OpenAI 的「去微软化」第一刀,砍在了亚太
5 月 29 日,日本东京证券交易所上市的云服务商 Data Section 突然宣布与 OpenAI 达成战略合作,后者将在前者的 GPU 算力底座上部署模型推理服务,主攻亚太企业级 API 市场。
这件事单看新闻通稿,是一笔普通的算力采购合同。但放在 OpenAI 即将冲刺纳斯达克 IPO、与微软的独家算力协议加速松动的大背景下看,这是个标志性事件——OpenAI 公开宣布多云战略之后,第一家被点名的「新云」合作伙伴,不是 AWS、不是 Oracle、也不是谷歌云,而是一家此前在国际市场上声量并不大的日本上市公司。
这个选择本身就值得琢磨。
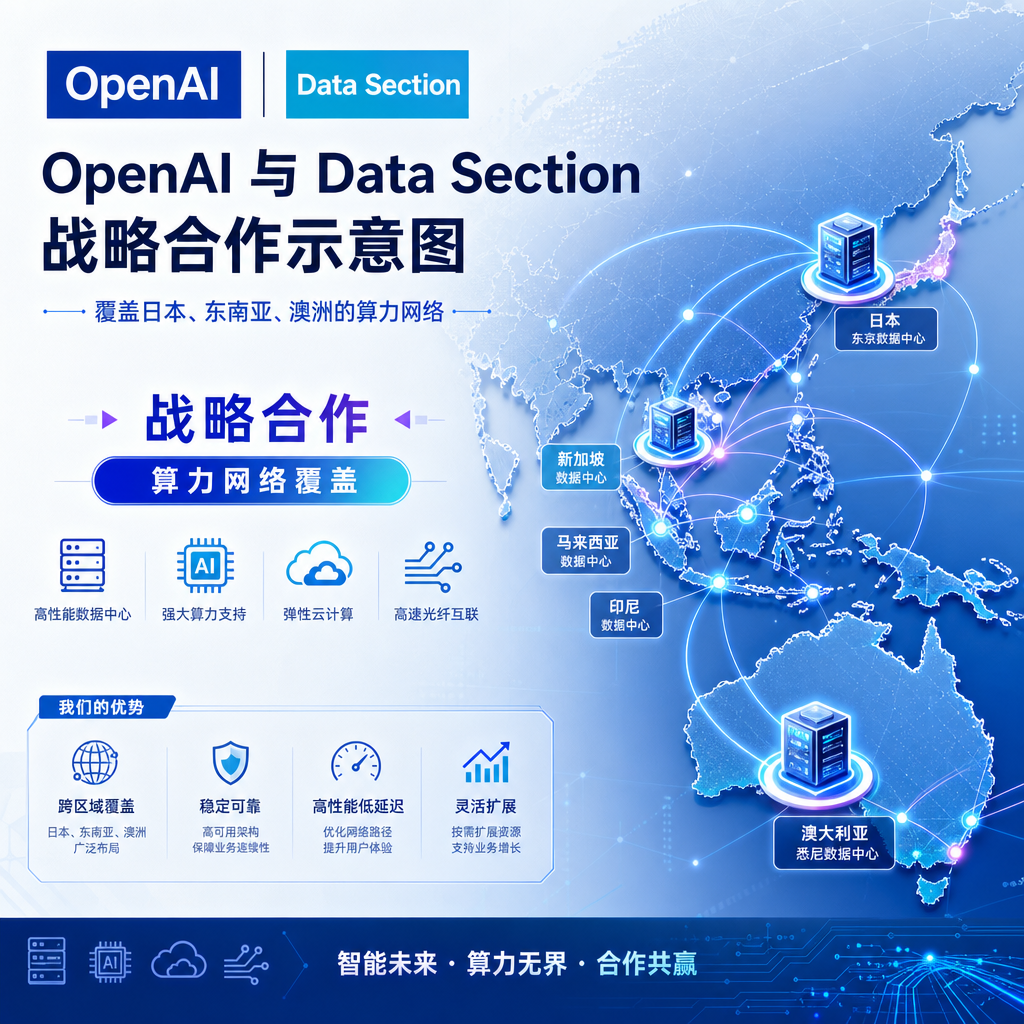
Data Section 是谁?为什么是它
先把这家公司的底盘交代清楚。Data Section 是东证上市的云服务商,比较早开始押注 GPU 数据中心赛道,业务重心放在 AI 推理和高性能计算。目前它的算力节点分布在五个区域:日本本土、泰国、马来西亚、澳大利亚、美国。
这个布点很关键。如果你对照亚太地区企业 AI 落地的合规地图就会发现,日本、东南亚、澳洲恰好覆盖了 OpenAI 在亚太最想吃下、但凭它自己最难直接落地的三块市场:
- 日本:金融、制造、政府客户对数据本土化要求近乎苛刻,外资云直接服务难度极高
- 东南亚:泰国、马来西亚是数据主权立法最活跃的地区,跨境传输限制越来越严
- 澳大利亚:APRA(澳洲审慎监管局)对金融机构使用海外云有专门审查框架
OpenAI 自己直接搞这些事,光是合规备案就能耗掉数个季度。但 Data Section 作为东证上市公司,本身就是「日本血统」+「监管熟客」,相当于现成的合规通道。
根据公开信息,双方的承载平台叫 TAIZA——Data Section 的企业级 AI 工作流平台。OpenAI 的模型会以受监管框架下的形态在这个平台上对外提供。换句话说,企业客户用的还是 GPT 系列模型,但合同主体、数据流向、合规背书全部本地化。
算力栈:B300 与 GB300
技术层面有个细节值得专门拎出来说。根据合作披露,Data Section 在其算力网络中部署的是基于 NVIDIA B300 与 GB300 的集群——这是 Blackwell Ultra 一代,专门为大规模推理负载和高并发场景做了优化的型号。
这意味着两件事:
第一,Data Section 不是拿存量 H100/H200 集群来「凑」OpenAI 的活,而是用最新一代推理优化硬件。GB300 的 NVLink 域和 HBM3e 容量对长上下文推理特别友好,这恰好是 OpenAI 主力模型当前的瓶颈所在。
