微软开源 ASSERT:行为规范写完,评测脚本也跟着出来了
开发智能体的人最头疼的环节,大概就是写评测。功能跑通只是第一步,怎么证明它在边界场景下不翻车、不拍马屁、不乱调工具、不给出危险建议——传统做法是手工攒一套测试集,再人肉过 case。微软昨天(6 月 2 日)甩出来的新东西想干掉这件事:一个叫 ASSERT 的开源框架,名字全称是 Adaptive Spec-driven Scoring for Evaluation and Regression Testing,自适应规范驱动评分。
核心动作只有一个:把 PRD、政策文件、System Prompt 这类自然语言写成的行为规范,直接编译成一整套可执行的评估流程。从测试场景、数据集、评估指标,到最终的计分卡,全都自动生成,然后跑在目标模型、应用或者智能体上。
听起来像是又一个 "LLM as Judge" 工具包,但 ASSERT 的设计前提其实有点不一样——它把行为规范当成评估的一等输入,而不是背景资料。这点和过去大多数 eval 框架的思路是反着来的。
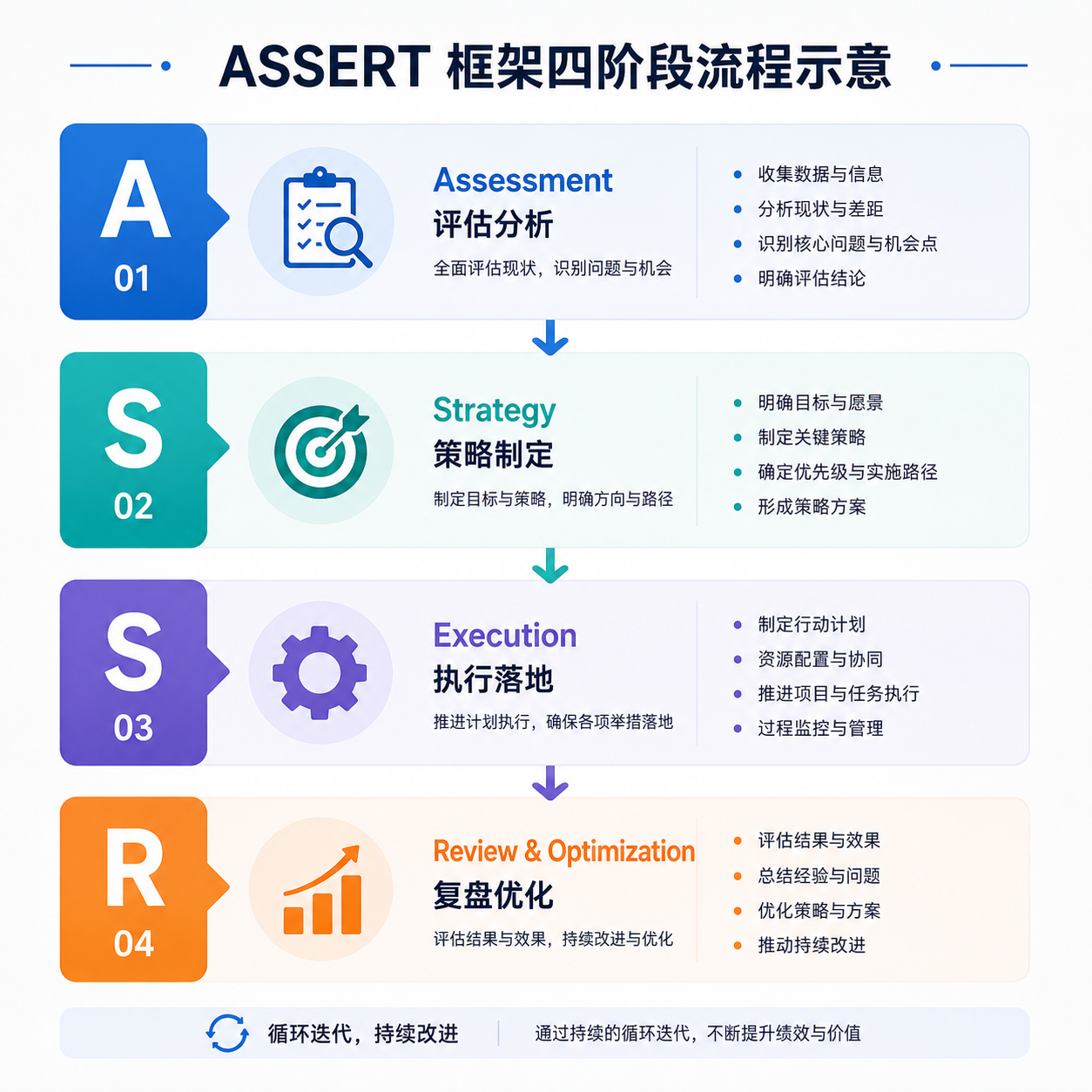
四个阶段:从一段描述到一份计分卡
ASSERT 把评估这件事拆成了四段流水线,每一段都可以独立看、独立改:
第一阶段:规范细化。 给它一段宽泛的行为描述,比如 "客服智能体不应主动承诺折扣",它会先把这种模糊话术拆成明确的概念规范,再进一步转换为一份可编辑的 许可/不许可行为分类体系(taxonomy)。这一步是后续所有测试用例的根。
第二阶段:分层用例生成。 开发者指定几个维度——任务类型、用户角色、可用工具、上下文条件等等——ASSERT 按这些维度做组合,生成分层测试用例。覆盖范围包括:
- 单轮提示(最朴素的一问一答)
- 多轮场景(带上下文的长对话)
- 善意交互(普通用户怎么用)
- 对抗性探测(红队怎么打)
第三阶段:执行与轨迹记录。 把生成的用例怼到目标系统上跑,过程中完整记录每一次工具调用、每一个中间决策。对智能体评估来说这步关键——很多问题不在最终答案,而在中间动作。
第四阶段:评分裁决。 对照前面那份行为分类,对每条轨迹打分,输出包括:通过/不通过标签、判断理由、引用的具体策略条款、以及做出该裁决的具体回合或动作。最后这点很重要,意味着你能直接定位到 "第 3 轮调用 search_db 时违反了规则 4.2",而不是只拿到一个干巴巴的总分。
两项验证:覆盖率明显更高,LLM 判定一致率 80-90%
微软团队做了两组对照来证明这套东西不是花架子。
第一项是覆盖率研究。对比的基线是 "直接从意图描述生成评估集" 这种主流做法。ASSERT 在多个行为类别上覆盖更广,包括社会评分、谄媚(sycophancy)、任务遵循、工具使用规范、不安全健康建议等等。结论是:
- 暴露出更多值得检查的边界 case
- 区分强弱系统的能力更强(强模型和弱模型的得分差距被拉得更开)
- 显现出更多独特的失败模式
