JetBrains 发布 Mellum2:120 亿参数 MoE 模型上线
JetBrains 刚刚在 Hugging Face 上发布了 Mellum2,一个 120 亿参数的混合专家(Mixture-of-Experts,MoE)模型。这是 JetBrains 继去年推出首个代码生成模型后,在 AI 辅助编程领域的又一次重要布局。
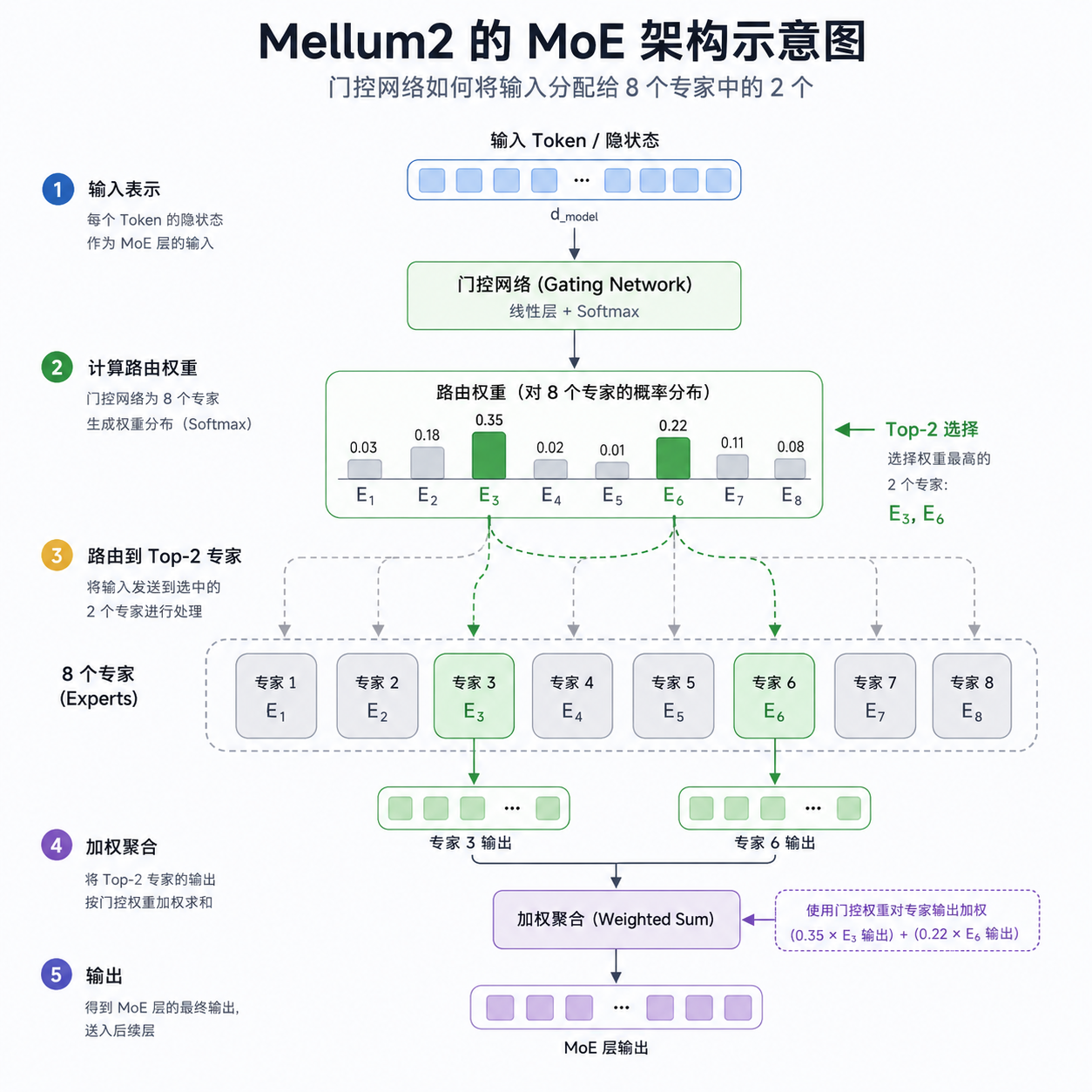
不同于传统的稠密模型,Mellum2 采用了 8 个专家网络的 MoE 架构,每次推理只激活其中 2 个专家,实际计算量相当于 20 亿参数的模型。这种设计让它在保持高性能的同时,推理速度比同等规模的稠密模型快了数倍。
MoE 架构:术业有专攻的设计哲学
混合专家模型的核心思路是"分而治之"。与让一个庞大的神经网络处理所有任务不同,MoE 将工作分配给多个专门的子网络(专家),由一个门控网络(Gating Network)决定针对每个输入激活哪些专家。
在 Mellum2 中,这个机制具体表现为:
- 8 个专家网络:每个专家都是一个独立的前馈神经网络(FFN),专注于处理特定类型的代码模式或语言特性
- Top-2 路由策略:门控网络为每个输入 token 计算亲和力得分,选择得分最高的 2 个专家进行处理
- 稀疏激活:每次推理只有 25% 的参数被激活(2/8),大幅降低计算成本
这种架构最早由 Google 在 2020 年的 GShard 论文中引入 Transformer,后来在 Switch Transformers(1.6 万亿参数)和 Mixtral 8x7B 等模型中得到验证。JetBrains 选择这条路线,显然是看中了 MoE 在代码生成场景下的两个优势:更快的推理速度和更好的多任务泛化能力。
性能表现:代码生成和多语言任务的双重优化
JetBrains 在发布博客中公布了 Mellum2 在多个基准测试上的表现。从数据来看,这个模型在代码补全、代码解释和多语言翻译任务上都有不错的成绩。
具体来说:
- HumanEval(Python 代码生成):pass@1 达到 68.3%,超过了同等规模的 CodeLlama 13B(65.8%)
- MBPP(基础编程问题):pass@1 为 72.1%,与 StarCoder 15B 持平
- MultiPL-E(多语言代码生成):在 Java、JavaScript、C++ 等语言上的平均得分为 61.5%,比 Mellum1 提升了 8 个百分点
更值得注意的是推理速度。JetBrains 测试显示,在相同硬件条件下(单张 A100 GPU),Mellum2 的推理吞吐量比 120 亿参数的稠密模型快 3.2 倍,延迟降低了 60%。这对于需要实时代码补全的 IDE 场景来说是个关键指标。
