又一个 PR 评审机器人,但这次卖点是「一晚上」
CodeRabbit 太贵,Claude Code Review 还要等灰度,于是有人自己动手了。
5 月 28 日晚,一个名为 Oops 的开源项目在 Linux.do 社区低调上线。作者的描述很直白:「想做个 PR 自动 Review 工具,试了下 CodeRabbit,感觉太贵,决定自己搭一个。」整个项目从想法到跑通只用了一个晚上,核心代码大约 300 行,三个端口搞定。
听起来像是又一个周末玩具,但翻完代码和 Demo 之后,会发现这事比想象的有意思——它把过去搭这类机器人最烦的部分(沙盒、隔离、并发、生命周期)整个甩给了腾讯云的 ADP 服务,作者只需要专心写 Review 逻辑和 Prompt。
这其实是当下 AI 应用开发的一个缩影:基础设施越来越像水电煤,开发者真正要写的代码越来越薄。
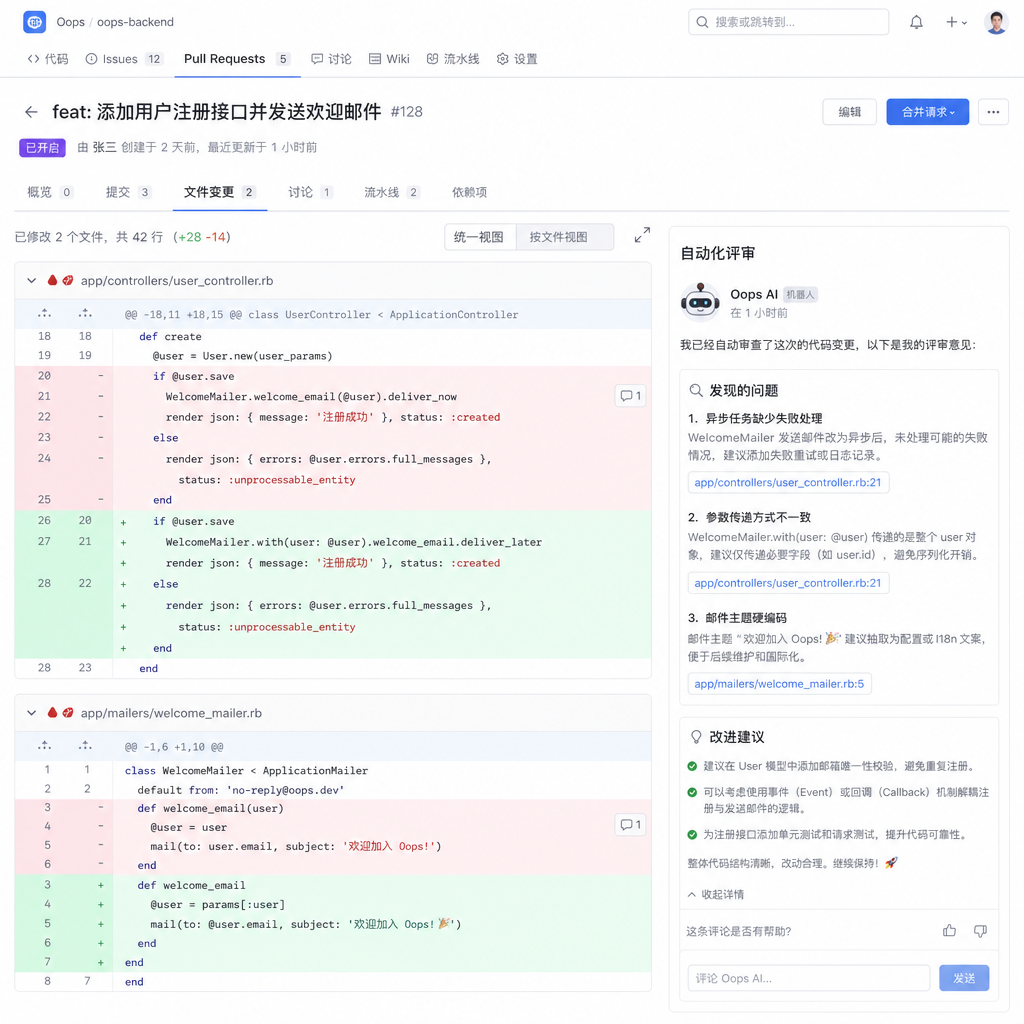
它解决的不是「让 AI 看 diff」,而是「让 AI 真的进到代码里看」
要理解 Oops 的定位,先得搞清楚现在市面上 AI 代码评审工具的两种路线。
第一种是 diff 流派。CodeRabbit 早期版本、各种 GitHub Action 脚本、包括很多个人项目,本质上都是:
GitHub Webhook → 拉 PR diff → 丢给 LLM → 写回评论
这种方式实现简单,几十行 Python 就能搞定,腾讯云开发者社区上也有现成的教程。但问题很直接:模型只看到改动那几行,看不到上下文。比如你改了一个函数签名,模型不知道这个函数在另外 17 个文件里被调用;你引入了一个新依赖,模型不知道项目里已经有类似的工具函数;你动了一个常量,模型不知道它在配置文件里有默认值。
结果就是大量「看起来很有道理但其实没用」的建议,开发者翻几次白眼之后就把机器人关了。
第二种是环境流派。Anthropic 最近推出的 Claude Code Review 走的就是这条路,它会拉起多个 Agent 在真实代码环境里分头检查。Oops 也是这个思路——AI 不是只看 diff,而是真的进到一个沙盒里,把仓库拉下来,可以读任意文件、跑命令、查上下文。
作者自己的总结很到位:「对于跨文件问题,比单纯丢 diff 给模型靠谱不少。」
