距离 Opus 4.7 上线刚刚一个多月,Anthropic 又把节奏拉了起来。今天(5 月 28 日),Claude Opus 4.8 正式发布,价格不变,但能力线和产品形态都比上一代往前挪了一大步。
这次发布最值得关注的不是又一次跑分胜利,而是 Anthropic 终于把'模型'和'Agent 系统'当成一回事去做——动态工作流(Dynamic Workflows)、可调思考投入(Effort Control)、Fast Mode,这三件事单拿出来都不算颠覆,但合在一起,Claude 这条产品线明显在从'聊天模型'往'长期自主执行系统'转。
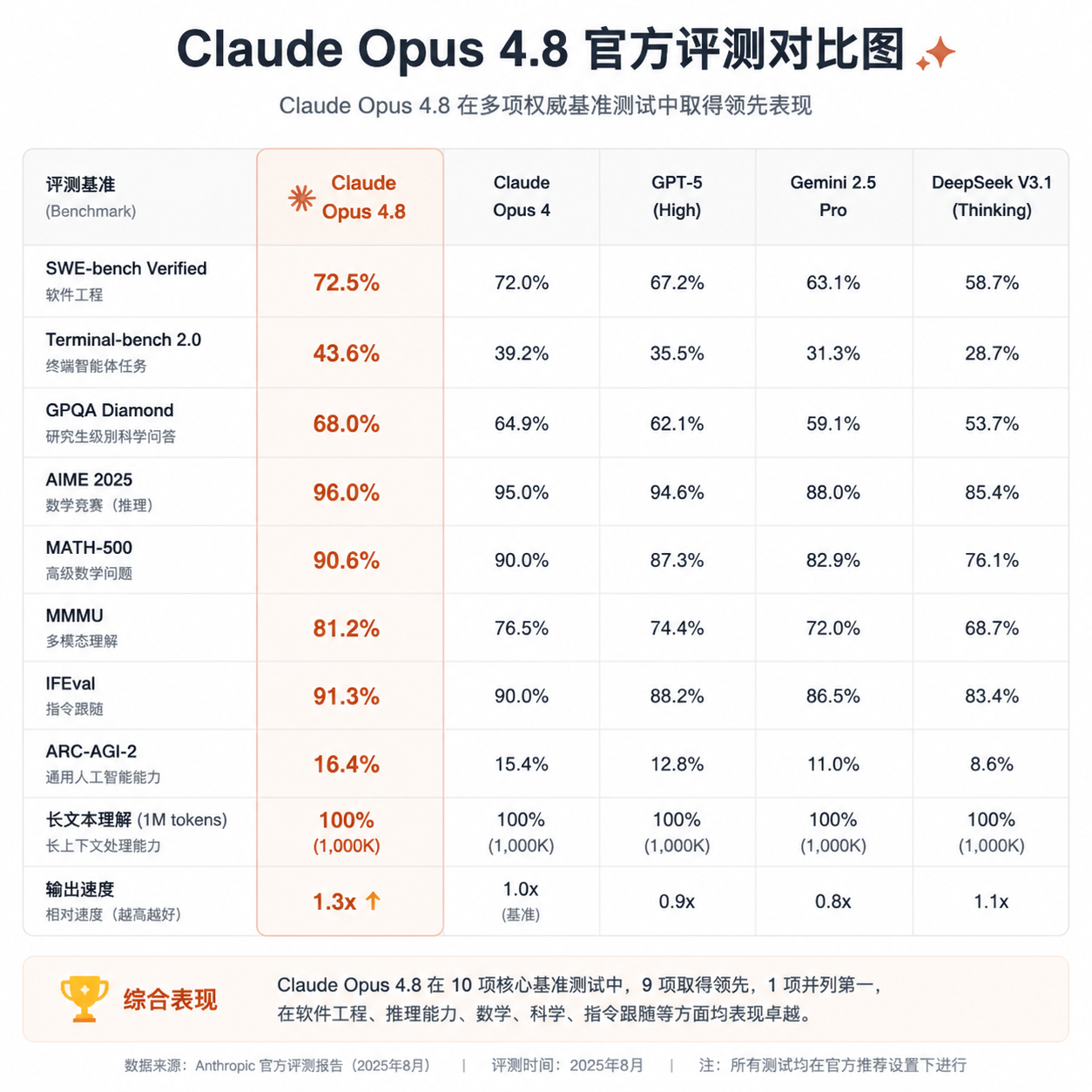
跑分先看一眼,但别只看跑分
官方放出的基准对比里,几个数字比较有意思:
- Online-Mind2Web:84%,这是衡量浏览器智能体在真实网页上做任务的能力,4.7 上还在 70 多分挣扎,这次直接拉到 GPT-5.5 之上
- 编码与 agentic 任务:相对 4.7 有持续提升,Anthropic 自己最强调的是'长任务链稳定性'
- 多模态:PDF、图表、非结构化内容的处理能力进一步提升
- 幻觉率:明显下降,尤其是代码场景
跑分图谁都会做,更值得拆的是 Anthropic 这次反复强调的两件事:诚实度和长任务稳定性。这两个点恰好是过去一年所有大模型在 Agent 化路上最大的两个坑。
'诚实'这件事,是真在用工程指标衡量
Anthropic 在博客里花了不少篇幅讲'honesty'。听起来像玄学,但官方给了一个非常具体的数据:
Opus 4.8 在自己写的代码里漏掉缺陷却不主动提示的概率,约为前代的 1/4。
换句话说,4.7 写完代码会自信地告诉你'已搞定',但代码里其实埋了 bug;4.8 更倾向于说'这一段我不确定,你最好再 review 下'。
这件事对真正在做 Agent 产品的团队意义不小。多步任务一旦中间某一步'自欺欺人',后面所有子任务都建立在错误前提上,整个工作流就废了。一个会主动标记不确定性、承认信息不足的模型,链路越长价值越大。
Anthropic 还提了一个对比:Opus 4.8 的'未对齐行为'(欺骗、配合滥用等)出现率已经接近他们目前对齐表现最好的内部模型 Claude Mythos Preview——这个名字之前在泄露代码里出现过几次,目前还在 Glasswing 项目内小范围测试,主要做网络安全相关工作。
动态工作流:把 Claude Code 直接做成了多智能体编排器
这次最'重'的更新其实在 Claude Code 里——Dynamic Workflows,目前是 research preview。
它解决的问题是这样的:当你扔给 Claude 一个超大规模任务,比如几百个文件的代码迁移、大型 codebase 的安全扫描、整个仓库的 API 重构,传统做法是 Claude 顺序处理,慢且容易丢上下文。
