Hugging Face 上又多了一个值得开发者收藏的数据集。Jasper AI 团队近日开源了 MONET——一个从 29 亿张原始图像中精炼出来的 1.049 亿条高质量图文配对数据集,Apache 2.0 协议,可商用,配套的论文、可视化工具、检索接口和 T2I 训练代码一并放出。
对于训练文生图模型的团队来说,这是过去半年里少有的、真正能拿来就用的大体量开源资产。
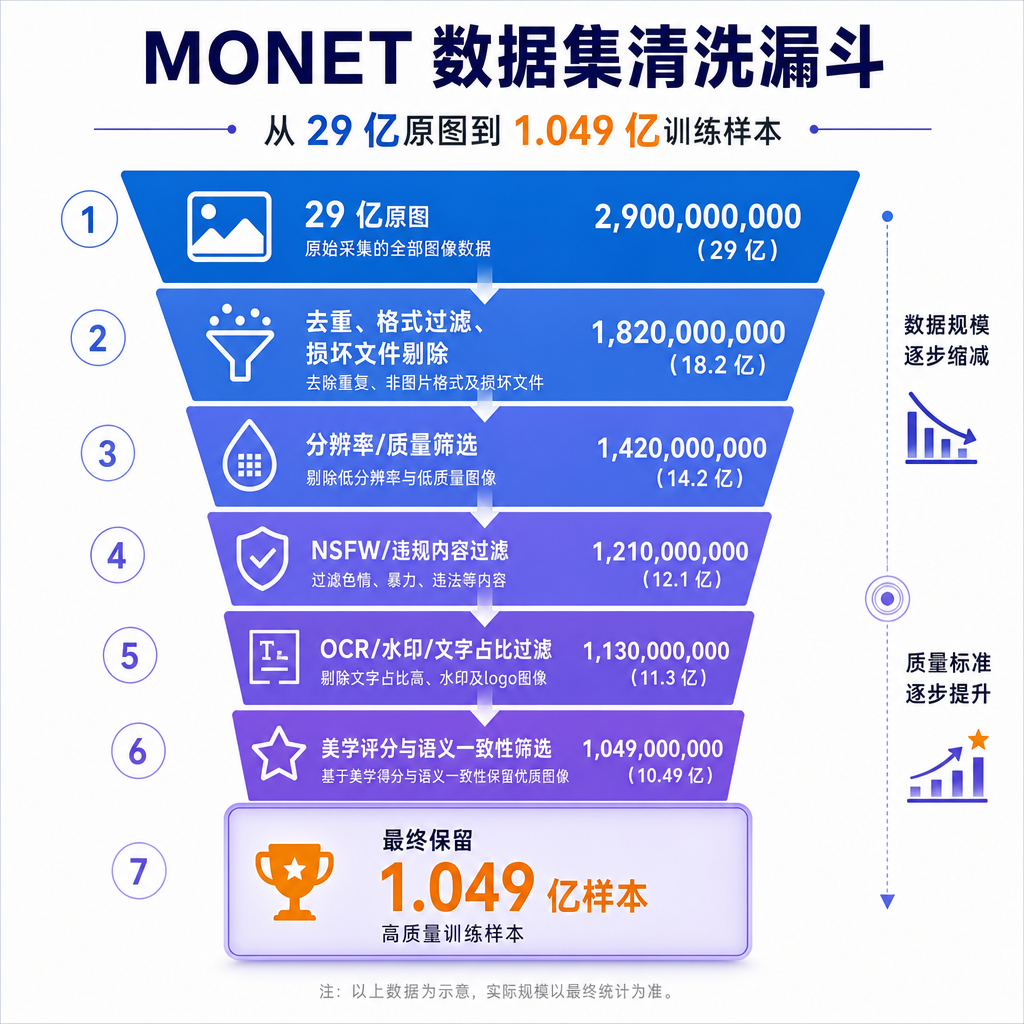
从 29 亿到 1 亿:MONET 的减法逻辑
MONET 的关键数字不是 1 亿,而是 29 亿到 1 亿这个比例——也就是约 96.4% 的原始数据被丢掉了。
这个减法比加法更有意思。过去几年开源多模态数据集的主旋律是堆规模:LAION-5B 喊出 58 亿对,MINT-1T 直接做到 1 万亿 token、34 亿图像,OBELICS 也有 3.53 亿图像。但训练过 SD、SDXL 或者自研 T2I 的人都清楚,这些数据集里能真正喂进模型的有效样本远没有标称数字那么夸张——水印、低分辨率、机翻 alt 文本、内容重复、aesthetic 分数偏低的样本占了相当比例,每个团队都要重新跑一遍清洗流水线。
MONET 做的事情,是把这个清洗工作前置并标准化。团队没有公布完整的过滤管线(这部分在论文里),但从数据集卡片来看,至少包含分辨率筛选、aesthetic 评分、caption 重写或重排、去重、安全过滤等几个标准步骤。最终留下的 1.049 亿条样本,每条都带 caption 和元数据,可以直接对接 diffusion 训练框架。
三个配套工具,把数据集变成可用的工程资产
MONET 区别于单纯放个 parquet 文件就跑路的开源做法,团队同时放出了三个配套项目,这一点值得圈点:
- UMAP 可视化:在二维空间里展示 1 亿样本的语义分布。这不是 demo 性质的玩具,对于挑选子集训练特定风格模型、判断数据偏态、定位长尾类别都有实际作用。
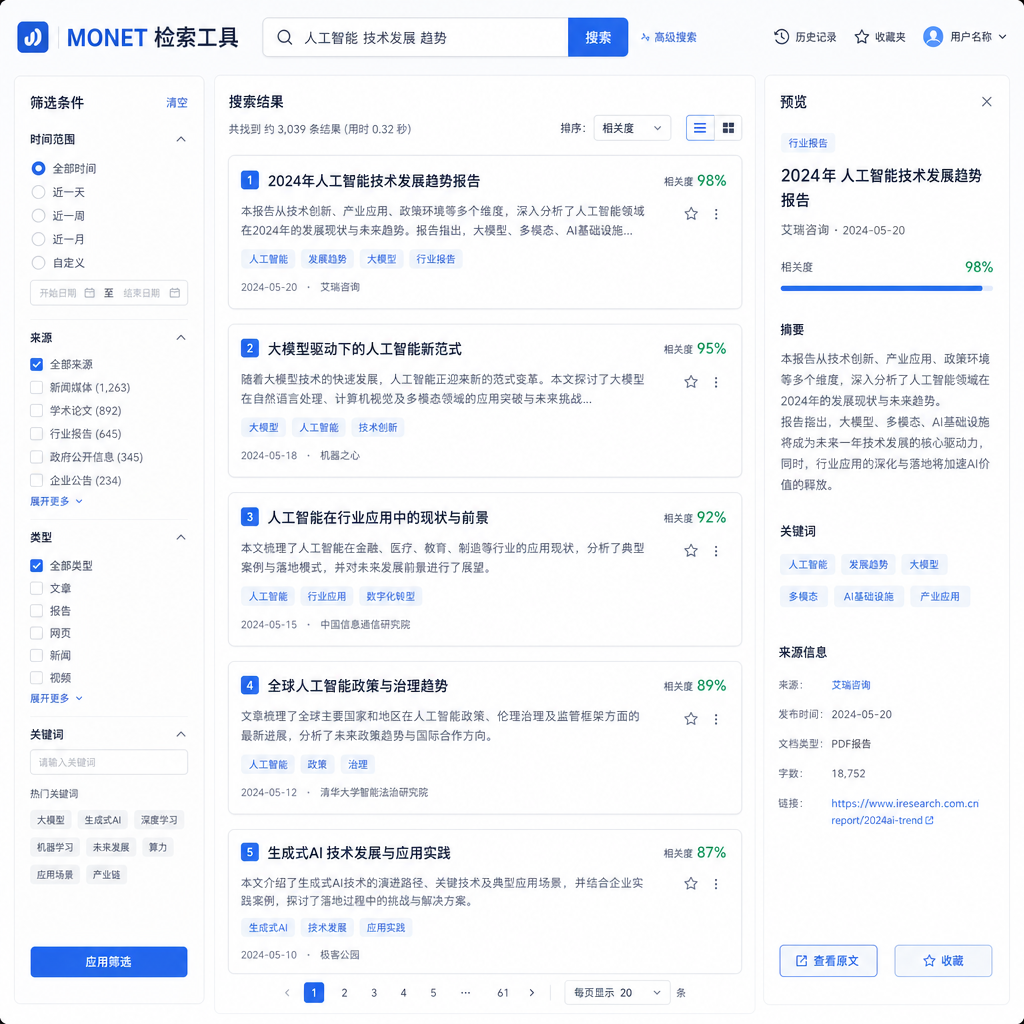
- 检索工具:支持文本和图像双向检索。换句话说,你可以输入一句 prompt 看看 MONET 里有哪些样本可能教坏模型,或者上传一张参考图找到风格相近的训练样本。这对于做风格微调和数据子集筛选是刚需。
- T2I 训练代码库:基于 MONET 训练文生图模型的完整代码。意味着小团队不用从零搭建 dataloader、损失函数和评估管线,可以直接 fork 跑通。
这套组合拳的意义在于,MONET 不只是个数据集,而是一个从数据到模型的最小可复现单元。对于研究者和创业团队来说,把入门门槛实打实地往下拉了一截。
