6 月 1 日,黄仁勋在台北的舞台上一口气讲了两件大事:新一代 GPU 平台 Vera Rubin 已经全面投产,以及英伟达 Nemotron 联盟拿出了一个 5500 亿参数的混合专家开源模型——Nemotron 3 Ultra。前者是硬件,后者是软件,配合得相当刻意。
如果说去年的 Llama 3、年初的 DeepSeek V3 把开源前沿模型的门槛推到了一个不低的位置,英伟达这次的动作可以理解为:要在开源权重这条路上再加一脚油门,而且油门是踩在自家 Blackwell 架构上的。
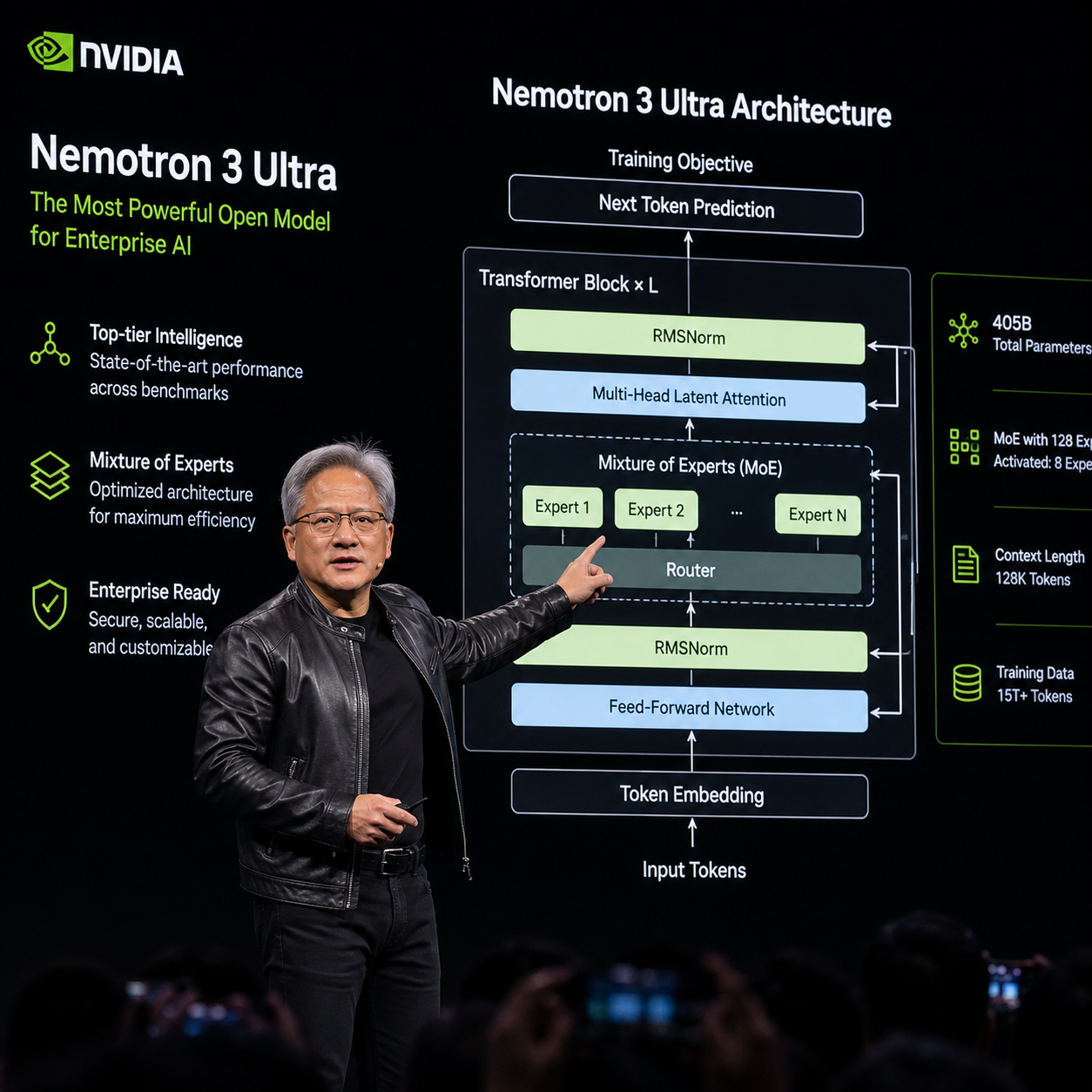
一个为「长效智能体」设计的 MoE
官方给 Nemotron 3 Ultra 的定位很直白:为全天候运行的智能体提供顶尖智能能力,覆盖代码开发、科研、企业业务流程这三类典型场景。
参数规模 5500 亿,混合专家架构。结合此前 Nemotron 3 系列的设计思路(Nano 已经在 Hugging Face 上线),Ultra 的稀疏激活策略大致是「总参数堆得高、单 token 激活参数控制在几百亿区间」——这也是它能在号称推理速度比同级开源前沿模型快 5 倍的同时,把使用成本压低最多 30% 的底层原因。
这里需要泼一点冷水:英伟达没明确说「同级别主流开源前沿模型」具体指谁。从参数规模看,对标对象很可能是 DeepSeek V3 / R1 这种 671B 级的 MoE,或者 Llama 4 系列里的大杯。5 倍这个数字大概率是在 Blackwell(B200 / GB200)平台上做的对比,换到 H100 甚至更老的卡上,差距会缩小不少。开源模型跑分这事,从来都得看跑在什么硬件上。
但这恰恰是英伟达开源策略的精明之处——模型本身免费,但最优推理性能绑定在自家硬件栈上。Vera Rubin 全面投产、Blackwell 大规模出货、Nemotron 系列持续更新,三条线是同一盘棋。
已经接进了主流 Agent 框架
相比单纯发个权重,Nemotron 3 Ultra 这次更值得注意的是后置训练阶段做的工程化适配。官方点名支持的智能体框架包括:
- Hermes Agent
- LangChain Deep Agents
- OpenClaw
- OpenHands
- OpenCode
这意味着开发者拿到模型后,不用自己再去对齐工具调用格式、规划链格式、记忆接口——直接挂进 LangChain 的 Deep Agents 或 OpenHands 这种比较成熟的调度框架就能跑。对企业落地来说,这一步省下来的工程量并不小。
