谷歌把AI Agent做成了"全天候员工"
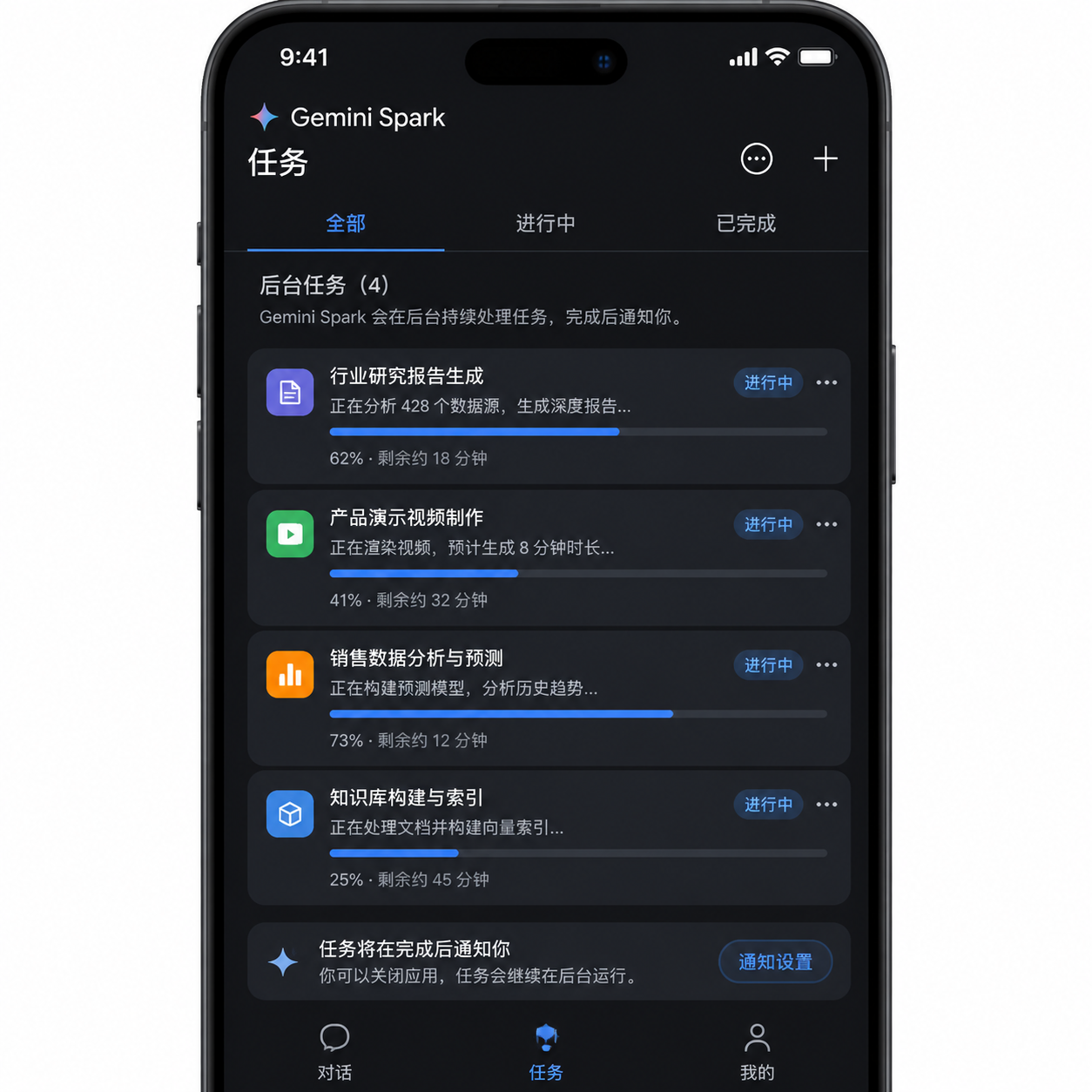
5月19日的Google I/O 2026主题演讲上,谷歌正式发布了Gemini Spark——这是它第一款面向消费者的"常开式"(always-on)AI Agent。简单说,你关机走人,它在云端继续替你干活。
这件事比听上去更重要。过去两年里,所谓AI Agent几乎都是"会话级"的:你打开一个聊天窗口,给它任务,等它跑完,关窗口就结束了。OpenAI的Operator、Anthropic的Computer Use、谷歌自家早期的Project Mariner,本质上都是这个范式——它们是"被调用"的工具,而不是"在岗"的助手。Gemini Spark是第一个把这道边界跨过去的产品。
据《The Verge》上周拿到的实测体验,Spark能跑多步任务:从筛选收件箱、订餐厅,到比价购物、整理日程,整个过程像一个真人助理在后台帮你处理事务。关键的差别在于:你不需要盯着它。
从代号Remy到Gemini Spark
这个产品的开发其实持续了至少一年。它内部代号叫Remy,灵感来自《料理鼠王》里那只藏在厨师帽下指挥厨房的小老鼠——隐喻很到位:在幕后操控,但你感觉不到它的存在。
5月13日到14日的某个夜里,谷歌应用的beta版里"Remy"这个名字悄悄消失了,被换成了"Gemini Spark"。9to5Google的APK Insight最早发现了这次替换,随后一位X用户泄露的onboarding截图坐实了这件事——距离I/O主题演讲只剩五天。
命名层面,Spark比此前候选的"Gemini Agent"要轻盈得多。Agent这个词在2026年已经被用烂了,几乎所有大厂都在做Agent,叫多了反而模糊。Spark带有"火花、触发"的暗示,呼应它"主动出击"的产品定位,这是营销上的小聪明。
技术栈:Gemini 3.x专属变体 + 视觉增强
beta版的模型选择器透露了一些底层信息:
- 基础模型:Gemini 3.x的一个专属变体,针对长时长tool use和多步"thinking"做了优化。这意味着它不是简单调用通用Gemini API,而是一套专门针对Agent场景训练的checkpoint。
- 视觉模型:内部名称"Spark Robin",专门负责在网页浏览过程中解读截图、PDF、复杂表单。这点很关键——长任务里最容易卡住的就是"看不懂页面",比如订机票时遇到一个奇怪的弹窗、购物时验证码挑战,过去的Agent就在这里掉链子。
- 运行位置:目前还没明确Spark是否完全跑在云端。考虑到"24/7运行"这个核心卖点,云端是必然的;但谷歌可能为新一代Googlebook(被定位为Chromebook接班人,搭载Gemini Intelligence)预留了本地组件。
另一个值得关注的细节:Spark和DeepMind的Magic Pointer——那个用Gemini重新定义鼠标光标的项目——大概率会做整合。两者瞄准的都是"AI-first交互范式",技术栈也是同源的。
