微软 AI(MAI)昨晚低调上线了 MAI-Code-1-Flash,一款只有 5B 激活参数的编程专用模型。数字本身不算抢眼,但它在 SWE-Bench Pro 上跑出了 51% 的成绩——要知道这套基准从去年秋天 Scale AI 推出至今,前沿大模型集体卡在 25% 以下,GPT-5 首发时也只有 23.3%。一个 5B 模型把分数翻了一倍多,这事值得认真聊聊。
这也是 MAI 编程线产品第一次正面进入开发者视野。此前 MAI 系列更多停留在 Copilot 内部调用层,没怎么单独露脸。这次 Flash 拿出独立 model card、独立评测、独立定价,意味着微软开始把自家编程模型当成一条可以对外卖的产品线,而不只是 OpenAI 的补充。
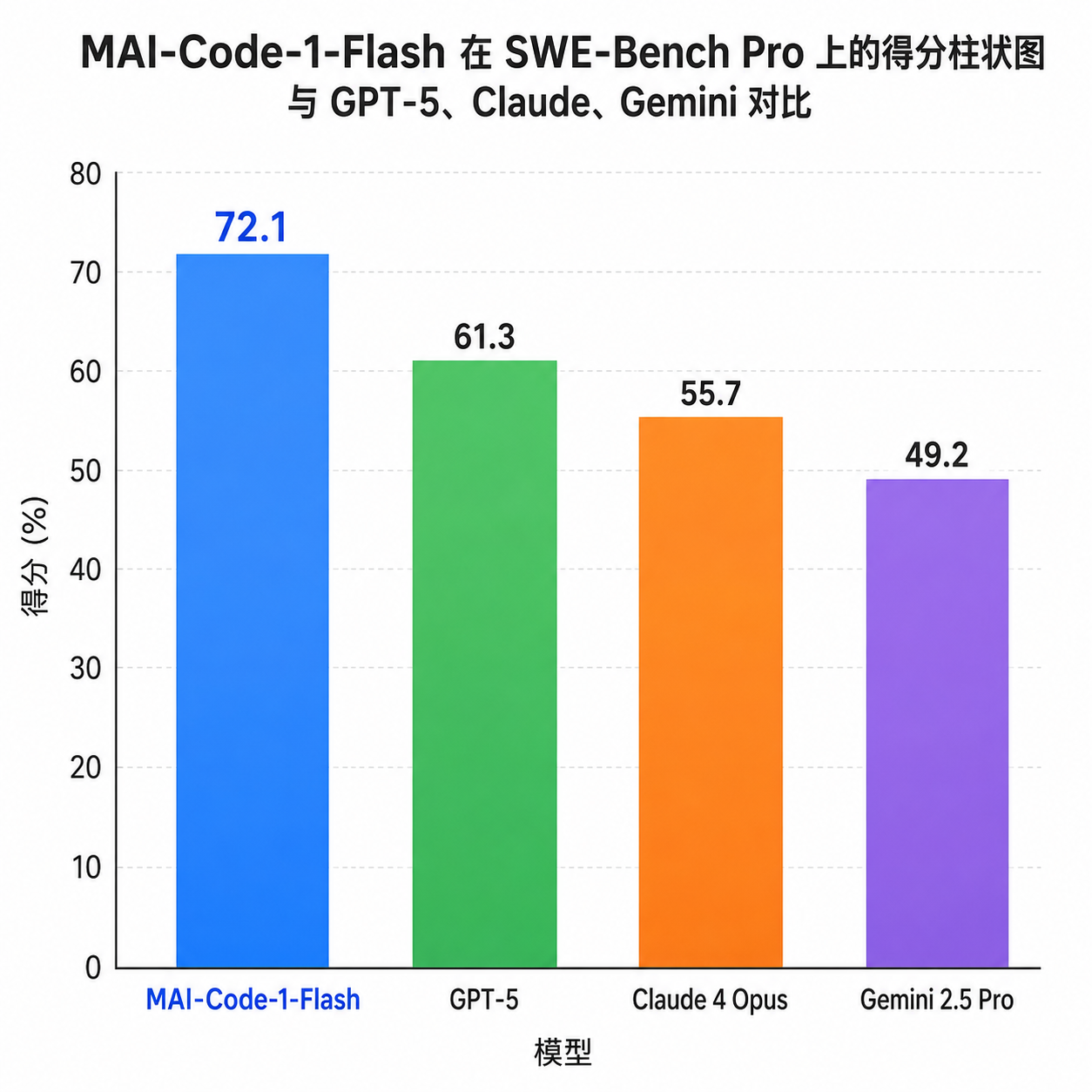
51% 这个数字到底意味着什么
先把基准的背景捋清楚,因为不少人会下意识把 SWE-Bench Pro 跟老版 SWE-Bench Verified 混为一谈。
SWE-Bench Verified 是大家熟悉的那个榜,目前 Gemini 3 Flash、GPT-5.2 Codex 都跑到了 70% 以上,看起来 AI 已经能搞定大部分软件工程任务。但 Scale AI 在 2025 年底推出 SWE-Bench Pro 时点破了一件事:Verified 集已经被各家训练数据反复"洗"过,污染严重,分数虚高。Pro 版换了三件事——任务取自 11 个公开仓库 + 12 个保留仓库 + 18 个商业仓库(其中商业仓库与早期创业公司有正式合作协议),问题更接近企业级真实场景,并且持有抗污染的私有测试集。
结果就是,前沿模型集体回到现实:
- GPT-5(首发):23.3%
- Claude Opus 4.1:低于 25%
- Gemini 2.5:低于 25%
这是当时的天花板。MAI-Code-1-Flash 这次直接报出 51%,超出此前最佳近 28 个百分点,而参数量比那几家小了至少一个量级。
有几个理解角度:
- 不是大模型刷不动 Pro,是没有人专门为它训过。 Flash 显然是冲着这道题去优化的,训练数据里大概率重度采样了真实 Issue + PR + CI 反馈的轨迹。
- 5B 的"激活参数"暗示这是 MoE 架构。MAI 没公开总参数,但从命名习惯看,应该是一个总量更大、激活只有 5B 的稀疏模型。这跟 DeepSeek V3.2、Qwen3-Coder 走的是同一条路。
- 51% 不等于工程能力翻倍。Pro 测的是补丁是否能通过隐藏测试,对长链路、多文件、需要理解业务上下文的任务依然吃力。Flash 的强项更可能集中在 bug 修复、依赖升级、测试补全这类边界明确的子任务。