过去一年里,「长效智能体」(long-running agents)这个词在英伟达、Anthropic、Cognition 这些公司的话术里出现的频率明显变高。和单轮问答、单次代码补全不同,长效智能体要求模型在几十分钟甚至几小时的任务链路上保持连贯——长上下文、稳定的工具调用、错误恢复,每一项都是硬功夫。
Nemotron 3 Ultra 的 MoE 架构在这件事上有天然优势:稀疏激活意味着同样的算力预算下可以支撑更长的推理链,对持续在线运行的成本更友好。
CrowdStrike 和 Palantir 已经先用上了
英伟达拿出了两个落地案例,分量都不轻。
CrowdStrike 把 Nemotron 模型接进了自家的网络安全智能体里,让它去做不间断的漏洞排查、风险分级、配置错误修复。这是个典型的长效场景——安全运维本来就是 7×24 的活,过去主要靠规则引擎加人工,现在让一个能持续运行、能调工具、能写补丁的智能体顶上去,对安全团队是实打实的减负。
Palantir 那边更有意思。它把 Nemotron 接进了 AI FDE(前线部署工程师)平台,做的是物理隔离的企业系统内闭环——智能体在交互中产生的数据持续回流,用于针对特定业务领域做持续微调。这种「数据不出园区,模型在场内迭代」的模式,是开源权重模型相对闭源 API 最大的优势之一。如果只能调 GPT-5 的 API,Palantir 这种主打高安全、高定制的场景几乎玩不转。
不只是一个 Ultra,是一整套 Nemotron 3
把视角拉远,Nemotron 3 Ultra 只是这个系列里块头最大的一个。整个家族已经铺开:
- Nemotron 3 Nano:轻量级,已在 Hugging Face 上线,跑在边缘和本地都没压力
- Nemotron 3 Nano Omni:全模态版本,原生集成视听编码,官方称性能较上一代提升 9 倍
- Nemotron 3 Super:3 月发布,曾是英伟达「最强开源权重模型」
- Nemotron 3 Omni:多模态整合版,音、视、语一锅端
- Nemotron 3 Ultra:本次主角,5500 亿参数 MoE
- 安全防护模型 + 语音识别模型:补齐企业级智能体的两个常见短板
从产品矩阵上看,英伟达想要做的不是「再发一个大模型」,而是一整套可以拼出企业级智能体的开源积木。从 Nano 跑端侧、Super/Ultra 跑云端推理,到专门的安全护栏和语音 ASR,再到和 LangChain、OpenHands 这些上层框架的适配,这套东西的目标客户画像是非常清晰的:有自建 AI 基础设施需求的中大型企业。
这和 Meta 当初开源 Llama 的逻辑略有不同。Meta 是要打破 OpenAI 的封闭叙事,英伟达则是要把「想自己做 AI 的企业」全部接到自己的算力生态里。开源模型在这里更像是「钩子」,钩住的是 Blackwell 卡和 NIM 微服务的长期订单。
