英伟达发布 LocateAnything:当 Agent 终于学会"指哪打哪"
5 月 29 日,英伟达联合香港理工大学、南京大学等团队丢出了一个叫 LocateAnything 的视觉定位模型。看名字以为是又一个 Segment Anything 的衍生品,但细看技术报告后会发现,这次的重点不在"能定位什么",而在"能定位多快"——在单张 H100 上,它做到了 12.7 Boxes Per Second,而对照组 Qwen3-VL 只有 1.1,Rex-Omni 是 5.0。十倍以上的吞吐差距,已经不是常规优化能解释的事情了。
这件事放在 Agent 当道的 2026 年看,意义比一个新 SOTA 数字要大得多。
问题不在"看见",在"够快地看见"
过去一年,多模态大模型几乎把"看图说话"卷成了红海,VLM 的视觉理解能力已经不是瓶颈。但只要你做过具身智能或者 GUI Agent 的落地,就会知道一个反复出现的痛点:模型知道目标在哪,但它告诉你的速度太慢。
一个典型场景:让 Agent 在屏幕上点一个按钮,模型先输出一段自然语言推理,再吐出坐标 token,一个一个数字地解码 x1、y1、x2、y2。对人类来说,眼睛瞄一眼几十毫秒的事,到了模型这儿要等好几秒。机器人控制就更夸张——感知 - 决策 - 执行的闭环里,感知一拖后腿,整个 pipeline 就废了。
英伟达这次直接把矛头对准了"解码方式"本身。
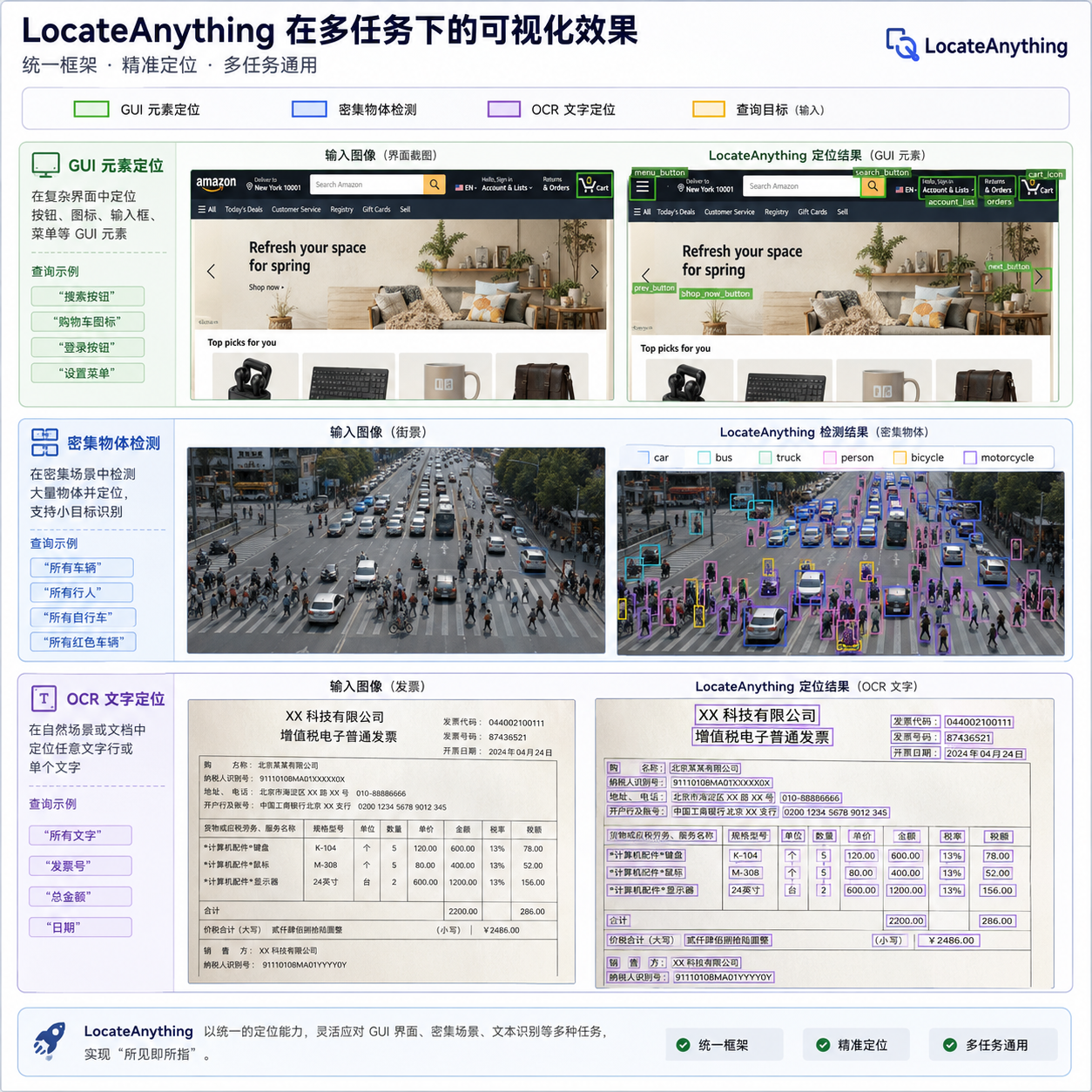
Parallel Box Decoding:把坐标当原子,一步到位
LocateAnything 的核心创新叫 Parallel Box Decoding(PBD,并行框解码)。思路其实很朴素:既然边界框就是固定的四个数字(或者一个点是两个数字),为什么非要逐 token 自回归地吐?
PBD 的做法是把一个 bounding box 视作固定长度的原子单元,在一次前向里并行预测出 x1, y1, x2, y2 全部坐标,而不是一个一个等。听起来像是 Diffusion Language Model(DLM)的思路——论文里也确实引用了 LLaDA、Dream 这类工作——但 LocateAnything 没有完全走扩散路线,而是在生成式 VLM 的框架里做了"块级输出"的改造。
这种设计带来的直接好处是:
- 吞吐量随框数线性放大。一张图里检测 100 个目标和 10 个目标,解码代价的差距远小于自回归方案。
- 延迟稳定。每个框都是一次原子操作,不会因为某个坐标 token 的高熵预测拖慢全局。
- 对密集检测友好。LVIS 这种动辄一图几十上百个目标的场景,传统 VLM 基本跑不动,PBD 是少数能扛住的解码范式。
三种模式:把工程取舍交给用户
LocateAnything 没有走"一个模式打天下"的路子,而是直接给了三档:
- Fast Mode:纯并行解码,追求极致吞吐。面向端侧机器人、具身智能这种实时性压倒一切的场景。
- Slow Mode:回退到逐 token 的自回归解码,精度优先。适合离线数据标注、benchmark 评测这类不在乎速度的活儿。