# Gemini Spark 通过 OpenAI Hub 调用示例(兼容 OpenAI 格式)
from openai import OpenAI
client = OpenAI(
api_key="your-openai-hub-key",
base_url="https://api.openai-hub.com/v1"
)
# 启动一个后台长任务
response = client.chat.completions.create(
model="gemini-spark",
messages=[
{"role": "system", "content": "You are a persistent agent. Continue tasks across sessions."},
{"role": "user", "content": "监控我的收件箱,把发票类邮件自动归档并提取金额到表格"}
],
extra_body={
"agent_mode": "persistent",
"max_steps": 50,
"require_confirmation": ["purchase", "send_email"]
}
)
print(response.choices[0].message.content)
实测:好得有点吓人,但不便宜
《The Verge》的记者上周拿到了Spark的访问权。原话是:"shockingly good at doing things on your behalf"——做事好得让人有点惊讶。多步任务、跨应用切换、需要等待的流程(比如等回邮件再继续操作),Spark处理得都比预期顺畅。
但记者也直接泼了冷水:不确定它的财务成本和隐私代价值不值得。
这两点都很现实:
1. 价格还没公布,但不会便宜。 一个7×24小时跑在谷歌云上的Agent,连接30多个应用、随时待命,背后是持续的算力消耗。无论是包月还是按token,定价大概率会高于Gemini Advanced现有的19.99美元/月档位。业内推测在40-60美元区间是合理的。
2. 隐私权限是核心矛盾。 Spark要真正发挥价值,必须接入你的邮箱、日历、支付、购物账户——这是它能"主动"的前提。但谷歌长期以来在数据使用上的口碑就是一笔糊涂账。Spark网站顶部赫然写着"始终在你的指挥下"、"由你开启"、"重大操作前会与你确认"——这种过度强调反而暴露了用户的疑虑有多大。
监管雷区:欧洲AI Act怎么办
谷歌在Spark的服务条款里明确写了一句很关键的话:"Spark不应被用于医疗、法律、金融或其他形式的专业咨询。"
这不是免责声明那么简单。欧盟AI Act将于2026年8月2日全面生效,它把在金融或医疗领域做出自主决策的AI系统归类为"高风险"。一个能不经确认就完成购买的Agent,技术上正好踩在这条线上。
所以可以预期的是:欧洲版的Spark大概率会比美国版功能更受限——可能去掉自动购物、自动支付,把更多操作降级到"必须人工确认"。这种地区差异化已经在GPT-4o的语音功能、Meta AI的训练数据使用上出现过,Spark只是把它带到Agent层面。