这话听起来朴素,但里面藏着这一年 AI 编程工具最大的认知转变:让模型「看到」代码远比让模型「聪明」更重要。Cursor、Claude Code、Codex CLI 这一波工具能起来,本质都是在解决上下文获取问题,而不是换了个更强的模型。
把脏活外包:ADP 沙盒的意义
真要自己搭这套环境流派的方案,麻烦事一大堆。作者列出来的清单基本能代表所有从零搭过类似工具的人的痛点:
- 给 AI 准备隔离的代码执行环境
- 处理并发任务(多个 PR 同时进来怎么办)
- 管超时、异常、资源回收
- VPS、Docker、队列、调度全得自己玩
这些东西每一个单拎出来都不难,但凑一起就是一个小型分布式系统,光是搞稳定就够耗几个周末。对一个 side project 来说完全是杀鸡用牛刀。
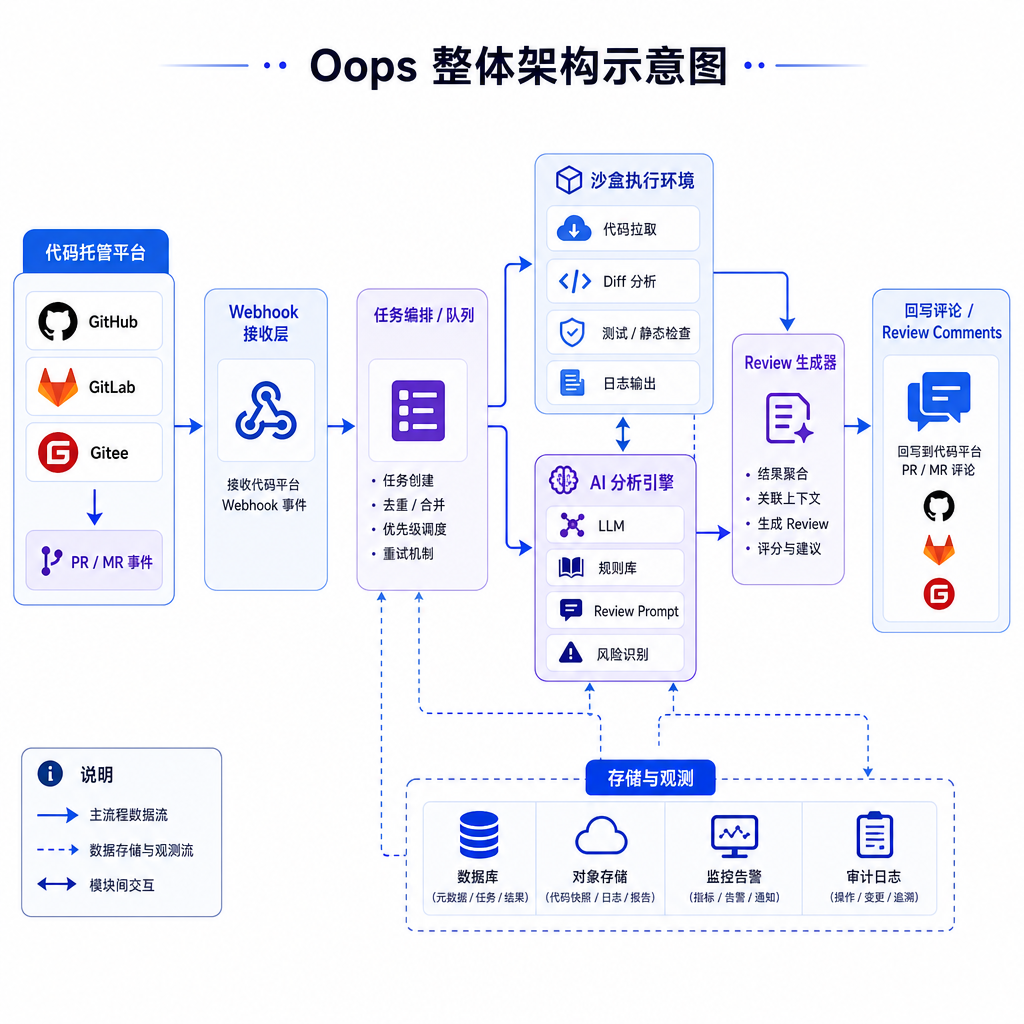
Oops 的解法是直接用腾讯云 ADP(AI Developer Platform)的 Claw 模式。这是腾讯今年推的一个面向 AI 应用的云端沙盒服务,简单理解就是:你调一个 API,它给你一个隔离的 Linux 环境,进去可以跑任何东西,跑完自动回收。并发、超时、资源限制全是平台兜底。
作者用的模型是腾讯自家的 混元 Hunyuan3,目前 ADP 上的沙盒和混元都还在免费阶段,对个人项目相当友好。
这里有个挺值得说的细节:当沙盒成为一种服务,AI 应用的开发心智会发生根本变化。过去你要做一个能「执行代码」的 AI 工具,70% 的精力花在搞容器编排上;现在你只要关心「让 AI 在沙盒里干什么」。OpenAI 的 Code Interpreter、Anthropic 的 Computer Use、各家的 Agent 框架,背后都需要这层基础设施。腾讯把这层做成开放服务,本质上是在抢 AI 时代的「云函数」入口。
300 行代码能装下什么
看了下 GitHub 仓库(Oops-AI-Team/GithubCodeReview),整体结构相当克制。核心流程就是经典的 Webhook 流水线:
GitHub Webhook 触发
↓
校验签名 + 解析 PR 元信息
↓
调用 ADP 创建沙盒,拉取 PR 对应的代码快照
↓
AI Agent 在沙盒里读代码、跑分析
↓
生成评审意见 → GitHub Review Comment API 回写
↓
沙盒回收