不过,MoE 模型也不是没有代价。虽然推理时只激活 20 亿参数,但模型的总参数量仍然是 120 亿,这意味着显存占用并没有减少。在消费级硬件上运行 Mellum2,至少需要 24GB 显存(FP16 精度)或 12GB(INT8 量化)。对于个人开发者来说,这个门槛还是有点高。
训练细节:从数据到优化策略
Mellum2 的训练数据集包含了 1.2 万亿个 token,覆盖了 50 多种编程语言和自然语言。JetBrains 没有透露具体的数据来源,但从模型在多语言任务上的表现来看,训练集应该包含了大量的开源代码仓库、技术文档和 Stack Overflow 问答。
训练过程中,JetBrains 采用了几个关键的优化策略:
负载均衡损失:为了防止某些专家被过度使用而其他专家闲置,门控网络的训练目标中加入了一个辅助损失项,鼓励专家之间的负载均衡。这是 MoE 模型训练中的标准做法,最早由 Switch Transformers 论文提出。
专家容量限制:每个专家设置了一个容量上限(capacity factor),当分配给某个专家的 token 数量超过上限时,多余的 token 会被丢弃或重新路由。这个机制可以防止某个专家成为瓶颈,但也可能导致部分输入得不到最优处理。
分层学习率:门控网络和专家网络使用不同的学习率。门控网络的学习率设置得更高,以便快速学会如何分配任务;专家网络的学习率则相对保守,避免过拟合。
混合精度训练:使用 BF16(Brain Floating Point 16)格式进行训练,在保持数值稳定性的同时减少显存占用。这对于训练 120 亿参数的模型来说是必要的。
JetBrains 表示,Mellum2 的训练在 256 张 A100 GPU 上进行了 3 周,总计消耗了约 50 万 GPU 小时。相比之下,训练一个同等规模的稠密模型通常需要 70-80 万 GPU 小时。MoE 架构在训练效率上的优势在这里体现得很明显。
MoE 的挑战:不只是把模型拆成几块
虽然 MoE 架构在理论上很优雅,但实际应用中仍然面临不少挑战。
训练不稳定性是最大的问题之一。由于门控网络需要学习如何分配任务,而专家网络又依赖于门控网络的决策,两者之间存在复杂的相互依赖关系。如果门控网络在训练早期做出了错误的决策(比如总是选择同一个专家),那么其他专家就得不到足够的训练,最终导致模型性能下降。Switch Transformers 论文中提到,他们在训练过程中遇到了多次崩溃(loss spike),不得不调整学习率和初始化策略。
