5 月 28 日,腾讯混元甩出 Hy-Memory,定位很直接:给 Openclaw 这类长期协作型 Agent 用的记忆插件,官方原话叫"第二大脑"。
这事放在两个月前你可能没什么感觉,但放在今天的时间点上挺有意思——4 月初,腾讯云数据库团队刚开源过 TencentDB Agent Memory,7 周攒了 4.1K stars,已经接进 Openclaw 和 Hermes 跑得有模有样。一家公司一个季度内在 Agent Memory 这个细分领域连发两枪,说明腾讯内部对"记忆层"这件事的判断已经从"试试看"升级到"必须要做"。
先说为什么要做这个东西
用过 Openclaw 的人大概都体验过官方那段被翻烂的"三周轨迹":
第一周是蜜月期。你把项目背景、最近的决策、未来的方向一股脑塞给它,它能查能写能规划,确实好用。
第二周开始不对劲。每天打开都得花三五分钟提醒它"我们在做什么"。你说"按之前那个方案",它反问"哪个方案";你说"那个排除掉的选项",它想不起为什么排除。它不是完全失忆,最近几轮的对话原文还在,但跨天、跨 Session 的判断和上下文,全漂了。
第三周直接降级。用户下意识缩短跟它讨论的深度,从"这个方向我该不该走"变成"帮我搜个资料、改段文字"。Openclaw 内核能力没退化,但在用户认知里,它已经从"思考伙伴"被降级成"查询工具"。
这个轨迹其实不是 Openclaw 独有的,是当下所有长期 Agent 共同的硬伤——LLM 的上下文窗口再大也是有限的,朴素的滑动窗口或 RAG 检索对付不了"跨 Session 的判断演化"这种场景。Hy-Memory 想抹掉的,就是后两周。
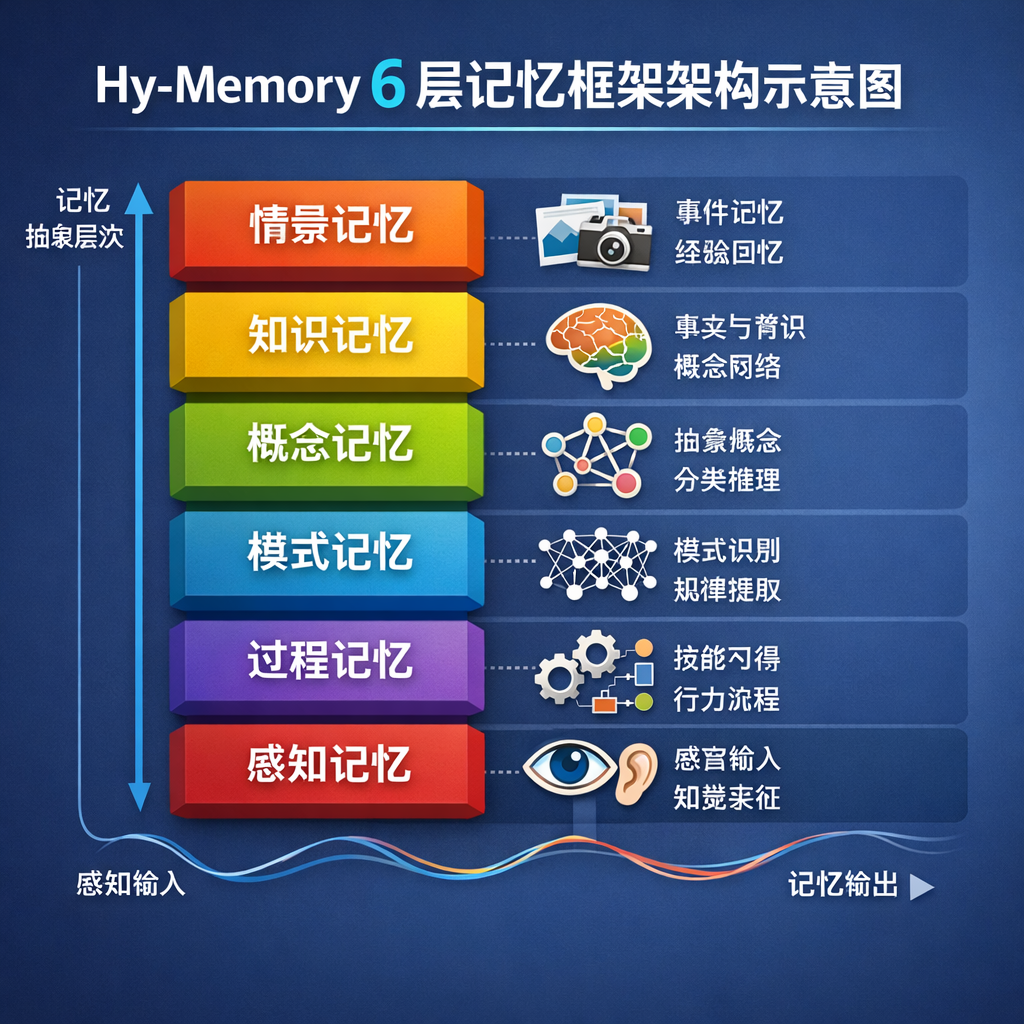
6 层框架 + System1/System2 + 演化链,到底在解什么问题
官方把技术底牌总结成"三件套":6 层记忆框架、System1/System2 双系统、演化链。听起来很 buzzword,但拆开看每一层其实都对应一个具体的工程痛点。
双系统借的是 Kahneman 的壳。 System1 对应快反应的短时记忆,处理最近几轮对话里的事实和状态;System2 对应慢思考的长时记忆,沉淀跨 Session 的判断、偏好、用户画像。这套划分跟 4 月那个 TencentDB Agent Memory 的 L0 Conversation → L1 Atom → L2 Scenario → L3 Persona 金字塔在思路上是一脉相承的——都不再把对话历史扁平塞向量库,而是分层沉淀。