- Hybrid Mode:默认走 Fast,遇到输出格式异常或空间歧义时自动 fallback 到 Slow。这是官方推荐的默认配置,也是 12.7 BPS 这个数字的来源。
Hybrid 这个设计挺务实的。并行解码最大的隐患就是"幻觉坐标"——四个数字一起预测,互相之间约束弱,偶尔会出现 x2 < x1 这种荒唐结果。Hybrid 用一个轻量的格式检查器兜底,把异常 case 丢回自回归路径重做,工程上是个很经济的取舍。
数据:12M 图像、785M 框,覆盖六大定位场景
光有解码创新还不够,定位类任务的数据稀缺一直是老大难。LocateAnything 顺手发布了 LocateAnything-Data,规模上直接拉满:
- 12M 独立图像
- 138M 条语言查询
- 785M 个边界框
更值得注意的是覆盖面。这不是一个单纯的物体检测数据集,而是把六类定位任务全收了:
- 通用物体检测(General OD)
- GUI 元素定位——这块是 Computer Use Agent 的命根子
- 指代表达理解(Referring Expression Comprehension)
- OCR 文字定位
- 版面定位(Layout Detection)
- 点定位(Point Grounding)
把这六类塞进同一个生成式框架里训练,模型实际上具备了"任何能用框/点表达的视觉任务,都能用自然语言去指挥"的能力。这才是"Locate Anything"这个名字真正的含义。
跑分对比:速度和精度都没让
光快没用,定位类模型最怕的就是"快但不准"。看几个关键 benchmark:
| 指标 | LocateAnything | Rex-Omni | Qwen3-VL |
|---|---|---|---|
| 吞吐(H100, BPS) | 12.7 | 5.0 | 1.1 |
| LVIS IoU=0.95 | 31.1 | 20.7 | - |
| ScreenSpot-Pro 平均 F1 | 60.3 | - | - |
| DocLayNet | 76.8 | - | - |
| M6Doc | 70.1 | - | - |
几个数字单独拎出来说说:
LVIS IoU=0.95 的 31.1,这个指标其实比常见的 IoU=0.5 残酷得多——它要求预测框和真值框的重叠度达到 95%,差一点都算错。Rex-Omni 在这个指标上是 20.7,LocateAnything 高出十多个点,说明 PBD 不仅没牺牲精度,反而在高 IoU 阈值下更稳定。这一点对工业级应用很重要,因为机器人抓取、屏幕点击这种任务,框松一点就是抓偏、点错。
ScreenSpot-Pro 60.3 的 F1 直接对应 Computer Use Agent 的实际能力。Anthropic 的 Computer Use 和 OpenAI 的 Operator 上线一年多了,业内都知道屏幕元素定位的失败率是 Agent 实用化的最大短板。一个能跑 12.7 BPS 还能在 ScreenSpot-Pro 上拿 60+ 的模型,理论上可以让 GUI Agent 的端到端延迟降到现在的几分之一。
