5 月 28 日,Anthropic 把 Claude Opus 升到了 4.8。距离 Opus 4.7 上线还没几个月,节奏比以往任何一次都快。
按照 Anthropic 自己的说法,这次不是常规小修,而是在编程、Agent、长任务稳定性、多模态、诚实性几条线上一起推。价格保持不变——输入 $5/百万 token,输出 $25/百万 token,上下文窗口仍然是 1M,最大输出 128K,训练数据截止到 2026 年 1 月。变化最大的是 Fast 模式:速度提到 2.5 倍,价格只是前代的三分之一(对照 4.7 当时 6 倍价格、5.5 是 2.5 倍价格 1.5 倍速度,这次的性价比明显往下打了一档)。
为什么这么急着发 4.8
社区里有个不算秘密的猜测:OpenAI 上个月的 5.5 打得太漂亮,Claude 这边用户流失肉眼可见。Opus 4.7 的口碑其实不差,但在 Agent 化的长任务场景里,5.5 的体感确实更稳。Anthropic 这次没等 Sonnet 节奏,直接顶 Opus 4.8 上来,目的就是把企业 Agent 这块市场拽回来。
顺便提一句让人有点摸不着头脑的事——Sonnet 4.7 一直没出。社区里有种调侃式的解释:Opus 4.7 可能就是 Sonnet 4.7 改名上场的。这事 Anthropic 没回应,听个乐。
能力盘点:往 Agent 走得更彻底
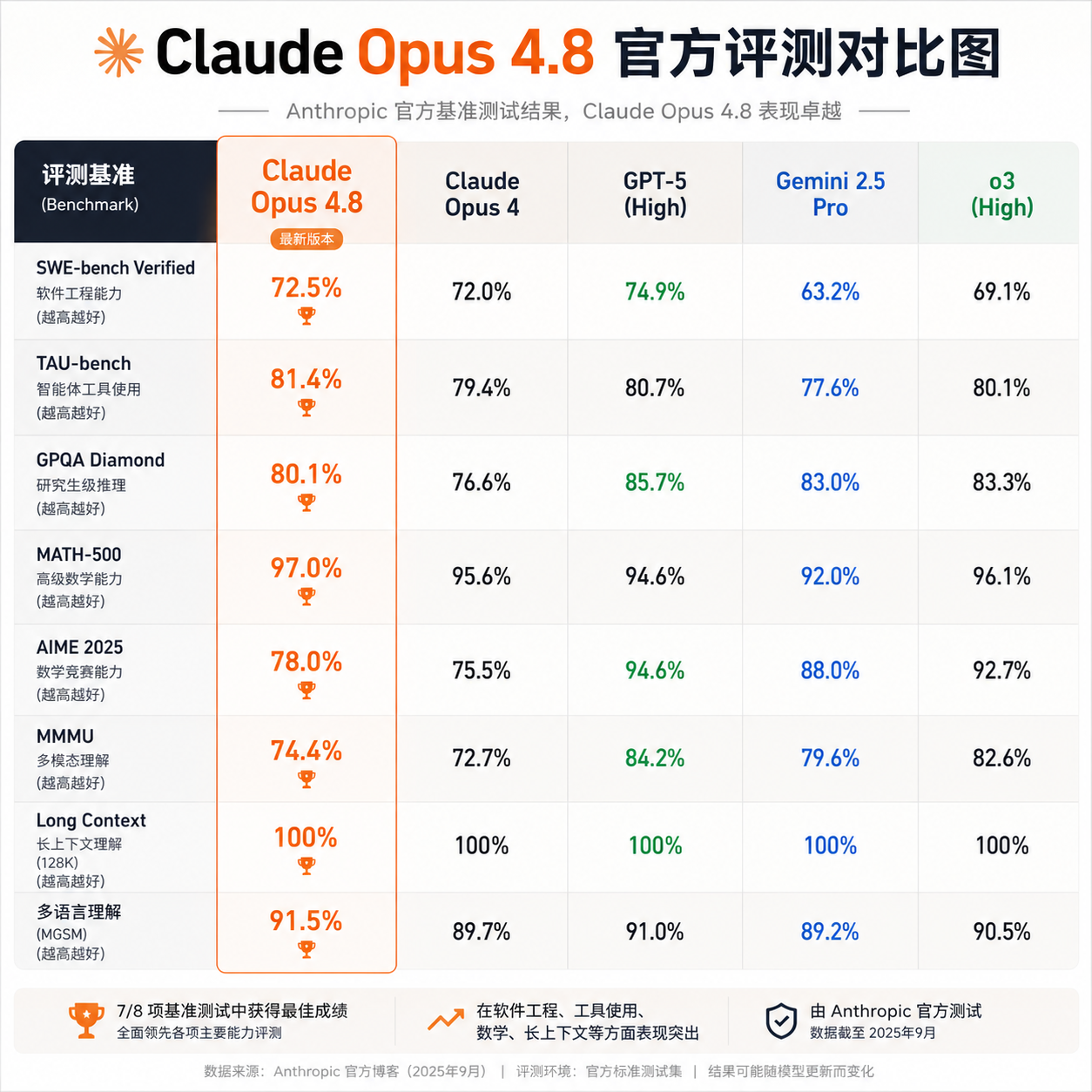
官方放出来的 benchmark 这次很直白,重点全压在 Agent 相关项目上:
- Online-Mind2Web 拿到 84%,这是衡量真实网页操作能力的关键测试集,4.7 时代还在 70 多徘徊
- Browser agent / Computer-use 明显超过 4.7,是这次升级最具体的差异
- 企业 Agent 推理大幅提升,特别是多步任务串联场景
- 多步任务速度更快,token 消耗也压下来了
你把这几条放一起看,画面就清楚了:Anthropic 把 Opus 4.8 当 Agent 引擎打磨。它要解决的是"派一个 Claude 出去干一小时活儿不崩"这件事,而不是 chat 体验提升一档这种增量。