动态工作流让 Claude 自己做三件事:
- 规划:把任务拆成可并行的子任务
- 派活:同时拉起最多数百个并行子 Agent 去执行
- 验收:自己检查每个子任务的结果,不通过就重做
这套机制有点像把一个资深 Tech Lead 的工作流程内化到了模型里。以前你得用 LangGraph、CrewAI 自己搭这套编排,现在 Claude Code 自己就是 orchestrator。Devin 团队反馈说,新版本在工具调用和注释啰嗦的问题上有明显改善;CoCounsel 那边讲的是法律和税务工作流里推理一致性上来了。
这意味着什么?意味着 Anthropic 终于把'多 Agent 协作'从框架层下沉到了模型+产品层。对开发者来说,少了一层胶水代码,但也意味着调试粒度更粗——Agent 内部跑了什么、为什么这么拆,你的可观测性会变弱。这是 trade-off。
Effort Control:让用户给推理深度拧旋钮
另一个产品层面的小但重要改动,是在 claude.ai 上加了'投入控制'。
简单说就是给推理深度加了个旋钮。简单任务往低拧,省 token;复杂任务往高拧,换质量。
这其实是对 OpenAI 的 reasoning_effort 参数的一个对标——但 Anthropic 把它做成了消费端用户也能直接控的 UI。这背后的判断是:固定的'思考预算'对所有任务一刀切,效率低;用户对自己任务的复杂度其实是有判断的,与其让模型猜,不如让用户选。
Fast Mode:成本降到原来三分之一
价格上,常规定价没变:
- 输入:$5 / 百万 token
- 输出:$25 / 百万 token
但同步上线了 Fast Mode:
- 输入:$10 / 百万 token(注:Fast Mode 输入更贵,但速度提升至 2.5×,综合成本对许多任务来说显著下降)
- 速度提升约 2.5 倍
- 整体使用成本约为前代快速版本的三分之一
在 Claude Code 里 /fast 直接切换,API 用户需要联系账户管理员或排队申请。对于交互式编码、需要快速试错的场景,这个模式基本就是默认选项了。
API 调用示例
OpenAI Hub 已经同步支持 claude-opus-4-8,直接用 OpenAI SDK 兼容格式调用即可,省去单独配 Anthropic SDK:
from openai import OpenAI
client = OpenAI(
api_key="your-openai-hub-key",
base_url="https://api.openai-hub.com/v1"
)
resp = client.chat.completions.create(
model="claude-opus-4-8",
messages=[
{"role": "system", "content": "你是一名资深后端工程师。"},
{"role": "user", "content": "帮我把这个 Flask 项目迁移到 FastAPI,列出需要改动的文件清单。"}
