2B参数的世界模型,把英伟达和斯坦福都挤下去了
5月29日,CVPR 2026 WorldArena 世界模型赛道锁定最终总成绩,智元自研的 Genie Envisioner-Sim 2.0(下称 GE 2.0)拿下 Track1(世界模型感知与动作响应赛道)冠军。同场竞技的对手名单不算客气——英伟达最新模型 DreamDojo、清华联合斯坦福的 Ctrl-World,以及微软等一众旗舰级团队。
更值得说的是参数量:GE 2.0 只有 20 亿(2B)参数。在世界模型这个普遍堆参数、堆算力、堆数据的领域,这是一次相当反直觉的结果。
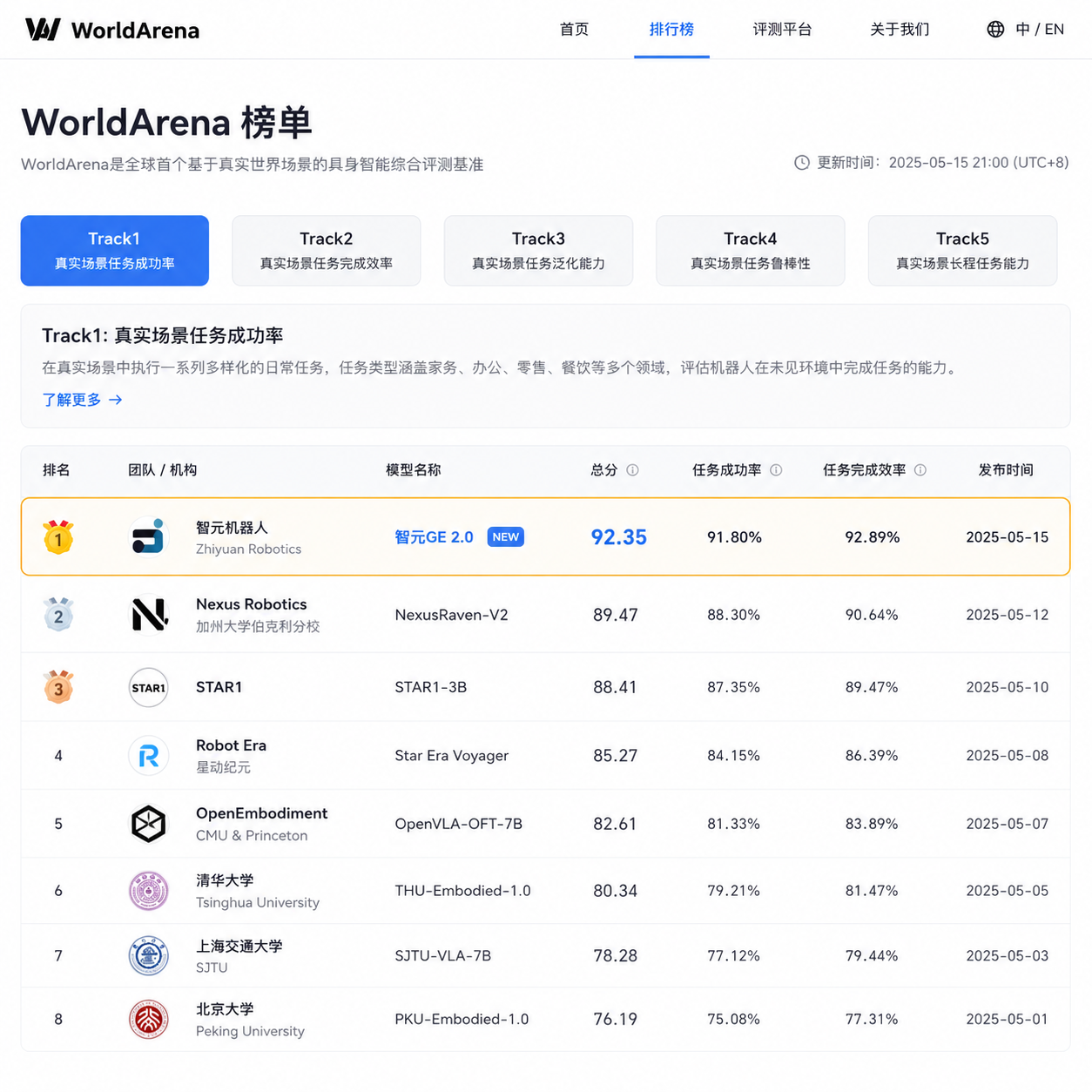
先说WorldArena这个榜到底有多硬
做具身智能的同行应该都清楚,WorldArena 不是那种刷分友好的benchmark。它构建了 16 项细分核心指标 + 3 大真实应用任务的立体评估体系,专门考察具身世界模型的四件事:感知精度、物理规律理解、三维空间认知、动作预测与落地能力。
说白了,就是要你的模型不仅能"看懂"画面,还得真正理解"杯子掉地上会碎、水往低处流、积木搭太高会倒"这种物理常识。在视觉生成模型动辄被吐槽"物理不守恒"的当下,这个评测的门槛比一般的视频生成benchmark高出一截。
智元这次更有意思的一点是——没针对赛题做特调。官方说法是"裸考",团队用的就是原生 GE 2.0,仅基于榜单数据做了基础 Finetune。这个细节如果属实,含金量比单纯的榜单第一要高。因为针对评测刷分这种事在AI圈不算秘密,能做到不优化也拿第一,至少说明模型的通用泛化能力是过关的。