6 层框架的核心目的是分担密度。 朴素 RAG 的痛点是召回时 top-k 全是相似但低价值的碎片,Agent 看到 10 条几乎一样的句子还是回答不好。分层之后,召回的时候可以从高密度的 Persona 层走,落不到再下钻,理论上能用更少的 token 拿到更高的有效信息。
演化链是这次最值得拿出来说的设计。 大多数 memory 框架的失误在于把每条记忆当独立点存——你今天说"用方案 A",明天改"用方案 B",后天又改"混合训练 A+B",向量库里就躺着三条相互矛盾的事实,召回时模型只能猜哪条最新。
Hy-Memory 的做法是用 supersedes 指针把这几条串成一条链:
- A(最初方案)
- B(取代 A) → supersedes A
- C(取代 B) → supersedes B
- D(混合训练,链头) → supersedes C
用户问"新训练方式选什么",搜索命中链头 D,整条链 A→B→C→D 一起展开返回。Agent 不仅知道当前结论,还知道为什么会演化到这里、中间排除了什么。这个设计直接对应了三周轨迹里"那个排除掉的选项是什么"的真实尴尬。
数据怎么样
腾讯混元在权威公开测试集上给的数字:
- 记忆数量降低 70%+
- 单条记忆信息密度提升 45%+
- 超长上下文 token 消耗降低 35%
- 记忆更新速度提升 20%
这组数字内部是自洽的——70% 的记忆数量砍掉、单条密度涨 45%,意味着总信息量没降反升,但存储和检索成本都下来了。如果横向对照 4 月开源的 TencentDB Agent Memory 在 PersonaMem 上把准确率从 48% 拉到 76%、在 WideSearch 上 token 砍掉 61% 的成绩,Hy-Memory 这次的数据其实并不算特别夸张,更像是在已有路线上做了进一步的工程优化。
一个值得注意的点:官方没在通稿里点名比较 Mem0、Letta(前 MemGPT)、Zep 这些社区里跑得比较前的方案。"超过现有主流 memory 框架"这种说法在没有逐项对照的情况下,还需要等第三方复现。这是看这类发布要保留的基本判断。
跟 4 月那波开源是什么关系
这是我读完最想搞清楚的事——腾讯云数据库团队 4 月开源了 TencentDB Agent Memory,腾讯混元 5 月又发了 Hy-Memory,两个东西明显在解同一类问题,到底什么关系?
