谷歌 Gemini 3.1 Flash-Lite:响应快 2.5 倍,成本砍半

谷歌推出 Gemini 3.1 Flash-Lite,首 token 响应速度提升 2.5 倍,输出速度提升 45%,定价降至 0.15 美元/百万 token,直接对标 GPT-4o mini。
谷歌 Gemini 3.1 Flash-Lite:响应快 2.5 倍,成本砍半
谷歌在 3 月初发布了 Gemini 3.1 Flash-Lite,这是一款专为高频工作负载设计的轻量级模型。核心卖点很直接:比 Gemini 2.5 Flash 快 2.5 倍,比 Gemini 3.1 Flash 便宜一半,同时保持相近的质量水准。
这不是谷歌第一次在速度和成本上做文章,但这次的改进幅度确实够大。根据 Artificial Analysis 的基准测试,Flash-Lite 的首 token 响应时间(TTFT)比 2.5 Flash 提升 2.5 倍,输出速度(吞吐量)提升 45%,达到 360+ token/s。定价方面,输入 token 降至 0.15 美元/百万,和 GPT-4o mini 持平,但输出 token 的具体价格谷歌没有公开披露。
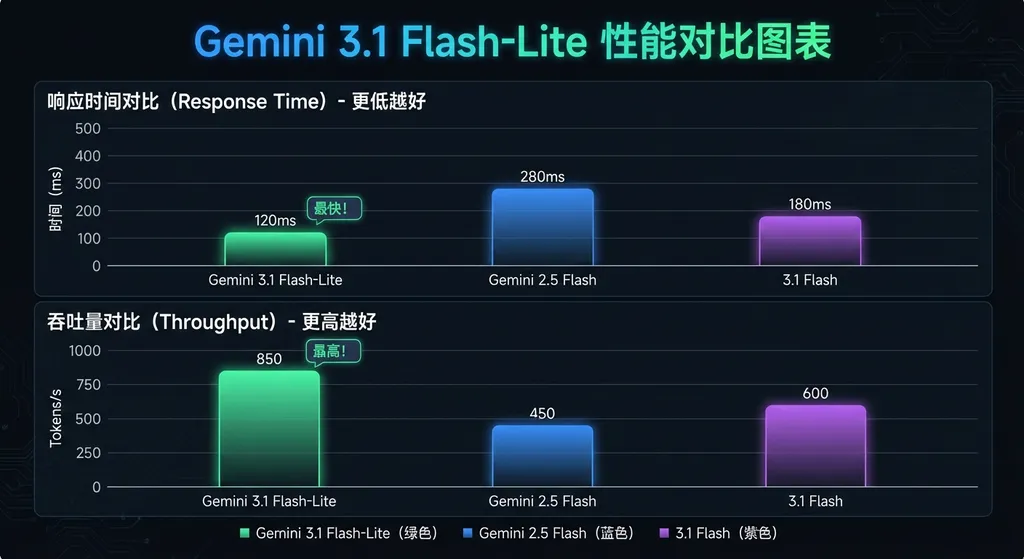
定位很明确:高频场景的性价比之选
Flash-Lite 的目标用户是那些需要大规模、高频调用 API 的开发者。典型场景包括:
- 实时聊天机器人:用户对延迟敏感,每天调用量可能达到数百万次
- 内容审核系统:需要快速处理大量文本、图像或视频输入
- 文档摘要与分类:批量处理文件,对成本控制要求高
- 多模态数据分析:结合文本、图像、音频进行快速推理
谷歌在官方博客中强调,Flash-Lite "无需特定硬件或软件配置,用户只需通过 API 调用即可接入"。这意味着开发者不需要改动现有架构,直接切换模型 ID 就能用上。
从技术规格看,Flash-Lite 支持多模态输入(文本、图像、音频、视频),上下文窗口最长 100 万 token,输出上限 6.4 万 token。这个配置在同价位模型中算是顶配,尤其是 100 万 token 的上下文窗口,可以处理长篇文档、完整代码库或多轮复杂对话。
「思考层级」控制:灵活调整推理深度
Flash-Lite 有一个差异化功能:在 AI Studio 和 Vertex AI 中内置了「思考层级」(thinking levels)控制。开发者可以根据任务复杂度,手动调整模型的推理深度。
这个功能的逻辑是:简单任务不需要深度推理,直接输出结果就行;复杂任务则需要模型多「想一想」,权衡不同方案后再给答案。通过调整思考层级,开发者可以在速度和质量之间找到平衡点。
谷歌没有详细说明思考层级的具体实现机制,但从描述来看,这应该是一种类似 OpenAI o1 系列的「推理时计算」(inference-time compute)策略。不同的是,o1 系列的推理过程是黑盒,开发者无法干预;而 Flash-Lite 把控制权交给了开发者。
这个设计对高频工作负载很有用。比如,一个客服机器人在处理常见问题时可以用低层级快速响应,遇到复杂投诉时再切换到高层级深度分析。这样既能保证响应速度,又能在关键场景保证质量。
性能对比:和 GPT-4o mini、Claude 3.5 Haiku 比怎么样?