GE 2.0到底升级了什么
相比上一代,GE 2.0 不再是单纯的"视频预测器",而是补齐了一整套世界模拟器的功能闭环。核心包括五个模块:
- 长时序生成:能稳定推演 40-50 秒的连续视频
- 多视角生成:同一场景多机位一致性
- 本体状态生成:机器人自身状态的同步建模
- 近实时推理:满足闭环控制需要的响应速度
- 奖励判别:内置 Reward Model,能自动评估rollout质量
这套组合拳的意义在哪?传统世界模型的痛点一直是"重视觉、轻物理、难落地"——画面很漂亮,但物理逻辑稀碎,机器人策略根本没法基于它去做决策。GE 2.0 试图把这条链路打穿。
长时序:50秒之后还稳,行业基线10秒就崩
这是 GE 2.0 技术报告里我觉得最硬的一项数据。
世界模型做视频生成,行业老问题就是"长度的诅咒"——推理时间越长,画面质量衰减越严重,物理一致性也越容易飘。一般行业基线模型在 10 秒后就开始出现明显的崩坏:物体穿模、物理违和、累积误差爆炸。
GE 2.0 给出的数据是:连续推演 40-50 秒时,生成质量依然超过基线模型前 10 秒内的表现。换句话说,别人的"巅峰状态"还不如它的"末段表现"。这对具身策略训练特别关键,因为机器人任务普遍需要几十秒级别的连续推演——抓取、装配、搬运,哪个不是几十步的连续动作链。
闭环评测:从"成功率一致"到"逐case对得上"
世界模型作为策略评测器,最容易被质疑的就是:你在仿真里成功了,到真机上还能成功吗?