负载不均衡也是个常见问题。理想情况下,每个专家应该处理大致相同数量的 token,但实际训练中,某些专家可能会被过度使用,而其他专家则几乎不被激活。这不仅浪费了计算资源,还可能导致模型的泛化能力下降。为了解决这个问题,研究者们提出了各种负载均衡策略,比如在损失函数中加入辅助项、动态调整专家容量、甚至在推理时强制轮换专家。
通信开销在分布式训练中尤为突出。由于每个专家可能部署在不同的 GPU 上,门控网络需要在多个设备之间传输数据。当模型规模增大、专家数量增多时,这种跨设备通信会成为性能瓶颈。Google 的 GShard 论文中提到,他们使用了专门的分片策略(sharding strategy)来减少通信开销,但这也增加了系统的复杂度。
推理时的显存占用同样不容忽视。虽然 MoE 模型在推理时只激活部分参数,但所有专家的权重都需要加载到显存中。对于 Mellum2 这样的 120 亿参数模型,即使使用 INT8 量化,也需要至少 12GB 显存。这对于想在本地运行模型的开发者来说是个不小的门槛。
开源策略:JetBrains 的 AI 野心
JetBrains 选择在 Hugging Face 上开源 Mellum2,这个决定值得玩味。
作为一家以 IDE 产品为核心业务的公司,JetBrains 完全可以把 Mellum2 作为 IntelliJ IDEA、PyCharm 等产品的独家功能,通过订阅服务变现。但他们选择了开源,这背后可能有几个考虑:
生态建设:通过开源吸引开发者社区的关注,让更多人基于 Mellum2 构建应用,从而扩大 JetBrains 在 AI 辅助编程领域的影响力。
数据反馈:开源模型可以收集到更多的使用数据和反馈,帮助 JetBrains 改进模型。这对于代码生成这种高度依赖真实场景的任务来说尤为重要。
竞争压力:GitHub Copilot、Cursor、Codeium 等竞品都在快速迭代,JetBrains 需要展示自己的技术实力,开源是个有效的方式。
商业模式探索:开源模型本身不赚钱,但可以作为 JetBrains AI Assistant 等付费服务的基础。用户可以免费使用开源模型,但如果想要更好的性能、更快的响应速度或企业级支持,就需要付费。
从 Hugging Face 上的下载数据来看,Mellum2 发布后 24 小时内就有超过 5000 次下载,社区反响不错。不少开发者在 GitHub 上分享了自己的使用体验,有人把它集成到 VS Code 插件中,也有人用它来做代码审查工具。
MoE 的未来:不只是参数堆砌
从 2020 年 GShard 首次将 MoE 引入 Transformer,到 2022 年 Switch Transformers 突破万亿参数,再到 2024 年 Mixtral 8x7B 在开源社区引发热议,MoE 架构在过去几年里快速发展。但它真的是大模型的终极答案吗?