],
temperature=0.3,
)
print(resp.choices[0].message.content)
如果要试 Fast Mode 或者带工具调用的 agentic 流程,把 model 切到对应的 fast 变体,其余参数和 OpenAI 完全一致。对国内开发者来说,这条直连路径是目前体验 Opus 4.8 最省心的方式之一。
一些值得多想一层的问题
第一,迭代节奏在加速。 4.7 是 4 月中旬发的,4.8 5 月底就来了,外界根据泄露代码原本预估的发布窗口是 6 月中旬。Anthropic 在 OpenAI、Google 的双重压力下,明显把发布周期压短了。Opus 系列从'季度大版本'变成了'月度小版本',这个节奏跟 GPT-5.x 的滚动更新策略越来越像。
第二,竞争的轴在变。 过去比的是 MMLU、HumanEval;现在比的是 Online-Mind2Web、SWE-bench Verified、长任务成功率。基准测试集本身在重构,背后是整个行业对'模型即产品'的共识已经过期——大家都在做 Agent 系统,模型只是其中最贵的那个零件。
第三,'诚实度'可能是下一阶段的关键差异化点。 当所有头部模型在能力上拉不开太大差距,'我知道我不知道'反而成了稀缺特性。对企业客户来说,一个会承认自己没把握的模型,比一个永远自信满满的模型可用得多。
第四,动态工作流是研究预览,意味着会变。 数百个并行 Agent 听起来很爽,但 token 消耗、可观测性、错误传播怎么管,Anthropic 自己也还在摸索。早期接入的团队大概率会踩坑,但对真正有大型代码迁移、批量重构需求的工程团队,先试起来比等稳定版更划算。
谁该升级?
- 正在做编码 Agent 或者 Claude Code 重度用户:必升,特别是 Fast Mode + 动态工作流的组合在长任务上的体验差距会很明显
- 企业内做 workflow 自动化的:值得严肃评估,诚实度的提升对生产环境意义大于跑分
- 纯聊天、纯写作场景:4.7 够用,4.8 的改进点你可能感知不强
- 对成本敏感的高频调用场景:Fast Mode 值得测,但 input 价格上涨这点要算清楚单位经济模型
Anthropic 这次发布的潜台词很明显:模型本身的智能曲线在变缓,但'让模型把活干完'的能力曲线还有很大空间。Opus 4.8 不是一次性能跃迁,是一次系统化升级——而这恰恰是 Agent 落地到生产环境最需要的东西。
参考来源
- linux.do - Anthropic 正式发布 Claude Opus 4.8 讨论帖:社区第一时间的能力梳理与官方评测图
- linux.do - Claude Opus 4.8 官方公告机翻:Anthropic 官方博客的完整中文翻译
- 知乎 - 比剧透提前!Anthropic 发布 Claude Opus 4.8:包含定价细节、对齐评估和发布节奏分析