英伟达甩出320亿参数VLA:自动驾驶终于有了像样的开源教师模型
6月1日,台北GTC 现场,黄仁勋把英伟达 Alpamayo 系列的参数规模一口气从 100 亿拉到 320 亿。新模型叫 Alpamayo 2 Super,定位是一个基于推理的视觉-语言-动作(VLA)开源基础模型,目标客户写得很直白——做 L4 Robotaxi 的那批人。
如果说半年前发布的 Alpamayo 1 还只是英伟达试水开源 VLA、向业界证明"汽车也能像 ChatGPT 那样思考"的样品,那么这次的 2 Super 摆明了是冲着教师模型的位置去的:你蒸馏我,我开源;你不用从零搭,我把数据、仿真、闭环训练这一整套全给你。

不是简单的参数翻三倍
外界看模型,习惯先盯参数。Alpamayo 2 Super 从 100 亿到 320 亿,账面是 3.2 倍。但真正值得看的不是这个数字,而是它要做的事和前代完全不在一个层次。
Alpamayo 1 那一代,本质上还是个轨迹生成模型——给它一段视频,它告诉你下一秒方向盘怎么打、油门怎么踩。2 Super 把活儿揽得宽得多,它要在整套自动驾驶栈里同时承担推理、规划、执行三件事,而且每件事都要能向外解释。这一点对车规级合规很关键:监管部门问你为什么变道,模型得能掏出一条因果链,而不是甩一组黑盒坐标。
核心特性梳理一下:
- 基于 NVIDIA Cosmos 训练,长尾场景下的逻辑推理、三维空间感知、轨迹预测能力全面增强;
- 全车环视:从前置摄像头升级到 360 度全景感知,覆盖前、侧、后视野——这是变道、并线、复杂路口必备的;
- 元动作输出:除了输出轨迹和因果链,还能预判"礼让""变道""停车"这类高层级驾驶意图,给下游规划模块当锚点;
- 推理式自动标注 + 2D 目标定位:把过去要数月的标注周期压到几天,这一项对数据团队的成本结构影响巨大;
- 优化的因果链与轨迹输出:专门针对模仿学习吃力的罕见、长尾场景做了强化。
说白了,Alpamayo 2 Super 不是给你装到车里直接跑的——它太大了。它的角色是教师模型,通过知识蒸馏压成小模型,部署到 DRIVE Hyperion 平台的 DRIVE AGX Thor 车载芯片上。
教师模型这条线,英伟达想得很清楚
英伟达在 VLA 这件事上的打法,跟 Llama 在大语言模型上的打法神似——自己做最强的开源基础模型,让整个生态拿去后训练、蒸馏、定制。
你看这条产品线就清楚:
Alpamayo 1 Nano (10B) —— 早期试水
Alpamayo 1.5 Nano (10B) —— 迭代版
Alpamayo 2 Super (32B) —— 教师模型,本次主角