第二,从硬件代际看,Data Section 在亚太的备货节奏并不落后于一线超大规模云厂商。这也是它能被 OpenAI 选中的硬条件——你跟 Azure 切单子,结果硬件代际还落后两代,那这单做不下来。
这是 OpenAI 的「多云独立」第一单
要理解这笔合作的分量,得回到 OpenAI 与微软的关系上。
过去几年,OpenAI 的算力几乎清一色跑在 Azure 上,这是写进双方协议的独家绑定。微软曾经引以为豪的「OpenAI 独家云伙伴」标签,是 Azure AI 业务过去两年估值跃升的核心支点之一。
但今年以来,这层独家关系一直在松动。OpenAI 公开承认要走多云路线,先后与 Oracle、CoreWeave 谈了大单。而 Data Section 这次的特殊之处在于——它是 OpenAI 在「多云独立」战略下,首个公开命名的核心模型推理承载新云厂商,而且直接押在了一家非美系公司身上。
这传达的信号不止是「不再依赖微软」,更是「不再把算力命脉留在美国本土」。对一家即将 IPO、需要向资本市场讲清楚自己抗地缘风险能力的公司来说,这是必须做的动作。
合作的商业结构:不只是租算力
根据多个信源披露,OpenAI 与 Data Section 的合作并不是简单的算力批发,而是包含三层:
- API 推理承载:把 OpenAI 模型的 API 流量引入 Data Section 算力池,面向亚太企业客户
- 模型微调服务:联合开发面向日语、东南亚语言以及垂直行业的微调方案,先打金融、制造、政府这几个高客单价场景
- 收益分成:双方按合作产生的商业收入做分成,而不是单纯的成本结算
第三点尤其有意思。OpenAI 愿意拿出收入分成,意味着它把 Data Section 当成了渠道合作伙伴,而不是纯粹的基础设施供应商。这是和 Azure 那种「微软先投资、再做独家算力」的关系完全不同的模式。
后续几个季度,双方会陆续披露针对日本大型企业及东南亚市场的行业模型微调方案,并把这套模式向新兴市场复制。
为什么是现在
时间点不是巧合。OpenAI 的纳斯达克 IPO 进程已经进入关键窗口期,华尔街对它的审视早就从「技术信仰」转向了「业务确定性」。投资人想看到的不是 GPT-X 又涨了多少分,而是:
- 收入结构能不能摆脱对北美 ToC 订阅的过度依赖
- 企业级业务在多少个地区有可落地、可计费的合规通道
- 算力供给是不是被绑死在单一供应商
亚太市场是 OpenAI 故事板上最重要的增量来源,但也是它过去最薄弱的一环。Data Section 这一单,本质上是在 IPO 路演前把「亚太企业级收入」这一格从远期蓝图变成可计算的近期现金流。
