一场把行业潜规则摆到台面上的指控
这两天 AI 圈最热闹的事,不是哪家又发了新模型,而是 Anthropic 把同行告上了"道德法庭"。
5 月底,Anthropic 发布了一份措辞罕见强硬的调查报告,公开点名 DeepSeek、Moonshot(月之暗面)、MiniMax 三家中国头部模型公司,指控它们对刚发布不久的 Claude 4.8 实施了"工业规模的蒸馏攻击"。具体数字相当抓眼球:约 24,000 个欺诈账户、超过 1,600 万次交互,绕过区域访问限制和服务条款,系统性地把 Claude 4.8 当成"评分老师",提取推理、编程、工具调用等差异化能力,再用这些产出去训练自家模型。
Anthropic 这次没把话留半句。报告里直接把事件定性为"非法提取",还顺手拔高到"国家安全"高度——理由是这种行为绕过了美国对华的算力与技术出口管制。社交媒体上,Anthropic 联合创始人之一更是连发数贴,把"蒸馏 = 抄近道"的叙事推到风口浪尖。
但剧本没按 Anthropic 写的走。报告发出不到 48 小时,回旋镖就飞回来了。
蒸馏到底是什么,又为什么这次被叫"违规"
先把技术说清楚,免得被叙事带偏。
知识蒸馏(Knowledge Distillation)是 Hinton 在 2015 年就提出的经典训练范式。简单讲,就是用一个能力更强的"教师模型"产生输出,再让一个更小或能力较弱的"学生模型"在这些输出上训练,从而把教师的能力浓缩进学生。这是大模型时代成本控制的标准操作之一,OpenAI、Google、Anthropic 自己都在用——他们把旗舰模型蒸馏成更便宜的 mini、haiku、flash 版本卖给企业客户,这是公开的商业模式。
Anthropic 这次反对的不是蒸馏本身,而是蒸馏对象是别人家的模型。它的逻辑链条是这样的:
- Claude 4.8 的 API 服务条款明确禁止用户将输出用于训练竞争模型;
- 这三家公司通过批量注册的虚假账户访问 API,本身已经违反条款;
- 提取的不是普通问答,而是 Claude 4.8 在 reasoning、agentic tool use、对齐与越狱防护等差异化维度上的输出;
- 因此这不是"学习",是"窃取"。
站在合同法和服务条款的角度,Anthropic 不是没道理。批量虚假账户 + 区域绕行,这两件事在任何一家 SaaS 厂商眼里都属于实打实的违规。问题是,Anthropic 自己屁股也没那么干净。
回旋镖:Anthropic 自己就是版权官司的常客
质疑声里最尖锐的一条来自马斯克:贼喊捉贼。
这话不是骂人。Anthropic 过去两年因为训练数据来源问题已经吃过好几次官司:
- 2024 年被多家美国出版商起诉,理由是未经授权使用大量盗版电子书(包括 LibGen 数据集)训练 Claude;
- 2025 年与作家协会达成上亿美元和解,承认部分数据来源存在合规瑕疵;
- 至于 Common Crawl 抓取的全网页内容,Anthropic 至今的官方立场仍然是"合理使用"。
换句话说,Anthropic 训练 Claude 的时候,把全网公开数据、盗版书库、新闻媒体内容统统当成"知识共有物",理由是"合理使用";轮到别人从 Claude 的 API 输出里学东西,立刻升级为"工业级盗窃"和"国家安全威胁"。
这种双标,连一向亲硅谷的 a16z 合伙人 Marc Andreessen 都看不下去,公开吐槽:"如果蒸馏算犯罪,那人类历史上每一次师徒传承、每一场学术研讨会,是不是都该被起诉?"