Nano 系列负责落地、上车跑实时;Super 负责"知道得最多",再把知识下放给 Nano。每家车企不用从零开始训一个 VLA 基础模型——这件事的成本和数据门槛,除了英伟达自己和少数几家大厂,基本没人玩得动。
这套逻辑的潜台词是:英伟达不想只卖芯片,它想顺手把自动驾驶的"操作系统层"也定义掉。 模型开源给你,但训练用 Cosmos,仿真用 Omniverse,闭环用 AlpaGym,部署在 DRIVE Thor 上——整条链路你绕不开它。
配套发布的三件套,才是真正的护城河
模型本身只是台面上的主角,真正撑起 Alpamayo 2 Super 的,是同步发布的三套基础设施。这部分常被一笔带过,但对开发者来说才是干货。
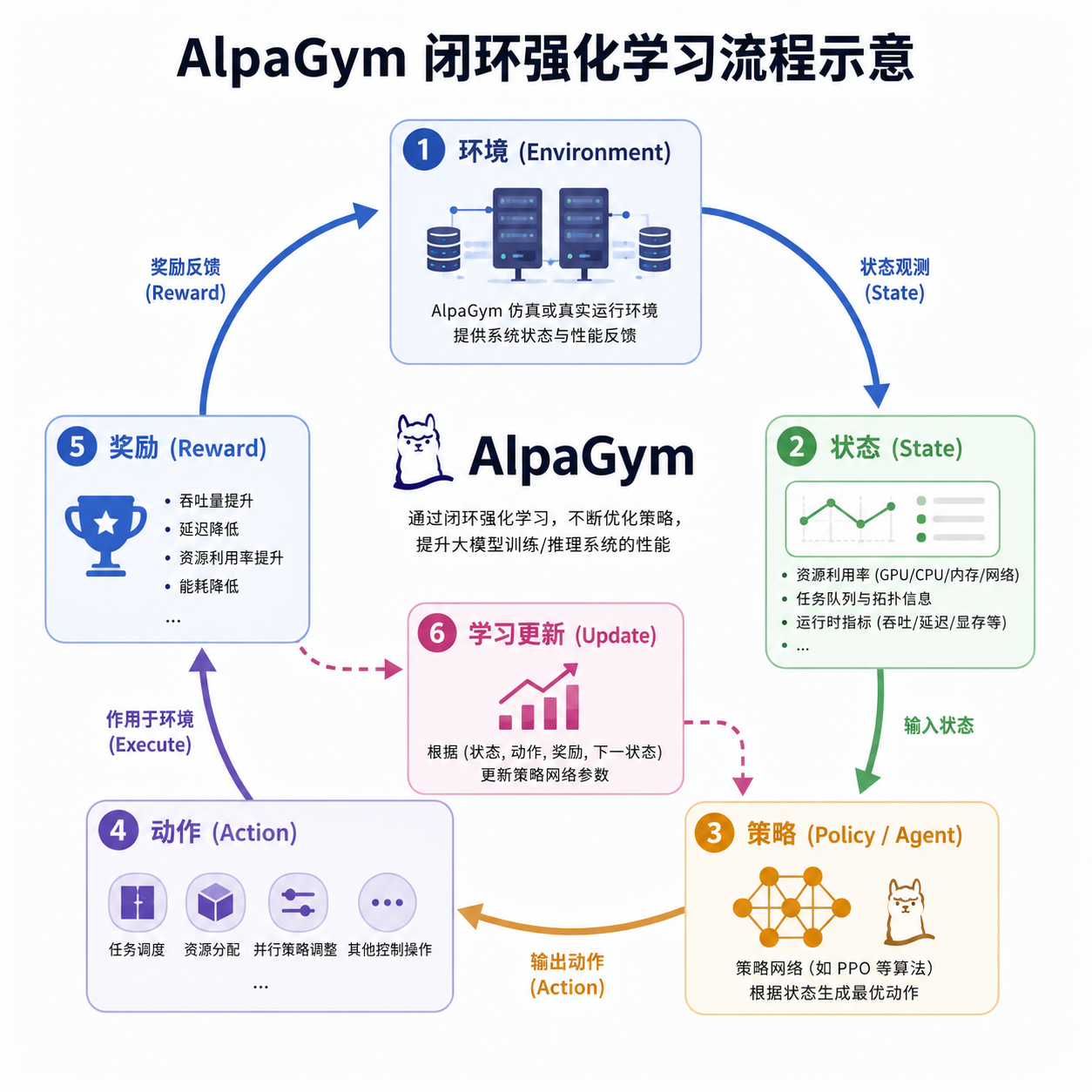
AlpaGym:闭环强化学习平台
现在大多数自动驾驶训练还是"开环"的——拿历史录制的视频喂模型,模型预测下一步动作,跟真值比对,算 loss。问题是真车不是这么开的,每一次刹车、转向都会改变后续的环境状态。
AlpaGym 干的事就是把训练搬进闭环:模型在 AlpaSim 里持续做"决策—感知"循环,车辆的每一个动作都会实时改变仿真环境。这套架构基于 AlpaSim 微服务和 Omniverse NuRec 搭建,强化学习的吞吐被拉到了一个量级。
开环到闭环,是自动驾驶模型训练最大的一道坎,AlpaGym 把这道坎做成了开源框架。
OmniDreams:世界模型,专攻长尾
L4 最难的是什么?不是 99% 的常见场景,是那 1% 的罕见情况——前车突然掉货、施工锥摆得稀奇古怪、暴雨夜间逆光。这种数据真实路采几乎采不到。
OmniDreams 是个生成式世界模型,目标就是大规模仿真各类长尾驾驶场景。和 NuRec 搭配使用:NuRec 负责把真实车队跑过的场景做神经重建,OmniDreams 在重建的世界里生成各种变体。一段真实路采可以衍生出成百上千个"如果当时……"的训练样本。
Omniverse NuRec:神经重建
NuRec 的逻辑接近 NeRF 的工程化版本——基于真实车队的行驶数据做三维重建,再在重建场景里批量生成合成训练数据。英伟达把这一能力同样以智能体技能的形式开放给开发者,可以通过 NVIDIA Agent Toolkit 调用。
一个被忽略的细节:因果链自动标注开源了
英伟达这次还在 GitHub 上扔了一个东西——因果链自动标注流程。
