今天,阿里把 Qwen3.7-Plus 推上了百炼 API。距离 Qwen3.7-Max 在阿里云峰会首秀刚过去十来天,3.7 系列的第二只靴子落地——这次主打的是多模态智能体基座。
如果说 5 月 20 日发布的 Qwen3.7-Max 把焦点放在「35 小时自主完成超长程任务、1000+ 次工具调用、芯片内核自我进化」这种重度编程智能体场景,那么今天的 Plus 版本要解决的是另一个问题:当智能体需要看懂屏幕、看懂世界、看懂视频流的时候,谁来做底座。
这次升级到底升了什么
从官方放出的口径和社区拿到 API 之后的反馈,可以拆成三层:
第一层是多模态。 Qwen3-VL-Plus 这一脉的视觉理解能力被进一步整合进 3.7 的主干,思考模式和非思考模式做了融合——这点其实从 3.5 Omni 那一代就在迭代,但之前 VL 和主线模型之间总是有一道缝。3.7-Plus 把这道缝补上了,意味着你不用再为「这个请求要走 VL 模型还是走推理模型」做路由决策,一个 endpoint 全包。
第二层是智能体原生。 3.7 系列从设计阶段就是冲着 Agentic 时代去的,工具调用的稳定性、长上下文下的状态保持、多步规划的鲁棒性,这些是 Max 版本已经验证过的。Plus 继承了这套训练范式,但成本和延迟更适合做规模化部署。Max 适合做"大脑"——一次任务跑几个小时也认了;Plus 适合做"手脚"——高频、并发、要快。
第三层是视觉智能体。 这是最值得关注的一点。过去做 GUI Agent、Computer Use、视频理解 Agent,开发者要么用 Claude 的 Computer Use,要么自己拼 VL + 推理模型。Qwen3.7-Plus 把视觉感知、空间推理、动作规划合到一个模型里,对标的就是 Anthropic 在做的事,但价格会便宜一个量级。
跟 Max 怎么分工
阿里这次的产品线划分思路其实越来越清晰了。我用一张表把 3.7 系列目前的定位摆一摆:
| 版本 | 定位 | 典型场景 | 上下文 |
|---|---|---|---|
| Qwen3.7-Max | 旗舰 / 复杂任务大脑 | 长程编程智能体、芯片优化、科研自动化 | 长上下文,重推理 |
| Qwen3.7-Plus | 多模态 / 通用智能体 | 视觉 Agent、办公自动化、RAG、客服 | 平衡型 |
| Qwen3.7(待发) | 轻量 / 高并发 | 端侧、边缘、批处理 | 优先成本 |