更尴尬的是技术圈拿出的"反向证据"。过去几个月,社区一直流传 Claude 在某些 prompt 下会冒出"我是 DeepSeek"或者"我是 ChatGPT"的截图。这种现象在技术上叫 identity hallucination / data contamination——模型在预训练或后训练阶段,喂进去的语料里混入了其他模型的输出。它至少说明一件事:在当下的全球数据循环里,模型互相"喝彼此的水"早就是常态,Claude 自己也没能免俗。
三家中国公司沉默背后的现实困境
截至发稿,DeepSeek、Moonshot、MiniMax 三家公司均未正面回应。这种沉默其实可以理解。
一方面,蒸馏行为在技术上极难自证清白。模型的训练数据来源链条复杂,即便没有主动从 Claude API 拉数据,开源社区里流传的 SFT 数据集、合成数据集很可能本身就包含 Claude 的输出。这就像你买了一袋米,没法证明里头每一粒都不是邻居家飘过来的。
另一方面,反驳的政治成本太高。Anthropic 把事情上升到"国家安全"和"出口管制",再多技术解释也会被美国政策圈解读成"心虚"。三家公司目前更务实的选择,是继续推产品。MiniMax 的 M2 已经在 Agent 场景里站稳脚跟,DeepSeek 的下一代推理模型据传也在路上。
但开发者社区不愿意装哑巴。linux.do 上一条热帖把这件事总结得很到位:"GPT 锐评 Claude 4.8 蒸馏国产模型,回旋镖来得太快"——讽刺的是,当用户把 Anthropic 的指控丢给 GPT-5 评论时,GPT 列出的第一条质疑就是:Anthropic 自己的训练数据来源同样不透明。
这件事真正的意义:AI 行业的"潜规则崩盘"
撕开口水战的外壳,这次事件有几个值得深想的点。
第一,闭源 API 厂商对"输出版权"的主张正在变强。
过去大家默认,你调用 API 拿到的输出可以自由使用。但从去年开始,OpenAI、Anthropic 在服务条款里都加入了"不得用于训练竞争模型"的条款。Anthropic 这次相当于把这一条款第一次拉到公开执法的层面。这对所有用 GPT/Claude 做合成数据、做 SFT 数据的团队都是一个信号——以前灰色地带的做法,未来可能直接被定性为违约甚至侵权。
第二,蒸馏 vs 独立研发的边界,正在被重新定义。
严格意义上的蒸馏(教师-学生范式,logits 级别的知识转移)在 API 场景下其实做不了,因为 API 不返回 logits。所谓"API 蒸馏",本质是用强模型生成高质量数据,再做 SFT 或 RLHF。这种做法和"找标注员写答案"在技术上并无本质区别,区别只在于:标注员是人还是另一个模型。Anthropic 想要建立的,是一条新的"数据来源洁净度"标准,但这条标准在工程上几乎不可执行。