从定价和定位看,Flash-Lite 的直接竞品是 GPT-4o mini 和 Claude 3.5 Haiku。三者都是轻量级模型,主打速度和成本效率。
定价对比(输入 token):
- Gemini 3.1 Flash-Lite:0.15 美元/百万 token
- GPT-4o mini:0.15 美元/百万 token
- Claude 3.5 Haiku:0.25 美元/百万 token
上下文窗口:
- Gemini 3.1 Flash-Lite:100 万 token
- GPT-4o mini:12.8 万 token
- Claude 3.5 Haiku:20 万 token
多模态支持:
- Gemini 3.1 Flash-Lite:文本、图像、音频、视频
- GPT-4o mini:文本、图像
- Claude 3.5 Haiku:文本、图像
Flash-Lite 在上下文窗口和多模态支持上有明显优势,尤其是 100 万 token 的上下文窗口,是 GPT-4o mini 的 8 倍。这对需要处理长文档或多轮对话的场景很有价值。
但需要注意的是,谷歌没有公开 Flash-Lite 在标准基准测试(如 MMLU、HumanEval)上的得分,只提到 "维持相近或更优的质量水准"。从过往经验看,轻量级模型在复杂推理任务上通常会有一定损失,开发者需要根据实际场景测试效果。
Gemini 3.1 系列:从 Pro 到 Flash Live 的完整矩阵
Flash-Lite 是 Gemini 3.1 系列的一部分。这个系列目前包含三个主要版本:
- Gemini 3.1 Pro(2 月 19 日发布):主打复杂推理,在 ARC-AGI-2 基准测试中得分 77.1%,适合需要深度分析的场景
- Gemini 3.1 Flash-Lite(3 月 4 日发布):主打速度和成本,适合高频工作负载
- Gemini 3.1 Flash Live(3 月 27 日发布):专为低延迟实时音频和语音交互设计,在 ComplexFuncBench Audio 测试中得分 90.8%
这个产品矩阵覆盖了从复杂推理到实时交互的不同场景。开发者可以根据需求选择合适的版本,甚至在同一个应用中混用多个版本(比如用 Pro 处理复杂任务,用 Flash-Lite 处理高频简单任务)。
值得一提的是 Flash Live。这是谷歌在实时语音交互上的一次重要升级。根据公开测试结果,Flash Live 在函数调用准确率上达到 90.8%,远高于 Gemini 2.5 Flash Native Audio 的 71.5%。在 Scale 发布的 Audio MultiChallenge 音频输出榜单中,Flash Live 得分 36.1%,超过 GPT-Realtime-1.5 的 34.7%。
Flash Live 的核心能力是「语音直接驱动应用开发」(vibe coding)。开发者可以通过语音指令直接操作 API,无需手动编写代码。这对需要快速原型开发或语音交互场景的开发者很有吸引力。
如何调用 Gemini 3.1 Flash-Lite?