它跟竞品差在哪
横向比一下当下的Agent产品:
| 产品 | 形态 | 持续运行 | 接入应用数 |
|---|---|---|---|
| OpenAI Operator | 浏览器代理 | 否,会话级 | 通用网页 |
| Anthropic Computer Use | 桌面代理 | 否,会话级 | 通用桌面 |
| Microsoft Copilot Agents | 嵌入式 | 部分常驻 | M365生态 |
| Gemini Spark | 云端常驻 | 是,24/7 | 30+应用 |
Spark的差异化点很清楚:"在岗"而非"被调用"。这是产品定位上的一次跳跃,不是功能升级。
但这种差异化也有它的脆弱面。常驻Agent的难点不是技术,是信任——你要把邮箱、日历、信用卡都交给它,前提是你相信它不会乱来。OpenAI做Operator时刻意保守,每一步都要确认;Anthropic做Computer Use也是定位"开发者预览",反复强调实验性质。谷歌这次直接推消费级常驻Agent,胆子是更大,但翻车的成本也更高。
对开发者意味着什么
几个值得关注的方向:
- Agent调度框架会变热。 Spark上线后,多步任务编排、长时记忆、跨会话上下文管理这些工程问题会从研究话题变成生产话题。LangGraph、CrewAI这类框架的需求会上一个台阶。
- "工具调用"标准会被重新审视。 Spark对接30多个应用,谷歌大概率有一套自己的tool calling规范。这会和Anthropic的MCP、OpenAI的Function Calling形成三足鼎立,可能催生新的事实标准。
- 本地Agent的机会窗口在收窄。 Spark的云端模式如果跑通,依赖本地算力的Agent产品差异化会越来越难讲——除非主打"数据不出本机"这条隐私牌。
OpenAI Hub已经支持Gemini系列模型的统一调用,一个Key就能切换GPT、Claude、Gemini、DeepSeek等主流模型,国内直连,兼容OpenAI格式。Spark的API一旦开放,预计也会第一时间适配。
写在最后
Gemini Spark是2026年到目前为止最有产品野心的一次发布。它不是参数更大、benchmark更高的模型,而是一次形态上的跨越——把AI从"工具"变成"在岗员工"。
但它也是矛盾最集中的产品:
- 能力越强,权限越大,风险越高
- 越是"常驻",越是无法回避监管
- 越是"自主",用户对透明度的需求越强
《The Verge》记者那句"不确定值不值得",可能就是大多数普通用户看完发布会后的真实感受。Spark能不能从"演示惊艳"走到"日常依赖",要看接下来三个月谷歌在定价、欧洲版本、隐私机制上怎么落地。
Agent这场仗,从今天开始才算真的打响。
参考来源
- Reddit讨论:Google I/O 2026 Gemini Spark发布 - Reddit社区对Spark发布的实时讨论与实测反馈
- Hugging Face模型库 - Google官方在HuggingFace上的相关模型仓库,可关注Gemini后续开源动态