多模态这块也加了料,PDF、图表、扫描件、表格混排这些非结构化内容的处理能力被单独拎出来强调。做企业文档自动化的应该会立刻有感。
思考强度可调,新增 UltraCode 档
Claude.ai 上现在能直接调 Claude 在任务里投入多少"工作量"。这跟 OpenAI 那边的 reasoning effort 是同一思路,但 Anthropic 把它做得更细,专门给代码场景加了个 UltraCode 档位——意思是允许模型花更多 token、更多轮自检去搞定复杂工程问题。
对个人用户来说,可以按需要省钱或者拉满质量;对 API 用户来说,相当于多了一个明确的成本/质量调节旋钮。
动态工作流:把 Claude Code 推向真·并行 Agent
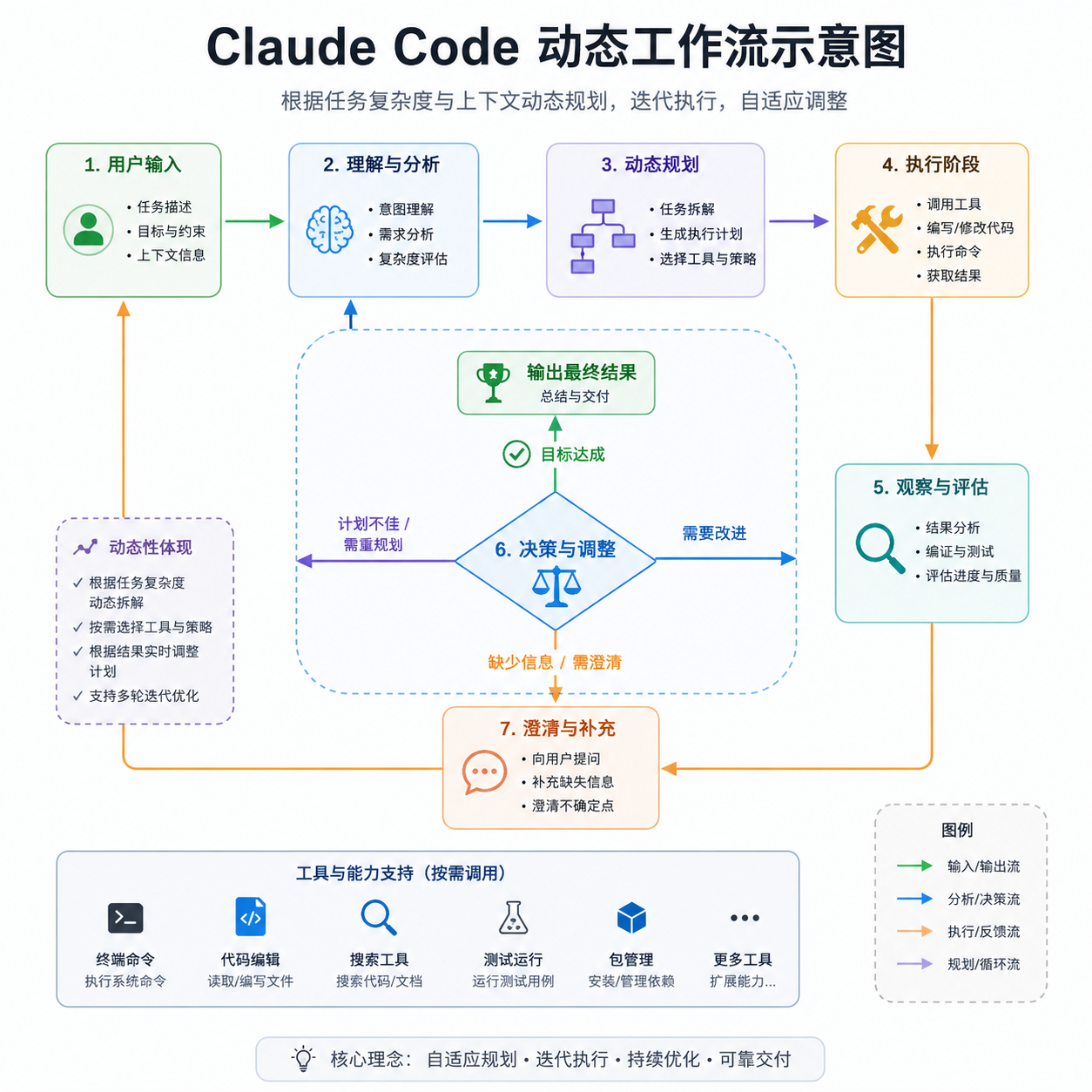
跟模型一起上的还有 Claude Code 的新功能 Dynamic Workflows(研究预览阶段)。
它的玩法是这样的:你扔给 Claude 一个超大任务,它自己拆解后一次性派出几十甚至几百个 subagent 并行处理,再把结果汇总回来。本质上是把 Claude Code 从"一个资深工程师"升级成"一个能开会、能分工、能管下游的 tech lead"。
这跟过去那种主进程 + 子任务的串行结构不一样,更像是真正意义上的 agent swarm 编排。对照过去半年开源社区里折腾的 multi-agent 框架(CrewAI、AutoGen、LangGraph 一堆),Anthropic 这次直接把编排能力内置进 Claude Code,省掉了用户自己搭脚手架的功夫。
实际能跑多大?官方没给上限,但社区里有人已经试过让它一次性扫描整个中型仓库找潜在 bug,反馈是"能跑完、不会半路忘事"。这就是上面提到的"长任务链稳定性"在产品端的兑现。
"诚实"成了卖点
这次发布会让媒体抓得最多的,反而是"诚实"。
大模型有个老毛病:写代码写到一半发现有 bug,但它会一脸自信地告诉你"已修复"。Anthropic 这次的训练目标里专门压了这个——让 Opus 4.8 在不确定的时候主动说不确定,而不是硬编结论。