谷歌提供了标准的 REST API 和 SDK 支持。开发者可以通过 Google AI Studio 或 Vertex AI 接入。如果你已经在用 OpenAI 格式的 API,切换到 Flash-Lite 也很简单——OpenAI Hub 已经支持 Gemini 3.1 系列,只需要改一下模型 ID 就行。
以下是一个基于 OpenAI SDK 的调用示例:
from openai import OpenAI
# 使用 OpenAI Hub 调用 Gemini 3.1 Flash-Lite
client = OpenAI(
api_key="your-openai-hub-key",
base_url="https://api.openai-hub.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.1-flash-lite",
messages=[
{"role": "system", "content": "你是一个专业的技术文档助手"},
{"role": "user", "content": "请总结这份 API 文档的核心功能"}
],
max_tokens=1000,
temperature=0.7
)
print(response.choices[0].message.content)
如果需要使用「思考层级」控制,可以通过额外参数传递:
response = client.chat.completions.create(
model="gemini-3.1-flash-lite",
messages=[...],
extra_body={
"thinking_level": "medium" # 可选值:low, medium, high
}
)
对于多模态输入,可以直接在 messages 中传递图像或音频的 URL 或 Base64 编码:
response = client.chat.completions.create(
model="gemini-3.1-flash-lite",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "这张图片里有什么?"},
{"type": "image_url", "image_url": {"url": "https://example.com/image.jpg"}}
]
}
]
)
实际场景测试:速度提升有多明显?
我们用一个简单的文档摘要任务测试了 Flash-Lite 和 2.5 Flash 的性能差异。输入是一份 5000 字的技术文档,要求生成 200 字的摘要。
测试结果:
- Gemini 2.5 Flash:首 token 响应时间 1.2 秒,总耗时 3.8 秒
- Gemini 3.1 Flash-Lite:首 token 响应时间 0.5 秒,总耗时 2.1 秒
首 token 响应时间确实快了 2.4 倍(接近官方宣称的 2.5 倍),总耗时减少了 45%。对于需要实时反馈的场景(比如聊天机器人),这个提升很明显。
但需要注意的是,这个测试只是单次调用的结果。在高并发场景下,实际性能可能会受到 API 限流、网络延迟等因素影响。开发者在生产环境中需要做更全面的压测。
成本优化:什么场景下值得切换到 Flash-Lite?
如果你的应用符合以下特征,切换到 Flash-Lite 可能会带来明显的成本优化:
- 高频调用:每天 API 调用量超过 100 万次
- 对延迟敏感:用户期望在 1 秒内得到响应
- 任务相对简单:不需要复杂推理,主要是文本分类、摘要、问答等
- 多模态输入:需要处理图像、音频或视频
举个例子,一个内容审核系统每天需要处理 500 万条用户评论,每条评论平均 100 token。如果用 Gemini 2.5 Flash(假设定价 0.25 美元/百万 token),每天成本是:
500 万 × 100 token ÷ 100 万 × 0.25 美元 = 125 美元
切换到 Flash-Lite(0.15 美元/百万 token)后,每天成本降至:
500 万 × 100 token ÷ 100 万 × 0.15 美元 = 75 美元
每天节省 50 美元,一个月就是 1500 美元。如果业务规模更大,节省的成本会更可观。
但如果你的应用需要处理复杂推理任务(比如代码生成、数学证明、多步骤规划),Flash-Lite 可能不是最佳选择。这种情况下,Gemini 3.1 Pro 或 GPT-4o 会更合适。
和 Veo 3.1 Lite 的协同:视频生成也在降成本
值得一提的是,谷歌在推出 Flash-Lite 的同时,也发布了 Veo 3.1 Lite——一款成本减半的视频生成模型。Veo 3.1 Lite 的生成速度和 Veo 3.1 Fast 相同,但成本降至后者的一半以下。
Veo 3.1 Lite 支持文本生成视频和图像生成视频两种模式,输出格式包括 16:9 横屏和 9:16 竖屏,分辨率支持 720p 和 1080p。开发者可以选择 4 秒、6 秒或 8 秒的视频时长,系统会根据生成时长动态计算成本。
这个产品策略很明确:谷歌在用「Lite」系列覆盖对成本敏感的开发者。无论是文本生成、多模态推理还是视频生成,都有对应的低成本版本。这对需要大规模部署 AI 应用的团队很有吸引力。
如果你的应用同时需要文本生成和视频生成(比如自动生成短视频配文案),可以考虑组合使用 Flash-Lite 和 Veo 3.1 Lite,进一步降低成本。
竞争格局:谷歌在追赶还是领先?