这个分层和 OpenAI 的 o3 / GPT-5 / mini,Anthropic 的 Opus / Sonnet / Haiku 是同构的。阿里这一代终于把"我要哪个模型"这件事讲清楚了——之前 Qwen 系列版本号一多就容易让人迷糊,VL、Coder、Omni、Max、Plus、Flash 一堆后缀,开发者得查表才知道选哪个。
实测一下手感
百炼 API 端今天上午就能调到了,社区里已经有几位开发者跑了基本的视觉理解测试。一个比较有代表性的反馈是:给一张包含复杂表格 + 手写批注 + 印章的扫描件,让它结构化输出,3.7-Plus 的表现比 3.6-Plus 那一代有明显进步,尤其是在「手写体识别 + 上下文关联」这种过去要靠专门 OCR 链路才能搞定的任务上。
另一个让我比较惊讶的点是视频理解的时序推理。给一段 30 秒的操作录屏,让它描述每一步动作并预测下一步意图,3.7-Plus 给出的不是简单的逐帧描述,而是带因果链的——"用户在第 12 秒尝试点击但失败了,因为按钮处于 disabled 状态,所以接下来很可能会去找设置入口"。这种 reasoning 已经接近 GUI Agent 落地所需的水平了。
当然也不全是好消息。在纯文本的复杂推理上,Plus 不如 Max——这本来就是设计取舍。如果你的场景是数学竞赛级别的题目或者需要长链路代码生成,Plus 不是最优解。
在 Arena 上的位置
3.7-Max 发布时阿里就放过数据:在 Arena 全球大模型盲测总榜上超过 Kimi-K2.6、DeepSeek-v4-pro、GLM-5.1,与 GPT、Claude、Gemini 最强模型接近,国产第一。
这个表述其实挺克制——"接近"两个字说明阿里自己也清楚还有差距,但差距已经不是代际级的了。从 Qwen2 到 Qwen3.7,两年多时间,国产闭源旗舰和全球第一梯队的距离从「望尘莫及」缩短到「触手可及」,这是过去 18 个月最大的行业变化之一。
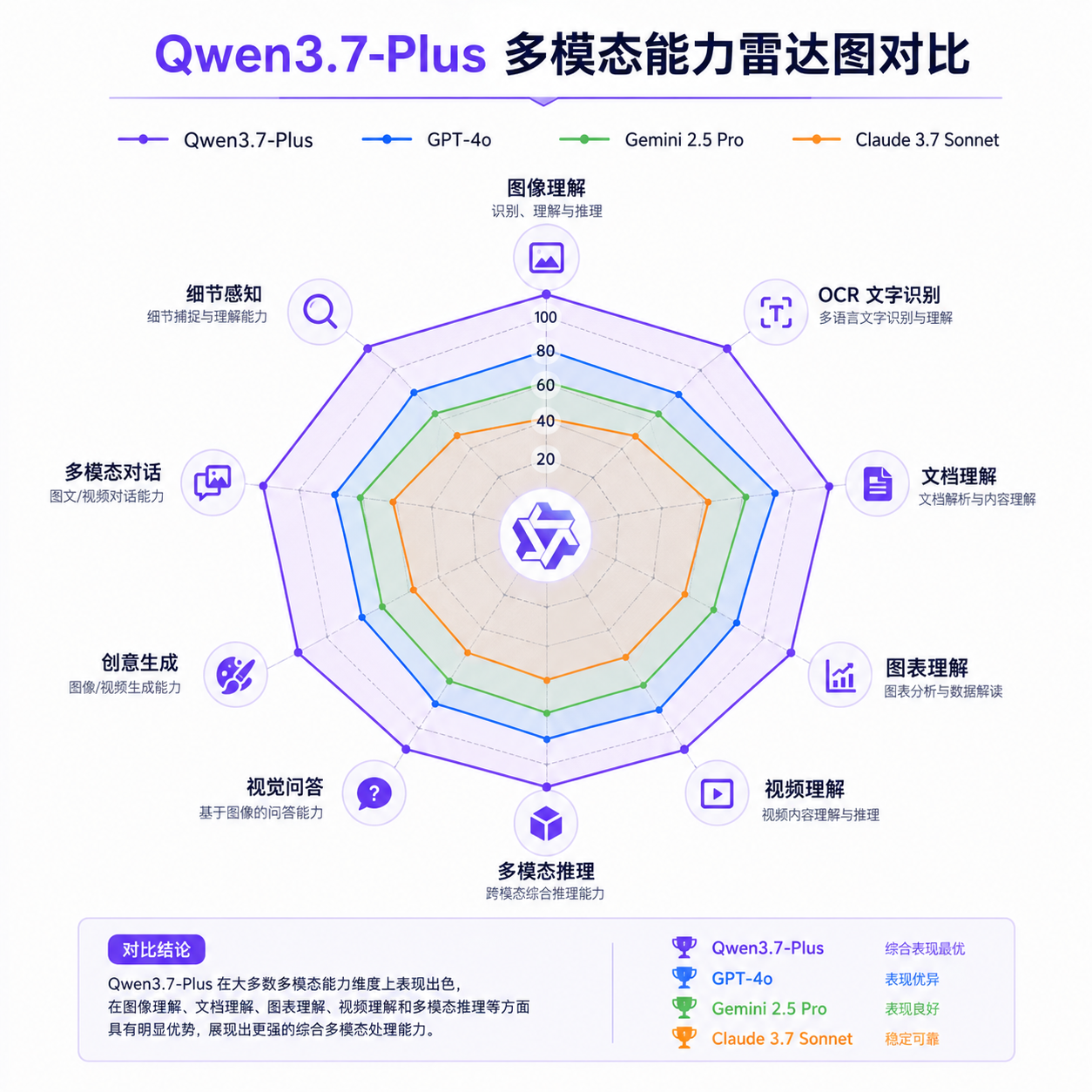
Plus 版本因为定位不同,没有去刷总榜,但在多模态相关的几个细分榜单(MMMU、MathVista、VideoMME 这一类)上,按照阿里给出的内部测试数据,已经追上了 Gemini 2.5 Pro 的水平。第三方复现还需要一些时间。
价格和接入
阿里这次延续了 3.7-Max 发布时的策略——6 月 22 日之前推理后付费 5 折。这个力度对开发者很友好,相当于鼓励大家在窗口期跑通业务再决定要不要长期用。
百炼平台上调用方式和之前的 Qwen 系列保持一致,model 字段换成 qwen3.7-plus 就行。OpenAI 格式兼容层也已经更新,原本接 GPT-4o 的代码改个 base_url 和 model 名就能切。