官方给的数字是:Opus 4.8 在自己写的代码里漏掉 bug 的概率,比 4.7 低了大约 4 倍。早期测试者也反馈,它更愿意承认信息不足、更少做"unsupported claims"。
这点别小看。对开发者来说,模型说"我不确定"比说"我搞定了(但其实没有)"要值钱得多——后者会让你浪费时间调试一个根本没改对的方案。Agent 跑得越长越复杂,这种诚实性越重要,否则错误会层层放大。
同样在 alignment 那块,Anthropic 说 4.8 的欺骗行为(deception)和配合滥用(misuse cooperation)都比 4.7 进一步下降,水平跟他们内部 alignment 最强的 Claude Mythos Preview 持平。
渠道铺得很快
这次发布配套基础设施跟得很齐:
- Anthropic 官网/App:已上线
- API 官方端点:已上线
- OpenRouter:聊天和 API 都已上线
- Claude Code:已上线,UltraCode 和 Dynamic Workflows 同步可用
- Cursor:已上线,可以直接在编辑器里切到 4.8
- LMArena、LiveBench:暂未上线,盲测榜单的位置还要等几天
国内开发者这边,OpenAI Hub 同步支持 Claude Opus 4.8,可以直接用 OpenAI 兼容格式调,省去配代理和管多套 SDK 的麻烦:
from openai import OpenAI
client = OpenAI(
base_url="https://api.openai-hub.com/v1",
api_key="your-api-key"
)
resp = client.chat.completions.create(
model="claude-opus-4-8",
messages=[
{"role": "system", "content": "你是一名资深 Rust 工程师。"},
{"role": "user", "content": "帮我用 tokio 写一个支持背压的并发任务调度器,要求附测试用例。"}
],
max_tokens=8000
)
print(resp.choices[0].message.content)