横向对比:MONET 处在什么位置
把当前主流的开源图文数据集摊开看一遍:
| 数据集 | 规模 | 来源 | 协议 | 特点 |
|---|---|---|---|---|
| LAION-5B | 58 亿对 | Common Crawl | CC-BY 4.0 | 规模最大,但下架风波后获取困难,质量参差 |
| COYO-700M | 7.47 亿对 | Common Crawl | CC-BY 4.0 | Kakao Brain 出品,过滤较严 |
| DataComp-1B | 14 亿对 | Common Crawl | 多种 | 强调 benchmark 驱动的过滤 |
| OBELICS | 1.41 亿文档/3.53 亿图 | HTML | CC-BY 4.0 | 交错文本图像,HuggingFace M4 团队 |
| MINT-1T | 1 万亿 token/34 亿图 | HTML/PDF/ArXiv | 部分开放 | Salesforce,多模态交错 |
| MONET | 1.049 亿对 | 29 亿源池精炼 | Apache 2.0 | 高过滤比、配套工具齐全 |
MONET 在绝对规模上不算最大,甚至比 LAION-5B 小了一个数量级。但它的差异点在两个地方:
第一,Apache 2.0 协议。这是目前数据集里最宽松的开源协议之一,明确允许商用。相比之下,LAION 系列的 CC-BY 在商业使用上还有 attribution 要求,部分研究用数据集禁止商用。对于做产品的团队,这个差异直接决定了能不能用。
第二,高过滤比带来的训练效率。1 亿条高质量样本能跑出的效果,往往比 5 亿条混着噪声的样本更好——这一点在 SDXL、Pixart-α 等模型的训练经验里已经反复被验证。Pixart-α 当初就是用约 1000 万条精洗样本,做出了和当时主流模型可比的效果。MONET 这个量级,对于训练一个中等规模的 T2I 模型来说,已经相当充裕。
一个不那么明显的细节:caption 的质量
图文数据集的瓶颈,最近一两年早就从图像端转移到了文本端。
原因很简单:高分辨率图片好找,但匹配的高质量描述太稀缺了。网页上的 alt 文本要么是 SEO 关键词堆砌,要么是「IMG_2024.jpg」之类的废话。所以 DALL·E 3 当年用 GPT-4 重写 caption 那一下,被业内认为是它效果跃迁的关键。后来 Stable Diffusion 3、FLUX 都跟进了类似做法。
MONET 在数据集卡片里提到样本带 caption 和元数据,但没有明说 caption 是原始还是 VLM 重写。从清洗比例和团队背景推测,应该走了 VLM 重写或者至少经过质量评分筛选——否则 96% 的过滤率没法解释。这一点等论文出来可以重点看。