对于已经用上 OpenAI Hub 这类聚合平台的团队,Qwen3.7-Plus 也在第一时间接入了,国内直连不用绕,一个 Key 同时调 Qwen3.7、GPT-5、Claude、Gemini 这些做 A/B 对比会方便一些——尤其是在选型阶段,跑同一套 prompt 看哪家效果好、成本低,比看 benchmark 数字靠谱得多。
这件事的产业含义
往大了看,阿里这一代 3.7 系列的发布节奏其实很有意思:
- 5 月 20 日: Max 发布,配套发布"芯-云-模型-推理"全栈技术体系。
- 5 月下旬: 周边模型陆续上线,Qwen3.5-LiveTranslate、Wan2.7-Image、Wan2.7-R2V、Qwen3-TTS-Flash 等等。
- 6 月 1 日: Plus 上线,补齐多模态智能体。
这套打法不是「我们发布了一个新模型」,而是「我们发布了一整套智能体时代的基础设施」。模型只是中间一层,下面有自研芯片和云,上面有 Agent 开发平台和应用模板。阿里在用做云的方式做 AI——不卖模型,卖能力栈。
这条路 OpenAI 走得很拧巴(卡在硬件和云依赖上),Anthropic 走不动(没有自己的云),Google 走得最顺(TPU + GCP + Gemini + Workspace),阿里现在走的是 Google 的路线,但本地化做得更彻底。
给开发者的建议
如果你正在做以下方向的产品,今天可以开始评估 Qwen3.7-Plus:
- GUI 自动化 / RPA 智能体 —— 视觉理解 + 工具调用是核心,Plus 是国内目前最对路的选择。
- 多模态 RAG —— PDF、扫描件、表格、图文混排文档的解析与问答,Plus 的 OCR-free 理解能力够用。
- 视频内容理解 / 短视频审核 —— 时序推理能力进步明显。
- 客服 / 对话机器人 —— 如果业务里有用户上传图片的场景(截图报障、商品咨询),Plus 比纯文本模型 + 独立 VL 模型的组合更省心。
反过来,如果你的场景是纯重度推理(代码生成、数学、科研),直接上 Max;纯文本高并发(摘要、翻译、分类),可以等 6 月晚些时候的 Qwen3.7 标准版或者 Flash 版本。
3.7 系列还没出完。按照阿里近一年的节奏,Coder 版本、Omni 版本大概率也在路上。这盘棋阿里下得有耐心。
参考来源
- 千问3.7-Plus 发布讨论 - linux.do —— 社区第一手发布信息和早期开发者实测反馈