智元这次给的答案是双层验证:
- 宏观层面:仿真中的成功率与真实世界保持强相关;
- 微观层面:做了 Case-by-case 的 rollout 对比,并通过**混淆矩阵(Confusion Matrix)**给出量化佐证。
第二点其实是个关键升级。以往很多团队只敢拿出平均成功率说事,但真要做策略筛选,你得保证仿真里失败的case在真机上大概率也会失败、仿真里成功的case真机也能复现——这才叫"策略评测器靠谱"。混淆矩阵直接把这个相关性可视化了,学术上算是相当诚恳的做法。
数据回流:世界模型给策略模型当"陪练"
GE 2.0 的另一个亮点是数据回流机制。这套流程大致是这样:
Policy Model → rollout in GE 2.0 → Reward Model 筛选 → 高质量数据 → 反哺 Policy Model
这个闭环在强化学习领域并不新鲜,但能在世界模型里跑通,意味着具身智能终于不用再依赖海量真机数据采集了。要知道智元自己建了全球首个 3000 平方米机器人实景数据采集场地,他们比谁都清楚真机数据的成本有多高。
实验数据显示,这套自动化筛选机制在多项任务上都带来了策略模型的显著涨点——这意味着仿真训练终于可以脱离"人工挑数据"的低效模式,进入自动化迭代阶段。
2B vs 千亿:轻量化路线为什么能赢
回到最开始那个问题:为什么 2B 参数能干翻英伟达的旗舰模型?
我的判断是,这跟具身智能这个赛道的特殊性有关。
语言模型领域,参数规模和能力基本是正相关的,所以大家拼命堆。但世界模型的核心瓶颈不是"知识量",而是"物理一致性"和"实时性"。一个超大模型如果推理慢、长时序不稳,再聪明也用不到机器人上——机器人控制需要毫秒级响应,等你大模型推理完一帧,物体早掉地上了。
智元这次相当于用一个明确的实验结果说明:在人形机器人这种实时闭环场景里,轻量化模型不仅适配性更好,效果也未必输给超大参数模型。这跟自动驾驶圈那套"端侧小模型 + 物理约束"的思路其实是异曲同工。

智元的全栈布局
稍微拉远一点看,GE 2.0 的登顶不是孤立事件。今年 4 月智元搞了一周的 "ALL IN AI WEEK",连续发布了五个东西:
- 开源数据集
- 开源仿真平台(Genie Sim)
- 基座大模型(Genie Operator 1)
- 世界仿真器(Genie Envisioner)
- 机器人部署应用平台(Genie Studio)
这套"数据—仿真—模型—应用—生态"的全链路布局,跟其他主打机器人本体的公司路线明显不同。智元的定位更接近"具身智能的基础设施提供商"——它不靠卖机器人本体赚钱,而是想成为整个物理 AI 行业的底层供应方。
GE 2.0 这次拿下 WorldArena,其实是这个全栈布局里"仿真"和"模型"两块的一次集中输出。从产业逻辑上看,比单点的硬件突破更具杠杆效应——因为基础模型的价值是可以复制到全行业的。
项目地址和开源情况
智元这次给出了完整的资源链接:
- Project page:https://ge-sim-v2.github.io/
- Arxiv 技术报告:https://arxiv.org/abs/2605.27491
- GitHub 仓库:https://github.com/AgibotTech/GE-Sim-V2
对于做具身智能、机器人仿真训练、世界模型方向的开发者来说,这套代码和报告值得过一遍,尤其是长时序稳定性和混淆矩阵那部分的实现细节。
一点判断
2026 年被业内普遍称作具身智能的"部署态元年"——机器人开始从实验室往真实场景走。这个阶段对算法的要求会变得非常"实用主义":你模型再强,跑不到机器人上、扛不住几十秒的连续任务、给不出可靠的仿真数据,就是没用。
GE 2.0 这次登顶最有价值的信号,不是"中国团队赢了英伟达",而是轻量化 + 全功能 + 闭环可用这条路线被证明可行了。在世界模型这个赛道,可能我们正在见证从"卷参数"到"卷物理可信度和落地能力"的转折点。
至于英伟达 DreamDojo 和 Ctrl-World 团队接下来会怎么应对,值得继续观察。CVPR 现场应该有更多细节披露。
参考来源
- IT之家:2B 参数"四两拨千斤",智元自研世界模型 GE 2.0 登顶 WorldArena 榜单 - 智元 GE 2.0 登顶榜单的核心报道
- GitHub:AgibotTech/GE-Sim-V2 - GE 2.0 官方开源仓库