为什么微软非要自己做一个 5B 编程模型
这是个有意思的战略问题。Copilot 背后跑 GPT-5 不是挺好的?答案是——成本和时延。
GitHub Copilot 的调用量是天文数字,每一次按 Tab、每一次 inline chat 都是请求。用 GPT-5 当主力模型,账面上微软要么自己烧钱补贴,要么涨价。MAI 自己跑过一笔账:在 Copilot 补全这类高频低复杂度场景里,把主力换成 5B 级别的自研模型,单位成本可以压到 GPT-5 mini 的几分之一,时延也从秒级压到几百毫秒。
看一下当前 SWE-Bench Verified 上的性价比对照(数据来自官方 leaderboard):
| 模型 | Verified 分数 | 单次平均成本 |
|---|---|---|
| Gemini 3 Flash (high reasoning) | 75.8% | $0.36 |
| GPT-5.2 Codex | 72.8% | $0.45 |
| Gemini 3 Pro | 69.6% | $0.96 |
| GPT-5 Mini | 56.2% | $0.05 |
GPT-5 Mini 那一栏的 $0.05 就是答案——Copilot 这种产品要的不是榜首,是"够用且便宜"。MAI-Code-1-Flash 的目标位置很清楚,就是把 Mini 这一档干掉,并且不用付 OpenAI 一分钱。
至于 Pro 榜上 51% 那个数字,更像是一份对外的"我们也能打"的证明。微软需要让企业客户相信,自家这条编程模型线不是花瓶。
技术细节里能看出的东西
MAI 官方那篇博客文字不长,但有几处值得开发者留意:
- 激活 5B、MoE 架构:稀疏推理,单 GPU 部署友好,A10/L4 这种推理卡都能跑。
- 长上下文:官方提到 256K context,对应仓库级理解的需求。这是当代编程模型的基本门槛,没有 200K 以上基本没法做 repo-level reasoning。
- 工具调用与 agentic loop:Flash 是直接面向 agent 场景训练的,原生支持文件读写、shell、补丁应用这套 ReAct 风格的循环。这也是它在 SWE-Bench Pro 上分数能拉这么高的关键——Pro 评分的脚手架默认就是 agent 模式。
- 没强调通用对话能力:MAI 这次定位非常专一,model card 上几乎没提 MMLU、GPQA 这些通用指标,就是奔着编程去的。这跟 Anthropic 把 Sonnet 当全能选手的路线不同,更像是 DeepSeek-Coder 早期那种"我就一件事做到底"的打法。