第二项是LLM 判定器 vs 人工审核。LLM 当裁判这件事一直是 eval 圈子里的争议点,微软给了一组数:LLM 判定器和人工审核的一致率通常在 80%–90%,而人工标注者之间的一致率大概在 90% 左右。换句话说,LLM judge 已经能逼近人类裁判间的下限,但还没到可以无脑信任的程度——尤其在策略细微差别或高度专业领域,依然得人工兜底。
这个数字其实蛮有参考价值。它没吹 "LLM 判定器和人工完全一致",而是坦白说在哪些场景下还得谨慎。
适用边界:行为定义越清楚,效果越好
微软自己也划了线。ASSERT 最适合行为定义明确、约束清晰的场景——比如有完整 policy 文档、明确的工具白名单、清楚的边界描述。规范写得越细,生成的测试用例越精准。
反过来说,如果你的智能体定位本身就模糊("做一个有用的助手" 这种话术),ASSERT 也救不了你——garbage in, garbage out 这条铁律在评测领域同样成立。
另外几条提醒值得开发者记住:
- 不要把汇总分数当结论。 微软明确说,比起一个聚合得分,收集到的失败案例和操作轨迹才是真正有价值的东西——它们能告诉你系统在哪儿坏了、为什么坏。
- 不能替代人工判断和领域专家评审。 ASSERT 的定位是让评估更快、更明确、更易于迭代,而不是把人类完全踢出环路。
- 不能替代遥测数据。 线上真实流量反馈仍然是不可替代的信号。
放在微软最近这波智能体安全工具里看
ASSERT 不是孤立发布的。把时间线拉开一点,过去几个月微软在 "智能体治理与安全" 这条线上动作密集:
- PyRIT:面向安全研究人员的红队自动化框架,做黑盒发现
- Rampart:基于 PyRIT 构建的工程师向工具,把红队发现转化成可重复的自动化测试,能塞进 CI/CD
- Clarity:在写代码之前介入,审查智能体设计决策的假设前提,把对话以 Markdown 写进仓库的
.clarity-protocol/目录,可以在 PR 里 diff - Evals for Agent Interop:企业级智能体交互性的基准测试入门工具包,聚焦邮件、日历、文档协作
- ASSERT:今天的主角,规范驱动的评估生成
这套组合拳的逻辑很清楚——把 AI 安全和评估从 "上线前的一次性审查" 变成贯穿开发生命周期的工程实践。微软 AI 红队创始人 Ram Shankar Siva Kumar 之前在博客里那句 "AI 安全必须成为一项持续的工程学科,而非定期检查节点",可以看作是这一整条产品线的总纲。
ASSERT 在这个谱系里的位置是 "规范到测试" 这一段的自动化。Clarity 解决 "想清楚要做什么",Rampart 解决 "持续测安全问题",ASSERT 解决 "持续测行为合规",三者其实是互补关系。
跟同类东西比,差异在哪
智能体评估这条赛道不缺玩家。学术界有 IntellAgent 这类基于政策图的对话智能体基准测试框架,做法是从公司政策文档抽政策图,再生成场景。工业界各家大厂也都有自己的内部 eval pipeline。