对 Data Section 来说,这相当于被全球最顶级的 AI 公司盖了一个认证戳。它原本在亚太市场的定位是「专业 GPU 云」,跟 SoftBank 系、NTT 系比并不算第一梯队。但拿下 OpenAI 这单之后,它的资本市场叙事直接换了一个量级——从「日本本土云」变成了「全球 AI 算力去中心化浪潮中的关键变量」。
对开发者意味着什么
如果你是亚太地区做企业级 AI 应用的开发者,这件事的实际影响有几层:
延迟改善:东京、悉尼、曼谷的客户调用 OpenAI 模型,过去要绕到美西或欧洲节点,现在理论上可以在本地区完成推理。对 RAG、Agent 这类多轮调用敏感场景,端到端延迟可能砍掉一半。
合规口径变宽:日本金融厅、澳洲 APRA、新加坡 MAS 监管下的客户,过去用 OpenAI 模型基本只能走「数据脱敏 + 海外调用」的擦边方式。现在通过 TAIZA 平台落地的版本,合规口径会宽松得多,至少在合同条款上能拿出本地化承诺。
价格结构未必降:但别指望价格因此变便宜。Data Section 不是低价云,且收入分成模式决定了它需要保留毛利空间。亚太节点的 token 定价大概率与官方持平甚至略高,靠的是合规和延迟,不是性价比。
后微软时代,亚太成为主战场
把视角再拉远一点。Anthropic 已经深度绑定 AWS 和 Google Cloud,Mistral 选了微软 Azure 和自建,xAI 在 Memphis 自己建超算。每一家头部模型厂商都在用自己的方式回答「算力放哪」这个问题。
OpenAI 选择走「多云独立 + 本地合规伙伴」这条路,第一站落在亚太、且交给一家东证上市公司,这是一个相对激进的姿态。它赌的是亚太企业市场未来三到五年的爆发,赌的是合规壁垒比硬件壁垒更难逾越,也赌的是分布式算力能撑住自己继续膨胀的模型规模。
这场仗才刚开始。Data Section 之后,OpenAI 在欧洲、中东、拉美大概率还会复制类似的「本地上市公司 + GPU 集群 + 收益分成」模式。微软的 Azure 仍然会是 OpenAI 最大的算力来源之一,但「独家」两个字,基本可以从故事里划掉了。
顺带一提,对希望在国内直连调用 GPT、Claude、Gemini 等主流模型的开发者,OpenAI Hub 提供兼容 OpenAI 格式的统一 API 入口,一个 Key 切换不同模型,省去自己折腾跨境网络与多账号管理的麻烦。亚太节点部署成熟后,理论上调用链路的稳定性还会进一步改善。
参考来源
- 抢攻亚太地区企业级 AI 市场,OpenAI 与日本云服务商 Data Section 达成战略合作 - IT之家:IT之家关于本次合作的首发中文报道,详细披露了 Data Section 的算力布点与 TAIZA 平台信息