这个工具能基于原始行车视频,自动生成带决策依据和因果关联的标注数据,全程无需人工参与。对做具身推理模型的人来说,这是核心训练资产。传统人工标因果链——"模型为什么减速?因为前方 30 米有行人即将横穿"——这种描述只能靠人写,贵且慢。把它自动化,意味着推理 VLA 的数据飞轮终于转得起来了。
这一步开源的实际影响,可能比模型本身还大。
国内厂商的接入情况
英伟达在发布会上点名提到,比亚迪、吉利、极氪、小米、小马智行等中国主流车企和自动驾驶公司,均已采用或正在基于 NVIDIA Hyperion 平台开发智驾。
这个名单值得琢磨。它意味着即便国内有自研芯片和自研模型的声音,在 L4 Robotaxi 这条战线上,主流玩家还是选择了英伟达的全栈方案。原因不难理解:自己从零搭 VLA 基础模型,数据、算力、人才门槛都太高,而 Alpamayo 这条开源路径几乎把入场费降到了"做后训练"的水平。
发布节奏与可用性
按官方时间表:
- 推理代码:今年夏季上线 GitHub
- 模型权重:同步发布在 Hugging Face
- 因果链自动标注工具:已在 GitHub 开源
- 后训练脚本:随开源平台一起提供,方便基于自有数据集做二次适配
Alpamayo 系列自首次发布以来下载量已接近 40 万次,并刚刚拿下台北 COMPUTEX 的最佳选择奖(车载技术与智能座舱类别)。从社区热度看,这条线在自动驾驶圈已经形成了实质性的影响力。
一点判断
VLA 这个概念这两年被讲得有点泛,从机器人到自动驾驶都在用。英伟达这次发的 Alpamayo 2 Super,技术上没有特别花哨的新结构,但它把"推理 VLA"该有的样子比较完整地拼出来了:多模态感知 + 元动作输出 + 因果链解释 + 闭环强化学习,再加上从数据采集到车载部署的整条工具链。
对车企来说,这是个不太容易拒绝的礼包:你不用接受英伟达定义的全部范式,但只要你做 L4,你大概率绕不开它的某一段。
对开发者来说,更现实的价值在于:320 亿参数的开源 VLA 教师模型摆在那儿,加上配套的标注工具和闭环训练框架,做端到端自动驾驶研究的门槛被显著拉低了。哪怕你只是想拿它做点视频理解、场景生成的副业,这套权重也值得跑一跑。
物理 AI 的 ChatGPT 时刻有没有到,还不好说。但起码在自动驾驶这条线,开源 VLA 的工具箱已经被英伟达单方面填满了。剩下的事,看车企怎么接。
参考来源
- IT之家:英伟达推出 Alpamayo 2 Super 开源推理模型,助力 L4 自动驾驶研发 —— 发布会主要信息源,含完整核心特性列表
- Hugging Face:NVIDIA Alpamayo 系列模型主页 —— 模型权重发布平台
- GitHub:NVIDIA 开源自动驾驶工具链 —— 推理代码与因果链自动标注流程开源仓库