WER(字错率)或 MOS(主观评分)量化的东西,会被放进总分;
- Elo 分差对应胜率,1190 vs 1100 大致意味着前者在盲测里赢的次数明显更多,不是统计噪声。
第一名通常在 1230 分上下,全球前五的分差不会拉得特别大。换句话说,阿里这个 1190 分,距离第一梯队不算远,但也确实还没摸到天花板。
Fun-Realtime-TTS-Preview 到底是什么模型
名字里的几个关键词得拆开看。
Fun 是阿里达摩院(现在更多挂在通义实验室名下)语音方向的一个长期家族,FunASR、FunAudioLLM、FunClip 这些都是这条线下出来的开源项目。在 GitHub 上 FunASR 的 star 数已经过了几万,国内做语音项目的开发者多半都集成过它的工具链。Fun-Realtime-TTS-Preview 可以理解为这条线最新的一个端到端语音大模型的预览版。
Realtime 这个词不是装饰。语音大模型这两年最大的工程难点其实不在音质,而在延迟——你要让用户在打断、抢话、即时反馈这种交互里感觉自然,端到端的首包延迟必须压到 300ms 以内,最好能到 200ms。OpenAI 去年 GPT-4o 在演示视频里展示的"打断后立刻接话"的效果,本质上就是为了打这个点。Fun-Realtime 走的是同样的路线。
TTS-Preview 这个后缀有点容易让人误会,看起来像是只做 TTS,但榜单显示它在 ASR 和 Chat 上也都拿了国内第一。比较合理的解读是:这是一个端到端的统一语音模型,TTS 是它对外发布的主入口,但底层架构同时承载了听、说、聊三种能力。这种"一个模型干完三件事"的路线,在工程上更接近 GPT-4o 的语音模式,而不是传统 ASR + LLM + TTS 三段式拼接。
三段式 vs 端到端,差在哪
这里值得多说两句,因为这是理解语音大模型当前格局的关键。
传统语音助手是这样的:
音频输入 → ASR 模型 → 文本 → LLM → 文本 → TTS 模型 → 音频输出
每一段都是独立模型,链路上累计的延迟、信息损失、错误传播都是问题。比如 ASR 把"那家店挺贵的吧"识别成"那家店挺贵的吗",语气从陈述变成了疑问,下游 LLM 的回答就会跑偏。又比如用户笑了一声、叹了口气,这些 paralinguistic 的信息在 ASR 输出文本时被完全丢掉了。
端到端的做法是把这条链路压扁:
音频输入 → 统一语音大模型 → 音频输出
模型内部直接处理 audio token,不再经过文本作为唯一中间表示。好处是延迟低、能保留情感和韵律信息、能输出带情绪的合成语音。代价是训练成本高、数据组织复杂、可控性比纯 TTS 差一些(比如想精确控制某个字怎么读,反而没有传统 SSML 那么直接)。
阿里这次在三个赛道都拿到国内第一,更值得关注的其实是 Chat 这一项——它代表端到端语音对话能力。能在这个项目上压住其他国产选手,说明 Fun-Realtime 不是把一个老 TTS 拿出来重新包装,而是真的把端到端这条路走通了。
国内语音赛道的几条路线
顺着说一下当前国内的格局,方便对比着看。
- MiniMax:Speech-02-HD 在 5 月初冲到了 Speech Arena 的 TTS 子榜单全球第一,主打音色还原和多语种。路线偏 TTS 优先,对话能力没有特别强调。
- 字节:豆包语音模型,强项在 C 端集成和实时对话延迟,但很少在第三方公开榜单上正面对比。
- 科大讯飞:星火语音,行业积累深,传统 ASR 仍然是国内最稳的之一,端到端方向跟进中。
- 阿里通义:这次的 Fun-Realtime-TTS-Preview,押的是统一架构 + 实时交互。
- 腾讯、百度:各自有混元和文心的语音线,但目前在 Speech Arena 这种全球榜单上的存在感不强。
MiniMax 拿 TTS 单项第一,阿里拿三项综合,两家走的不是同一条路。前者像是把单点做到极致,后者像是把整套能力打包成一个底座。从平台和 API 的角度看,后者更适合做开发者基础设施,前者更适合做内容生产工具。
对开发者意味着什么
如果你是做语音应用的开发者,这条新闻里有几个实际信号值得留意:
国产端到端语音模型开始有 production-ready 的选项了。 之前要做低延迟语音交互,大多数团队的选择是 OpenAI Realtime API,但海外服务的延迟、合规、成本都是麻烦。阿里这个模型如果能开放出稳定的 API,国内场景的可选项就多了一个。
Preview 版本意味着 API 接口和定价还在变。 不建议现在就把生产环境的语音链路切过来,但做 POC、做技术评估,现在是合适的时间点。
三段式架构在很多场景下仍然有性价比优势。 别看到端到端的榜单成绩就立刻把整套架构推倒重来。如果你的场景对延迟没那么敏感,或者需要在中间环节做敏感词、业务逻辑注入,三段式仍然更灵活。
评测榜单只是一个参考点。 Speech Arena 的盲测偏向"听起来自然",但你的业务可能更关心多轮对话稳定性、长音频处理、特定领域词汇识别准确率。建议自己拿真实场景的样本跑一遍。
顺带提一句,OpenAI Hub 这边的 API 聚合也在跟进语音类模型的接入,之前已经把 OpenAI 的 Realtime API 和几个主流 TTS 整合进同一套 OpenAI 格式的接口里。Fun-Realtime 这条线如果后续放出公开 API,按惯例也会做兼容。一个 Key 同时调通用对话模型和语音模型,对做语音 Agent 的团队会省不少胶水代码。
一个判断
阿里这次能进全球前五,技术上没有什么意外——FunAudioLLM、CosyVoice、SenseVoice 这些底子摆在那儿,迟早会出一个统一的端到端模型。比较有意思的是时间点:MiniMax 5 月初刚拿了 TTS 单项第一,阿里 5 月底就用一个综合三项第一回应。国内语音赛道的节奏在明显加速。
接下来值得关注的有两件事:一是 Fun-Realtime 什么时候转正、API 怎么定价;二是字节豆包语音会不会也走上公开榜单跟着卷。语音大模型这条线,过去一年一直被文本大模型的光芒盖住,但从端到端架构成熟、首包延迟突破 300ms 这两件事开始,2026 年很可能是它真正成为产品基础设施的一年。
参考来源
- MiniMax 新语音模型登顶 TTS 全球榜单解读 - 知乎:本月初 MiniMax Speech-02-HD 登顶 TTS 子榜单的背景报道,对照本次阿里成绩有参考意义。