DocLayNet 76.8 和 M6Doc 70.1,这两个是版面分析的硬骨头。能在版面定位上拿到这个分数,意味着 LocateAnything 可以直接当文档 RAG 流水线里的版面切分器用,比传统的 LayoutLMv3 + 后处理的方案优雅不少。
怎么用:开源、HF Demo、即开即用
英伟达这次走的是开源路线,模型权重和代码都挂在 Hugging Face 和 GitHub 上,论文项目页也提供了在线 Demo。对开发者来说,几个典型集成场景:
- 具身智能:替换原来 pipeline 里的 OWL-ViT、GroundingDINO,吞吐量直接上一个数量级。
- GUI Agent:作为 Computer Use 类系统的视觉定位后端,配合一个推理 VLM 做"看 + 想 + 点"的分工。
- 文档智能:版面切分 + OCR 框定位一把梭,省掉中间一堆胶水代码。
- 数据标注:用 Slow Mode 跑大规模预标注,人工只做校验。
值得注意的是,LocateAnything 本身不是一个"对话"模型,它是定位专用。实际产品里大概率要和一个推理型 VLM(比如 Qwen3-VL、GPT 系列)配合使用:推理模型负责理解意图,LocateAnything 负责把意图转成坐标。这种"专才 + 通才"的组合,可能是接下来一段时间多模态 Agent 的主流架构。
一点判断
LocateAnything 这篇工作最值得琢磨的,不是某个 benchmark 上的 SOTA,而是它把"视觉定位"从一个 VLM 的副业重新拉回到了"独立模块"的位置。
过去两年的趋势是"一个大模型干所有事",VLM 既要看图说话,又要画框点点,结果是哪样都不极致。LocateAnything 反其道而行之:定位就是定位,就该用专门的解码方式、专门的数据、专门的输出格式。这种"反 end-to-end"的工程哲学,在 Agent 时代反而是对的——因为 Agent 的瓶颈从来不是"单个模型有多强",而是"整条链路有多顺"。
PBD 这个思路本身也未必只能用在视觉定位。任何输出是"结构化、固定长度、低自由度"的任务——函数调用、表格生成、JSON 输出——理论上都可以借鉴并行解码的思路绕开自回归的延迟瓶颈。这条路如果走通,可能比单纯的推测解码(Speculative Decoding)更有想象空间。
至于 Qwen3-VL 这种通用 VLM 会不会被取代?短期不会。但如果你正在做一个需要高频视觉定位的系统,把通用 VLM 里负责"画框"的那部分换成 LocateAnything,几乎是稳赚不赔的事。
参考来源
- IT之家:英伟达推出 LocateAnything,主打 AI 高速、高精度检测对象 —— 国内首发报道,含核心数据和模式介绍
- Hugging Face Model Hub —— LocateAnything 模型权重与在线 Demo 托管地(搜索 LocateAnything)
- GitHub —— 项目源码与训练数据发布地(NVIDIA 官方仓库)