今天小米大模型应用团队扔出了一个有点意思的开源项目:ControlFoley,一个统一的可控视频音效生成框架。代码、模型权重、技术报告、在线 Demo 和开箱即用的 Skill 一次性全部开放,目标只有一个——把视频配音从「模型瞎猜」变成「创作者说了算」。
这事的背景值得先说清楚。过去两年,视频生音频(V2A)已经卷得很厉害,Meta 的 AudioGen、Google 的 V2A、阿里通义的 ThinkSound,再到最近可灵 2.6 的「音画同出」,大家都在解决同一个问题:怎么给一段无声视频自动配上匹配的声音。但仔细看会发现,绝大多数方案停留在「看画面配声音」——画面里有什么,模型就猜该响什么。猜得准固然好,可一旦创作者想要点别的,比如「这只猫张嘴时我希望它发出狮子的吼声」、「这段奔跑的脚步声请按金属质感来做」,模型就傻眼了。
ControlFoley 的切入点正是这里。它要解决的不是「有没有声音」,而是「声音能不能按你想要的来」。
一个模型,三类任务
ControlFoley 把可控音效生成拆成了三种场景,并用一个统一框架全部覆盖:
- TV2A(Text + Video to Audio,文本引导视频配音):视频是主,文本是补。模型根据画面生成同步音效,文本用来补充画面里没说清楚的语义——比如画面是一只鸟在飞,文本可以补充「鸟鸣声 + 远处风声」。
- TC-V2A(Text-Controlled V2A,文本控制视频配音):这是最有意思的一种。当文本和视频语义打架时,模型听文本的。比如视频里是敲键盘的画面,文本写「下雨声」,模型会输出下雨声,但节奏依旧跟敲键盘的动作同步。这是创作者最需要的能力。
- AC-V2A(Audio-Controlled V2A,参考音频控制视频配音):给一段参考音频,让生成结果在音色、风格上贴近它,同时不破坏视频节奏。简单说就是「声音风格迁移 + 视频时序对齐」。
把这三类任务塞进一个模型里训练,听上去合理,做起来其实很拧巴。视觉信号天生强势,多模态融合时它很容易把文本和参考音频的控制意图给「盖掉」——你让它出下雨声,它一看画面是键盘,还是给你出了打字声。这是 V2A 领域的老问题,也是 ControlFoley 在架构上重点处理的对象。
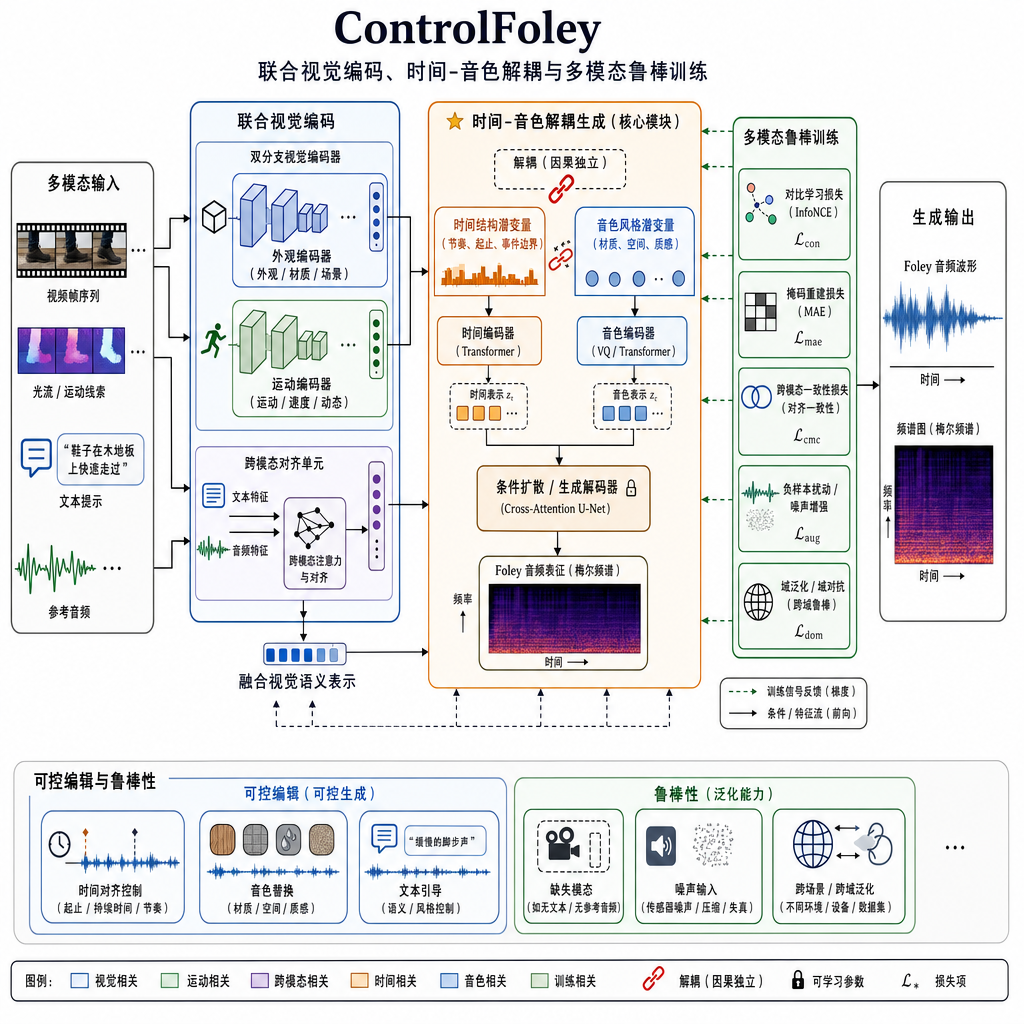
CAV-MAE-ST:为什么要重新造一个视觉编码器
ControlFoley 没用现成的 CLIP,而是自训了一个时空音视频编码器 CAV-MAE-ST。这个选择背后的理由其实挺关键。
CLIP 擅长的是「这是什么」——它把图像和文本对齐到通用语义空间,知道画面里是猫还是狗、是城市还是森林。但 V2A 任务真正需要的信息是「什么动作在什么时刻发生」。比如一个人挥拳,CLIP 能告诉你「这是挥拳」,但说不清拳头击中目标的那一帧到底是第 17 帧还是第 19 帧。而音效生成对这个时间精度极其敏感——错一两帧,整段配音就显得「飘」。
CAV-MAE-ST 是基于 MAE(Masked Autoencoder)思路,在音视频联合数据上做掩码自监督预训练,强化的是动作节奏、事件边界、音画同步这些时间维度的特征。换句话说,CLIP 是「语义专家」,CAV-MAE-ST 是「节奏专家」。ControlFoley 把两者联合编码——CLIP 保证模型理解高层语义、能跟文本对齐,CAV-MAE-ST 保证时间同步不跑偏。
这种「双视觉塔」的思路并不新鲜,但在 V2A 这个具体任务里能跑通,并且让文本控制信号不被压制,是工程上的实打实进步。
时间-音色解耦:让控制变成「拼乐高」
第二个值得说的设计是时间与音色的解耦表征。
在 ControlFoley 之前,大多数 V2A 模型把「什么时候响」和「响什么音色」揉在一起学。结果就是:你想换音色,时间同步也会被一起改坏;你想调时间,音色也跟着变。解耦之后,时间轴归视频管,音色归文本或参考音频管,三类任务就能用同一套架构表达:
- TV2A:视频出时间 + 文本出语义音色
- TC-V2A:视频出时间 + 文本强制覆盖音色
- AC-V2A:视频出时间 + 参考音频出音色
这种解耦的好处是控制变得可组合。创作者可以单独调音色不动时间,也可以保持音色换时间锚点。对实际剪辑工作流来说,这种细粒度控制远比「一键生成」更有价值。
多模态鲁棒训练:防止控制信号「躺平」
第三个关键点是训练策略。多模态模型训练有个老毛病——某些模态如果太「省力」,模型就会偷懒只用那个模态。在 V2A 里,视觉信号最容易让模型偷懒,导致文本和参考音频的控制能力训练不出来。
ControlFoley 在训练时采用了模态随机丢弃 + 冲突样本强化的策略:
- 随机让某个控制模态缺席,强迫模型学会用剩下的模态完成任务;
- 主动构造文本和视频语义冲突的样本,让模型学会「该听谁的时候听谁的」;
- 对参考音频做风格扰动,避免模型只复制粘贴参考音频本身。
这套训练方法的效果,反映在评测结果上。官方放出的数据显示,ControlFoley 在多个 V2A 公开基准上达到了开源 SOTA,在语义对齐、时间同步、声音质量、多模态控制四个维度上都有提升。尤其是 TC-V2A 这种「文本反制视频」的场景,是过去开源模型几乎做不好的事情。
跟竞品比,它的位置在哪
横向看一下当前可控音频生成的格局:
- 蚂蚁 Ming-omni-tts 走的是「语音+音乐+音效统一生成」路线,强项在自然语言指令控制,但视频条件不是它的重点;
- 字节 OmniShow 是 RAP2V 框架(参考图+音频+姿势→视频),重点在数字人,音频是输入而不是输出;
- 可灵 2.6 的「音画同出」 在视频生成时顺便出声音,闭源,更偏一体化创作;
- ControlFoley 则把自己定位在「视频已有,按意图配音」这个细分场景,纯做音效生成,开源。
这其实是一个被低估的市场——短视频创作者、影视后期、游戏开发都需要为已有素材配音,而不是从头生成视频。在这个口子上,ControlFoley 的三任务统一 + 开源 + SOTA,是有竞争力的组合。
开放程度:诚意够足
这次发布的开放力度挺到位:
- 代码完整开源
- 模型权重直接下载
- 技术报告同步放出
- 在线 Demo 可以直接试
- 开箱即用的 Skill(应该是封装好的推理工具)
对开发者来说,这意味着不用等周边生态自己造轮子,拿来就能跑。对二次开发者来说,三类任务的统一架构也方便往里加新控制模态,比如未来加个「情绪标签」「场景类型」之类的条件。
一点观察
从 MiMo 系列到 MiMo-Audio,再到现在的 ControlFoley,小米大模型团队这一年的开源节奏明显在加速,而且每个项目都瞄准一个具体能力缺口,不贪大求全。ControlFoley 不是参数最大的模型,也不是任务覆盖最广的,但它在「可控视频音效」这个具体问题上做到了开源最优——这种做细分赛道的开源策略,比一味追参数榜要更实在。
V2A 这个领域接下来一年应该会很热闹。视频生成模型越来越强、生成时长越来越长,但配音环节还是大量依赖人工或者粗糙的自动方案。ControlFoley 这种把「控制」放在第一位的思路,可能会成为后面所有 V2A 模型的标配。毕竟创作工具的终点从来不是「自动化」,而是「自动化 + 可控」。
模型权重和代码已经在 GitHub 和 Hugging Face 上线,感兴趣的可以直接拉下来跑。在线 Demo 也开放了,想试 TC-V2A 那种「文本压过视频」的效果,三分钟就能体验到。
参考来源
- 小米开源可控视频音效生成模型 ControlFoley,让声音「按你想要的来」 - IT之家:ControlFoley 发布原文,含架构图与三类任务定义