三个端口分别对应:接收 GitHub Webhook 的入口、和 ADP 通信的服务、以及和 GitHub API 交互的回写模块。这种「薄薄一层」的设计在 LLM 应用里越来越常见——业务逻辑往 Prompt 里塞,工程逻辑往云服务里甩,剩下的就是粘合。
好处是简单、可读、容易改;坏处是项目的护城河完全取决于 Prompt 工程和你接的那套基础设施。这也是为什么这一类项目同质化严重——技术上没什么秘密,差异都在产品决策上。
Oops 目前明确的差异点有两个:
- 装上就能用,不需要给每个仓库单独配 GitHub Action,作为 GitHub App 安装即可
- 自托管开源,对数据敏感的团队可以自己部署,代码不出内网
第二点很重要。CodeRabbit、Greptile 这类商业方案虽然好用,但代码要发到第三方服务器上,很多公司的合规部门第一个不答应。这也是为什么国内类似的自托管开源项目(比如 ai-code-review-helper、helloworldtang 的 ai-pr-reviewer)一直有市场。
这条赛道到底有多挤
顺手数了一下,光是过去半年公开露面的 AI PR 评审工具就有:
- CodeRabbit:商业老牌,付费贵,体验最完整
- Greptile:YC 系,主打代码库整体理解
- Claude Code Review:Anthropic 官方,5 月刚推,多 Agent 并发
- Kody (Kodus):开源,支持自定义规则和严重性过滤
- WasmEdge 那套教程方案:早期社区项目,纯 diff 流派
- 国内一众自托管项目:ai-code-review-helper、ai-pr-reviewer 等
- Oops:今天这位
模式高度趋同:Webhook 进、Review Comment 出,中间换个模型、换个 Prompt、换个沙盒。真正拉开差距的地方其实只有三个:对大仓库的处理能力、对项目规范的理解深度、噪音控制。
说人话就是:能不能在 monorepo 上跑得动、能不能学会团队的代码风格、能不能不刷屏。这三点目前没有一个开源项目敢说做得很好,包括 Oops。作者自己也承认这是个一晚上肝出来的东西,距离生产可用还有距离。
但话说回来,有这么多人愿意花周末做这个,本身说明 PR 评审这件事在工程团队里的痛点是真实的。每个 PR 都需要一个 reviewer,reviewer 时间是工程组织里最稀缺的资源之一,AI 能替人挡掉 80% 的低级问题,团队就能把精力留给真正需要讨论的设计决策。