第三,AI 对齐伦理被工具化了。
Anthropic 一直把"对齐"和"AI 安全"作为自己的品牌叙事核心。这次把对手的蒸馏行为和"国家安全"绑定,某种程度上是把"对齐伦理"当成了商业护城河的工具。这种做法短期能博舆论同情,长期会反噬其作为"AI 安全研究领头羊"的中立形象。已经有不少 alignment 研究者公开表态,不希望自己的工作被用来为商业战服务。
第四,开源路线和闭源路线的分歧被进一步放大。
讽刺的是,被指控的三家中国公司里,DeepSeek 和 Moonshot 都是开源路线的代表,模型权重公开下载,社区可以独立验证。而 Anthropic 是典型的闭源路线,至今没有开放过任何 Claude 模型的权重。当一家闭源公司指控开源公司"窃取"时,开发者天然倾向于站在开源一边——不是因为开源就一定对,而是因为开源至少把账摆在台面上。
对一线开发者意味着什么
抛开立场,做工程的人需要关心几件具体的事:
- 如果你在用 Claude/GPT 的 API 生成 SFT 数据:仔细看一遍最新的服务条款,特别是"output usage restrictions"那几条。Anthropic 这次明显在收紧执法尺度,2.4 万账号被一次性封禁就是先例。
- 如果你在做模型对比评测:Claude 4.8 的 API 访问可能会出现更严格的频控和地区限制,跨境调用要做好被封号的预案。
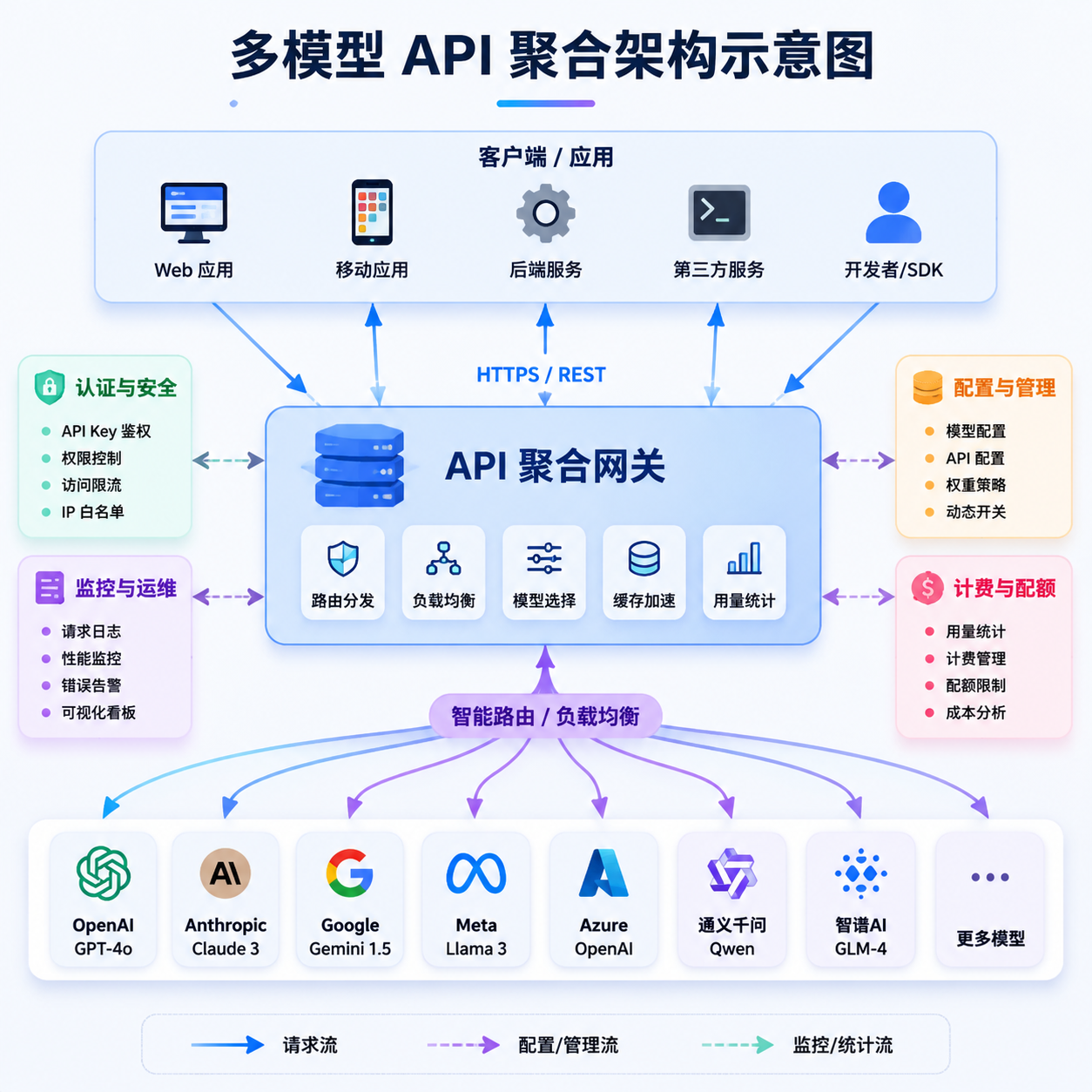
- 如果你在搭多模型对接的应用:单一供应商风险显著上升,多模型聚合方案的价值进一步凸显。像 OpenAI Hub 这类一个 Key 同时对接 GPT、Claude、Gemini、DeepSeek 的聚合服务,在地缘 + 合规双重不确定下,确实能省掉很多账号管理和合规审计的麻烦。
结尾:没有赢家的一场战争
这场争议大概率不会以法庭判决收场。Anthropic 拿不出可以在法庭上 100% 证明对方蒸馏的硬证据——账号关联、流量模式只是间接证据,模型权重又是黑箱。三家中国公司也不会主动承认,毕竟承认了就是把把柄送上门。
但事件本身已经造成了不可逆的影响。它把 AI 行业过去三年默默运转的"互相蒸馏、互为语料"的潜规则,第一次彻底摊开在阳光下。从此以后,每一家做基础模型的公司,都得回答两个问题:你的数据来源能讲清楚吗?你自己又用没用过别人 API 的输出?
如果答案都是诚实的,那大概率谁也别指责谁。如果答案不诚实,那 Anthropic 这次开的头,最终也会回到自己身上。
AI 行业到了一个新的拐点——不是技术上的,而是规则上的。
参考来源
- GPT 锐评 Claude 4.8 蒸馏国产大模型,回旋镖来得太快 - linux.do:开发者社区对本次事件的第一手讨论,包含 GPT 对 Anthropic 指控的反向点评