Claude Code 一次小版本更新,把国产模型集体送进 400 错误
5 月 28 日凌晨,Anthropic 给 Claude Code 推了个看似平平无奇的小版本 v2.1.154。结果国内一觉醒来,论坛炸了——DeepSeek、MiMo、GLM 等几乎所有第三方模型渠道集体报 400 错误,CC 用户工作流直接瘫痪。
问题出在一个新引入的消息角色:mid_conversation_system。
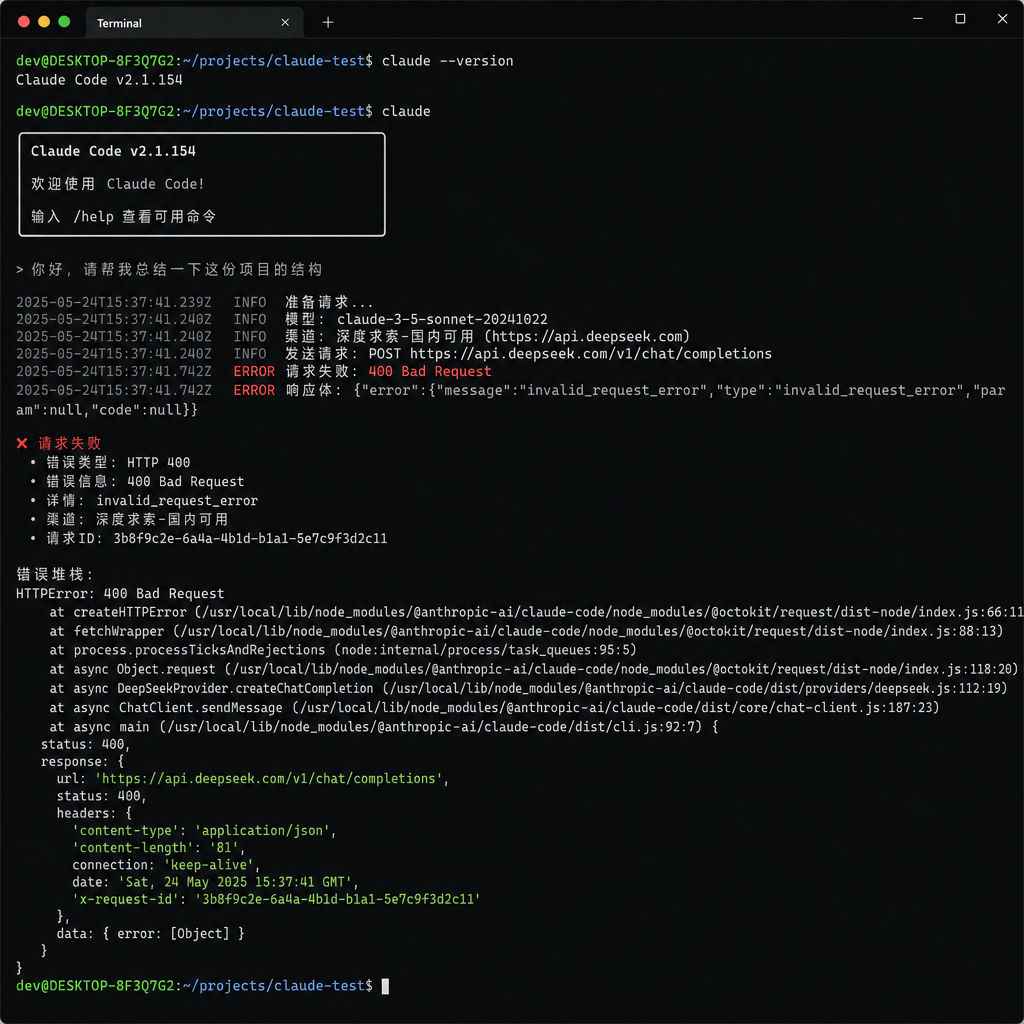
报错长什么样
用 DeepSeek 跑 Claude Code,你会看到这样一段眼熟又陌生的错误信息:
API Error: 400 Failed to deserialize the JSON body into the target type:
messages[1].role: unknown variant `system`,
expected `user` or `assistant` at line 1 column 2194
翻译过来就是:服务端在反序列化请求体时,发现 messages 数组里第二条消息的 role 字段值是 system,但它只认识 user 和 assistant。
这事儿乍一看莫名其妙。OpenAI 兼容格式不是一直支持 system role 吗?怎么突然就不认了?