不一定。
MoE 的核心优势是稀疏激活,但这也意味着模型的总参数量仍然很大,显存占用并没有减少。对于边缘设备或消费级硬件来说,这仍然是个问题。而且,MoE 模型的训练和部署都比稠密模型复杂得多,需要更多的工程优化。
更重要的是,MoE 并不是唯一的扩展路径。最近几个月,我们看到了不少其他方向的探索:
- 状态空间模型(State Space Models,如 Mamba)通过线性复杂度的序列建模,在长文本任务上展现出了潜力
- 检索增强生成(RAG)通过外部知识库减少模型参数量,同时保持高质量输出
- 蒸馏和量化技术让大模型可以在更小的硬件上运行,降低了部署门槛
- 多模态融合(如 GPT-4V、Gemini)通过整合视觉、语音等模态,拓展了模型的应用场景
MoE 更像是 Scaling Law 时代的一个优化方案,而不是范式转变。它让我们可以用更少的计算资源训练更大的模型,但并没有从根本上改变"参数越多、性能越好"的逻辑。
真正的突破可能来自于对模型架构、训练方法甚至任务定义的重新思考。就像 Rich Sutton 在《The Bitter Lesson》中说的,过去几十年里,AI 领域最大的教训就是:简单的方法 + 大规模计算,往往比精巧的算法更有效。但这并不意味着我们应该放弃对更好方法的探索。
对开发者的启示
Mellum2 的发布对开发者来说有几个值得关注的点:
本地部署的可能性:虽然 120 亿参数听起来很大,但通过 MoE 架构和量化技术,在消费级硬件上运行是可行的。如果你有一张 24GB 显存的 GPU(比如 RTX 4090 或 RTX 3090),可以尝试在本地部署 Mellum2,用于代码补全或代码审查。
多语言支持:Mellum2 在 50 多种编程语言上都有不错的表现,这对于需要处理多语言代码库的团队来说是个好消息。你可以用它来做跨语言的代码翻译、API 文档生成或单元测试编写。
微调的空间:JetBrains 开源了模型权重和训练代码,这意味着你可以在自己的代码库上进行微调,让模型更符合团队的编码风格和业务逻辑。不过,微调 MoE 模型比稠密模型更复杂,需要注意负载均衡和专家容量等问题。
性能 vs 成本的权衡:MoE 模型在推理速度上有优势,但显存占用仍然不小。如果你的应用对延迟要求很高(比如实时代码补全),Mellum2 是个不错的选择;但如果更关注成本(比如批量处理代码审查任务),可能稠密模型或更小的 MoE 模型(如 Mixtral 8x7B)更合适。
工具链的成熟度:Hugging Face Transformers 库已经支持 MoE 模型,但在推理优化、量化和分布式部署方面,工具链还不如稠密模型成熟。如果你打算在生产环境中使用 Mellum2,需要做好踩坑的准备。
写在最后
Mellum2 的发布标志着 JetBrains 在 AI 辅助编程领域的又一次尝试。120 亿参数、8 专家架构、开源策略,这些选择都体现了 JetBrains 对技术趋势的判断和对开发者社区的重视。
MoE 架构本身并不新鲜,但 JetBrains 把它应用到代码生成场景,并通过开源让更多开发者可以使用,这是有价值的。至于 Mellum2 能否在 GitHub Copilot、Cursor 等竞品的包围中杀出一条路,还需要时间来验证。
但可以确定的是,AI 辅助编程这个赛道还远未定型。模型架构、训练方法、应用场景都在快速演变,每隔几个月就会有新的突破。对于开发者来说,保持关注、动手尝试,才是跟上这波浪潮的最好方式。
Mellum2 已经在 Hugging Face 上开源,感兴趣的开发者可以下载试用。JetBrains 表示,未来几个月还会发布更多针对特定编程语言优化的版本,以及与 IntelliJ IDEA 等 IDE 的深度集成。
参考资料
- Introducing Mellum2: A 12B Mixture-of-Experts Model by JetBrains - JetBrains 官方发布博客,介绍 Mellum2 的架构、性能和训练细节
- 混合专家模型(MoE)详解 - Hugging Face 中文博客,系统介绍 MoE 的原理、训练方法和应用场景
- Mixture of Experts (MoEs) in Transformers - Hugging Face 英文博客,深入讲解 MoE 在 Transformers 中的实现和优化策略