从公开信息看,两者像是"同公司不同团队的两条产品线":
- TencentDB Agent Memory 是腾讯云数据库团队主导,开源,强调本地化部署、SQLite + sqlite-vec 后端、4 层语义金字塔,定位是开发者友好的工程工具。
- Hy-Memory 是腾讯混元主导,定位是模型团队官方推出的 Agent 增强插件,6 层框架 + 双系统 + 演化链,方法论上更模型驱动。
这种"内部赛马"在大厂里其实不算稀奇,但对开发者反而是好事——你可以根据自己的偏好选:要可控、可自托管、看得见每一层数据,就走开源的 TencentDB;要混元那套方法论加持、对 Openclaw 调优更深,就走 Hy-Memory。两条路线在思路上互相印证,等于"分层 + 演化"这套范式被腾讯两个团队同时押注了。
我的判断:Agent Memory 这个赛道终于卷起来了
2025 年下半年到 2026 年这段时间,Agent Memory 的关注度是肉眼可见在涨。Mem0 的 GitHub stars 越过 20k,Letta 在企业侧拿了不少 PoC,Zep 一直在做 graph memory 路线,再加上 OpenAI 自家的 Memory 功能在 ChatGPT 上铺得越来越深——这个赛道从去年的"小众基础设施",变成了今年所有做长期 Agent 的人绕不开的中间件。
腾讯这次连发两枪,把方向定得很明确:
- 不再迷信扁平向量库。 不管是 4 层还是 6 层,分层都是底盘。原因很简单:扁平 RAG 在长期对话上召回精度衰减太快,工程上无解。
- 记忆要演化,不只是存。 supersedes 链这种设计,承认了"用户的判断会变"这个朴素事实。绝大多数现有 memory 框架都假装这件事不存在,今天看明显站不住。
- 必须卷成本。 token 砍 35%、记忆数量砍 70%——Agent Memory 不是炫技项目,是要在生产环境每天烧钱跑的中间件,单位成本说了算。
有没有可以挑刺的地方?有。一是"权威公开测试集"具体是哪几个、对照组怎么选的,官方介绍里说得不够细;二是 Hy-Memory 当前的接入路径主要锁定 Openclaw 生态,对其他 Agent 框架(比如 Hermes、AutoGen、LangGraph)的支持节奏还没公布;三是"演化链"这种强结构化的记忆,对模型抽取链路的稳定性要求很高,一旦上游抽错了链头,整条链都会被污染——这块的鲁棒性需要时间验证。
但话说回来,这些都是工程问题,不是路线问题。路线本身——分层 + 演化 + 双系统——大概率是接下来一两年 Agent Memory 的主流形态。
对开发者的实操建议
如果你现在正在做长期 Agent 或者多轮深度协作类产品,下面几件事可以排进 todo:
- 如果你的栈在 Openclaw 上,Hy-Memory 和 TencentDB Agent Memory 都值得跑一遍 benchmark,对比一下你自己场景下的召回质量和 token 消耗。
- 如果你在自研 memory 模块,supersedes 链这种"显式建模冲突与演化"的思路可以借鉴,不一定要照搬实现。
- 别再用单纯的"对话历史 + 向量召回"对付跨 Session 协作了——这套方案在 demo 阶段够用,但只要用户连续用两周以上,就会原地塌方。
至于模型本身,做 Agent 的人都清楚,记忆层只是一块拼图,底下还要有稳定的推理能力撑住。多模型对比测试是必修课,OpenAI Hub 这种一个 Key 调 GPT、Claude、Gemini、DeepSeek 全家桶、还兼容 OpenAI 格式的聚合平台,国内调起来比较省事,跑横向对比的时候能省掉一堆账号和网络问题。
写在最后
Agent 不会真的拥有人类那种记忆——它只是用一套越来越精巧的数据结构去模拟"我记得我们聊过什么"。但只要这个模拟够好,用户的感受就是真的。Hy-Memory 是不是"第二大脑"先放一边,至少它和它的开源兄弟 TencentDB Agent Memory 让一件事变得更清晰:长期 Agent 这件事,光靠扩上下文是堆不出来的,得在记忆层老老实实做工程。
这个共识在今天的行业里,已经站住了。
参考来源
- IT之家:腾讯混元发布 Hy-Memory:打造记忆力超强的 Agent 第二大脑 —— 国内首发报道,含官方对"三周轨迹"问题的完整描述
- linux.do 社区讨论:腾讯混元发布 Hy-Memory —— 含 supersedes 演化链的图解和 benchmark 截图