如果 caption 确实经过了 VLM 增强,那 MONET 的实际训练价值会比单看规模数字高得多。
对国内开发者意味着什么
几个具体的使用场景:
- 训练或微调 T2I 模型:MONET + 配套训练代码,是一个完整的入门套件。预算有限的团队完全可以用 MONET 的一个子集(比如按 UMAP 聚类抽样 1000 万条)训练一个领域化的小模型。
- 构建检索增强生成系统:1 亿条带 embedding 的图文对,本身就是一个不错的图像检索库,可以接到 RAG 流程里给图像生成提供参考。
- VLM 评估和微调:高质量 caption 数据对训练 Qwen-VL、LLaVA 这类视觉语言模型同样有价值,不只局限于 T2I。
- 学术研究的对照基线:Apache 2.0 协议加上完整工具链,做数据过滤、caption 质量、aesthetic 评分相关研究的论文,未来很可能会以 MONET 作为对比基线之一。
需要注意的是,1 亿张图的下载和存储不是小事。按平均每张 100KB 估算,完整数据集大约在 10TB 量级。HuggingFace 的 datasets 库支持流式加载,但实际训练时还是建议本地化或者放到对象存储里。
一些保留意见
几个观望点:
- 过滤标准的偏置:任何过滤都会引入偏置。aesthetic 评分筛选过的数据,会让模型倾向于生成「看起来美」的图像,对纪实、医学、工业等场景反而不利。MONET 的过滤是否考虑了多样性平衡,要等论文给出细节。
- 版权风险:从 29 亿张图过滤而来,源头大概率仍是网络爬取。Apache 2.0 是数据集本身的协议,不等于每张图片背后的版权问题都被豁免。做商业产品的团队最好自己再过一遍合规审查。
- 基准缺失:目前还没有看到基于 MONET 训练的对照模型和量化指标,「高质量」更多是团队的自我描述。等社区基于 MONET 跑出实际 FID/CLIP score 数据,才算真正立住。
写在最后
2026 年了,开源多模态数据集这件事情已经从「比谁大」进入「比谁干净、比谁好用」的阶段。MONET 不是最大的,但它把过滤比例、协议宽松度和工具链完整度这三件事一起做到位了,这在当前开源社区里并不多见。
对于正在做文生图、多模态预训练、视觉检索的团队,这个数据集值得花一个下午下载下来看看。
参考来源
- Reddit 原帖讨论 - 作者 dh7net 在 r/MachineLearning 发布的首发公告,包含背景说明和社区讨论
- MONET 数据集主页 - Hugging Face 上的 MONET 数据集页面,包含数据卡片、下载和示例