实际上问题不在第三方渠道,而在 Claude Code 这次更新本身——v2.1.154 改了客户端构造请求的方式,会在对话中段插入 system 角色的消息(而不是只在数组开头出现一次 system prompt)。这种"对话中段 system 消息"在 OpenAI 官方规范里属于灰色地带,大多数兼容层的实现都只允许 system 出现在首条,后续只接受 user/assistant 交替。
为什么是 mid_conversation_system
如果你翻 Claude Code 的 system prompts changelog 会发现,Anthropic 这段时间一直在重构 CC 的提示词架构。从 2.0 系列开始,他们就在往里塞越来越多的"过程性指令"——比如 TodoWrite 提醒、上下文压缩提示、工具调用的合规检查。这些指令本来是用 user 消息或者特殊 tag 注入的,但越用越乱。
v2.1.154 的解法是引入一个新角色 mid_conversation_system,专门用来在对话进行过程中向模型下达系统级指令,和初始 system prompt 区分开。听起来挺合理,问题是:
- Anthropic 自家 API 认这个角色,因为他们的 schema 是私有的、可以随便加;
- OpenAI 兼容协议不认,第三方实现按规范严格校验,自然就 400 了。
更让国内用户头疼的是:很多人用 Claude Code 时根本没在用 Anthropic 官方端点,而是通过中间网关把请求转发到 DeepSeek、Kimi、智谱 GLM、小米 MiMo 这些便宜大碗的国产模型。Anthropic 一改协议,整条链路全瘫。
这其实揭示了一个长期存在的脆弱性:Claude Code 作为客户端,对服务端协议有完全的塑造权,但下游兼容层永远在追着补丁跑。 这次只是改了个 role 名字,下次说不定就是改 tool_use 的结构,或者引入新的 content block 类型。
临时解法:先退回去
论坛上最早给出的方案简单粗暴——回退到 v2.1.153:
# 1. 关闭所有 Claude Code 终端
# 2. 全局安装上一版本
npm i -g @anthropic-ai/claude-code@2.1.153
这招对所有受影响的渠道都管用,因为 v2.1.153 还是老协议,不会发出 mid_conversation_system 这个新 role。
但回退不是长久之计。Claude Code 这两个月平均每周都有更新,新版本通常会带 bug 修复和小功能,长期锁死老版本意味着你享受不到 Anthropic 后续的优化。
渠道方的反应速度
这次国产渠道的响应速度其实挺快。截至 5 月 28 日下午 13:30 左右,MiMo Token Plan 率先完成服务端兼容性修复,做法是在反序列化层把 mid_conversation_system 静默映射为 system(或者根据上下文转成 user 消息),让请求能正常进入推理流程。
实测 Claude Code v2.1.156 在 MiMo 上已经完全正常,无需回退版本,也不需要在配置里加什么实验性开关屏蔽。之前回退到 2.1.153 的用户可以直接升回最新版继续用。
DeepSeek、GLM 的官方 API 和主流网关基本在同一天内也跟上了适配。如果你今天(5 月 29 日)还在遇到这个 400,大概率是用的某个小众第三方代理还没更新,建议先确认上游渠道版本。
这事儿暴露了什么
抛开具体的修复方案,这次小事故其实把"Claude Code + 第三方模型"这套用法的隐藏成本摆到了台面上。
第一个成本是协议追随。 Anthropic 没有义务保持向后兼容,CC 的协议本质上是它自己的内部事务,第三方拿来用就要承担随时被改的风险。这次是 role 字段,下次可能是别的。每次协议变化,全国大大小小的网关都得重新适配一遍。
第二个成本是行为对齐。 就算协议层兼容了,提示词差异也会让 DeepSeek/GLM 跑 CC 的效果和 Claude 原生差一截。Anthropic 的 system prompt 是针对 Claude 的训练分布精心调过的,换个底层模型,工具调用的成功率、TodoWrite 的执行稳定性都会打折扣。这次 mid_conversation_system 的引入就是为了让 Claude 更好地遵循中段指令——别的模型未必吃这一套。
第三个成本是调试体验。 当你的 CC 突然报错,你得先判断是 Anthropic 改了协议、还是渠道方没适配、还是你自己网络出问题。这次报错信息相对友好(Rust 风格的反序列化错误,明确指出哪个字段不对),但下一次未必。
给开发者的建议
如果你日常重度依赖 Claude Code,又想用国产模型省成本,几个实操建议:
- 不要在 CC 自动升级上太激进。 把
npm i -g @anthropic-ai/claude-code@latest改成手动升级,每次升级前看一眼论坛有没有人翻车。 - 关注你用的渠道的更新公告。 MiMo、DeepSeek 这些渠道一般会在协议变化时第一时间发通告。
- 多渠道备份。 在 CC 配置里准备两套 endpoint,主渠道挂了能立刻切到备用。像 OpenAI Hub 这种一个 Key 调所有主流模型的聚合服务(GPT、Claude、Gemini、DeepSeek 都覆盖),在协议变更时通常会在网关层统一处理掉,能省下不少自己排查的功夫。
- 保留一个能跑通的旧版本号在 README 里。 真出问题时回退最快。
小结
v2.1.154 → v2.1.156 这一波折腾,从凌晨爆雷到下午基本平息,前后不到 12 小时。对 Claude Code 这种活跃迭代的工具来说,这种小波折以后还会反复出现。技术上不算大事,但提醒大家:当你把一个由别人控制的客户端架在一堆兼容层之上,你的工作流就有了一个你看不见的依赖图。
现在可以放心升级回 v2.1.156,继续爽用。
参考来源
- Claude Code v2.1.154 + Deepseek API Error: 400 Failed - linux.do - 最早报告问题的帖子,包含完整报错信息和回退方案
- 【已修复】MiMo 已兼容 cc v2.1.154+ 引入的 system role 问题 - linux.do - MiMo 渠道修复公告,确认 v2.1.156 实测正常
- claude-code-system-prompts CHANGELOG - GitHub - 第三方维护的 Claude Code 系统提示词变更记录,可追踪每个版本的协议变化
- Claude Code tool use 并发问题讨论 - Reddit - Claude Code 历史上其他 400 错误的社区讨论,可作为类似问题排查参考