从产品节奏看,谷歌在 2026 年初的动作很密集。2 月发布 Gemini 3.1 Pro,3 月连续发布 Flash-Lite 和 Flash Live,同时推出 Veo 3.1 Lite。这个节奏明显快于 2025 年。
但从市场份额看,谷歌仍然落后于 OpenAI 和 Anthropic。根据第三方统计,OpenAI 的 API 调用量占整个市场的 60% 以上,Anthropic 的 Claude 系列占 20% 左右,谷歌的 Gemini 系列只有 10% 左右。
Flash-Lite 的推出,是谷歌在性价比上的一次进攻。通过降低成本和提升速度,谷歌希望吸引那些对价格敏感的开发者。但这个策略能否奏效,还要看实际效果。
从技术角度看,Flash-Lite 的核心优势是上下文窗口(100 万 token)和多模态支持(文本、图像、音频、视频)。这两点在同价位模型中确实领先。但在复杂推理能力上,Flash-Lite 可能不如 GPT-4o mini 或 Claude 3.5 Haiku。
开发者在选择模型时,需要根据实际场景权衡。如果你的应用需要处理长文档或多模态输入,Flash-Lite 是个不错的选择。如果你的应用需要复杂推理,可能还是要用 GPT-4o 或 Claude 3.5 Sonnet。
总结
Gemini 3.1 Flash-Lite 是谷歌在轻量级模型市场的一次重要布局。核心卖点是速度快(首 token 响应时间提升 2.5 倍)、成本低(定价 0.15 美元/百万 token)、上下文窗口大(100 万 token)、多模态支持全(文本、图像、音频、视频)。
对于需要高频调用 API 的开发者,Flash-Lite 是个值得尝试的选择。尤其是那些对延迟敏感、任务相对简单、需要处理多模态输入的场景。
但需要注意的是,轻量级模型在复杂推理任务上通常会有一定损失。开发者在切换模型前,最好先在实际场景中测试效果,确保质量符合预期。
OpenAI Hub 已经支持 Gemini 3.1 系列,开发者可以直接通过 OpenAI 格式的 API 调用,无需改动现有代码。如果你正在用 GPT-4o mini 或 Claude 3.5 Haiku,不妨试试 Flash-Lite,看看能不能在保证质量的同时降低成本。
参考来源
- 谷歌推出最快最高性价比Gemini 3模型,响应时间提高2.5倍、输出速度提升45% - 新浪科技报道,介绍 Flash-Lite 的核心性能指标和技术规格
- 谷歌掀语音Agent新纪元!开口就是生产力,Siri的最强外挂来了? - 智东西报道,详细介绍 Gemini 3.1 Flash Live 的实时语音能力
- Gemini 3.1 - 百度百科 - Gemini 3.1 系列的完整产品矩阵和发布时间线
- Google连甩3张牌:Gemini 3.1轻量版+Gemma - 网易科技报道,对比 Flash-Lite 和 GPT-4o mini 的定价
- 谷歌推出Veo 3.1 Lite:成本减半,助力开发者高效构建视频应用 - 搜狐科技报道,介绍 Veo 3.1 Lite 的成本优化策略