6 月 4 日开放下载
按官方时间表,Nemotron 3 Ultra 将于 6 月 4 日通过以下渠道分发:
- Hugging Face
- ModelScope(魔搭)
- OpenRouter
- build.nvidia.com(以 NVIDIA NIM™ 微服务的形式)
- 各大 NVIDIA 云合作伙伴的推理平台
ModelScope 这一项对国内开发者比较友好,省去了 Hugging Face 直连的麻烦。如果你只是想先跑起来看看,预计也会有不少社区第一时间在 OpenRouter 上挂出来供 API 调用。
几个值得观察的点
第一,5 倍推理速度这个数字到底怎么落地。MoE 模型在 vLLM、SGLang 这些主流推理引擎上的支持度差异挺大,5500 亿总参数的部署门槛也不低——至少要一台 8×B200 或者类似规格的机器才舒服。社区跑出来的实际数字才是真数字。
第二,对 DeepSeek 的冲击。过去半年里,DeepSeek V3/R1 在开源 MoE 这个细分赛道上几乎是默认选项,性价比、中文能力、推理能力都打得很扎实。Nemotron 3 Ultra 如果真能在长任务、工具调用、Agent 场景上做出明显差异化,会是一次有意思的正面对撞。
第三,英伟达的开源边界。Llama、Qwen、DeepSeek 是模型公司开源模型,而英伟达是硬件公司开源模型——它的动机和约束都不一样。模型权重开放、训练数据集也部分开放(Nemotron 联盟之前放过几个),但训练所用的优化路径和工程 know-how,多半还是会留在自家 NeMo 框架里。这是健康的开源生态,还是另一种形式的「开源即销售线索」,留给时间。
硬件那边,Vera Rubin 投产把 Blackwell 时代的组装时间从两小时压到了 5 分钟,整条供应链规模翻倍。软件这边,Nemotron 3 Ultra 把开源 MoE 的天花板再抬了一截。英伟达正在把「卖卡」这件事,做成「卖一整套可以自己造 AI 的能力」。
这是这家公司今天最大的故事。
参考来源
- 英伟达发布 5500 亿参数 Nemotron 3 Ultra 开源模型,较同级别前沿模型推理速度最高提升 5 倍 - IT之家:本次发布的官方信息与生态合作伙伴细节
- 英伟达成开源新王?Nemotron 3 全新混合专家架构,推理效率升 4 倍 - 知乎:Nemotron 3 系列整体架构与参数激活策略分析
- Nemotron 模型在 Hugging Face 的发布页面:英伟达官方模型仓库,6 月 4 日 Ultra 权重将在此放出