如果想体验 Fast 模式,把 model 换成对应的 fast 版本即可,按官方价格换算下来,跑大批量 Agent 任务的成本比 4.7 时代下降不少。
实际怎么选
几个建议,按场景给:
- 写代码、跑 Claude Code:基本可以无脑切 4.8。诚实性提升 + UltraCode 档 + 动态工作流,三个东西叠加起来体感差距比版本号显示的大
- 做 Browser Agent / Computer Use:Online-Mind2Web 84% 这个分摆在那里,4.7 已经可以退役了
- 企业文档处理、长表格 / PDF 抽取:多模态升级是这次的重点之一,可以重新跑一遍现有 pipeline 对比
- 纯 chat 场景、轻量问答:升级收益没那么大,跑 4.7 或者直接用 Haiku 也行
一点判断
半年内 Opus 出两个版本,对 Anthropic 来说节奏其实是被对手逼出来的。但 4.8 这次给的东西不是挤牙膏:UltraCode、Dynamic Workflows、诚实性大幅提升、Fast 模式价格腰斩再砍——任何一个单独拎出来都算实在的产品级改进,叠在一起就是把 Claude 在 "Agent 引擎" 这条赛道上往前推了一大截。
5.5 之后的 Claude 是不是真的能稳住盘,要看接下来几周开发者实测的反馈。但至少从这次发布看,Anthropic 没有犯方向性的错误:它选的是把诚实、长任务稳定、并行编排这些 Agent 化时代的基础件做扎实,而不是去堆参数、刷榜单。这条路如果走通了,Opus 系列在企业 Agent 场景的护城河会越拉越深。
参考来源
- Anthropic 正式发布 Claude Opus 4.8 - linux.do 社区第一时间整理的功能亮点和官方评测数据
- Claude Opus 4.8 官方公告机翻 - linux.do Anthropic 官方公告的中文翻译版本
- 关于 Opus 4.8 你想知道的一切 - linux.do 价格、上下文、各渠道上线状态的完整盘点
- 比预剧透更早:Claude Opus 4.8 详解 - 知乎 国内分析师对思考强度调节机制的深度解读
- r/ClaudeAI 社区讨论 开发者实测反馈与对比
- r/ClaudeCode 社区讨论 Dynamic Workflows 实战使用经验