ASSERT 的差异点主要在两处:
一是把 "行为分类体系" 显式化、可编辑化。 很多框架的 taxonomy 是写死在代码里的,ASSERT 把它当成中间产物暴露出来,你可以人工改、可以版本化、可以 review。这对企业场景里需要走合规流程的团队很重要——你能拿这份分类去和法务、合规对齐,而不是甩一堆生成的测试用例让他们看。
二是"分层用例"的设计。 单轮、多轮、善意、对抗这四个维度的组合,覆盖的不只是 "模型答对没",而是包括 "在恶意压力下还能不能守住规则"。对智能体来说这是必须的,因为智能体的失败往往不在第一轮。
当然,要泼点冷水的话:第一,框架本身高度依赖底层 LLM 的能力,规范细化、用例生成、轨迹评分每一步都在调模型,成本不会低;第二,80-90% 的 judge 一致率虽然不错,但对于高风险领域(医疗、金融、法律)仍然不够,落地时得加一层人工抽检;第三,对抗性测试的强度上限取决于生成模型的 "创造力",真正狡猾的 prompt injection 还是得专业红队来发现。
上手方式
代码已经开源在 GitHub 的 responsibleai/ASSERT 仓库下,项目网站是 aka.ms/AS。整个流程都是 spec-driven 的,你只需要准备好行为规范文本,加上目标系统的接入方式(API 端点或者本地模型),就可以跑起来。
对国内开发者来说,配合 OpenAI Hub 这类聚合平台用比较省事——ASSERT 生成的测试用例需要在多个模型上反复跑、做横向对比,一个 Key 直连 GPT、Claude、Gemini、DeepSeek 等主流模型,对评测场景的迭代效率会高不少,不用为每家模型单独搭一套调用层。
一点判断
智能体评估这件事,过去两年的演进路线已经很清楚了:从 "看准确率" 到 "看行为模式",从 "一次性 benchmark" 到 "持续回归测试",从 "通用题库" 到 "规范驱动的定制化用例"。ASSERT 踩在这条路线的当前节点上,提供的是一个把企业自己的 PRD 和 policy 直接当成评估输入的工程化方案。
它不会让评测这件事变简单——评测从来都不简单——但它把规范、用例、轨迹、裁决这条链路打通了,让迭代的颗粒度可以更细。对那些已经在做企业级智能体落地、有明确合规要求的团队来说,这东西值得拉下来跑一遍。
对个人开发者来说,意义稍微小一点。但里面那套四阶段方法论本身值得借鉴——哪怕你不用 ASSERT,自己手搓评测时按这个顺序走一遍,也比上来就闷头写测试用例靠谱。
参考来源
- IT之家:微软发布 ASSERT 开源框架 - ASSERT 框架的中文介绍,包含四阶段流程和验证研究的详细数据
- GitHub:responsibleai/ASSERT - ASSERT 框架官方开源代码库
- 知乎:LLM-based Agents 评估综述 - 智能体评估方向的综述,包含 IntellAgent 等同类框架对比