给想自己搭的人几个建议
如果你看完想自己搞一个,几个经验值得参考:
关于模型选择:评审场景对延迟不敏感,对推理质量敏感,所以别省钱用最差的模型。Claude Sonnet、GPT-4 系列、DeepSeek-V3、Qwen3 这一档是合理起点。混元 3 在中文项目上表现不错,但英文代码库还得看你自己的实际数据。多模型对比测试是必要功课,OpenAI Hub 这类聚合平台用一个 Key 就能切换主流模型,做评测时省事不少。
关于 Prompt:直接让模型「review 这段代码」效果一定差。要把角色(资深工程师)、关注点(bug、安全、性能、可维护性,按优先级)、输出格式(Markdown,分级别)、不要做什么(不要纠结风格、不要重复显而易见的点)全写清楚。这部分占了实际效果差距的至少一半。
关于沙盒:如果不想用云服务,本地 Docker + 队列也能跑,但要做好资源隔离和超时控制。ADP、E2B、Modal 这一类托管沙盒方案是更省事的选择。
关于反馈闭环:Review Comment(关联具体行)比 Issue Comment(整个 PR 一条)体验好得多,但 API 要求你提供准确的文件路径和行号,这里 LLM 经常翻车,需要做后处理校验。
Oops 现在的状态比较初级,作者也明说了是一个晚上的产物,但思路是对的——把基础设施甩给云、把精力留给 Prompt 和产品。这种「30 分钟跑通 MVP,剩下时间打磨体验」的开发模式,可能才是 AI 应用真正应该有的节奏。
至于它能不能长成下一个 CodeRabbit,看作者后面愿不愿意持续投入。毕竟周末项目最大的敌人,从来不是技术。
参考来源
- 【开源自荐】Oops:用免费 ADP 沙盒,一晚上肝出 GitHub PR AI 代码评审机器人 - Linux.do:项目作者的原始自荐帖,包含完整的开发心路和效果截图
- Oops-AI-Team/GithubCodeReview - GitHub:Oops 项目源码仓库,自托管 GitHub App
- 彻底解放开发者!让 AI 扮演代码检查员 - 知乎:早期 WasmEdge 社区的 AI 代码审核机器人实践,纯 diff 流派的代表案例
- Usagi-org/ai-code-review-helper - GitHub:另一个国内开源的 PR 评审项目,支持 GitHub 和 GitLab,可对比参考