稍微挑刺一下:MAI 这次没公开总参数量,也没说训练数据规模和来源。考虑到 SWE-Bench Pro 的公开集 11 个仓库都在 GitHub 上,模型有没有见过这部分数据是个绕不开的问题。Scale AI 提供了一个保留集和一个商业集来对抗污染,但 MAI 报告里只给了总分,没单独披露商业集成绩——这点希望后续能补上,否则 51% 这个数字含金量会被打折扣。
跟谁正面竞争
5B 这个尺寸的编程模型,市面上对手其实不少:
- Qwen3-Coder-30B-A3B:阿里的 MoE 编程模型,激活 3B,开源,社区生态成熟。
- DeepSeek V3.2 蒸馏版:高推理版本在 Verified 上 70%,但参数量大得多。
- GPT-5 Mini:闭源,Verified 56.2%,$0.05/任务,是 Copilot 当前最直接的对照组。
- Codestral 系列:Mistral 的编程线,欧洲市场用得多。
Flash 现在没明确说是否开源,从微软的产品逻辑判断,大概率是闭源 + 走 Azure AI Foundry 和 GitHub Models 两条渠道。这对开发者来说有点遗憾——5B 这个尺寸本来就是为本地部署设计的,闭源等于自废武功一半。
实际能用上吗
Flash 已经在 GitHub Models 上开放预览,Azure AI Foundry 同步上线。Copilot 端会逐步替换部分场景的底模,用户层无感切换。如果你用 OpenAI Hub 这类聚合平台,MAI-Code-1-Flash 也已经接入,可以直接用统一的 OpenAI 兼容格式调用,方便和 GPT-5、Claude、Gemini 在同一套代码里横向对比。
选型建议:
- 做 IDE 补全 / 内联补丁:Flash 这种小而专的模型是对的方向,时延和成本都吃得下。
- 做 agent 级别的代码任务(Devin 类):还是上 GPT-5.2 Codex 或 Gemini 3 Pro,Flash 的天花板没那么高。
- 做企业内部代码助手:可以考虑 Flash + RAG 的组合,企业仓库私有数据通过检索注入,比硬塞给大模型便宜很多。
一点判断
MAI-Code-1-Flash 真正有意思的地方不是那 51% 分数,而是它标志着微软在编程模型这条线上开始"去 OpenAI 化"。从 Phi 系列到 MAI-1,再到现在的 MAI-Code,路径是清晰的——先做小模型练手,再做通用大模型,再做垂类专用。编程是微软最舍不得让别人卡脖子的场景,因为 Copilot 是它 AI 收入的基本盘。
对开发者的影响是双向的:好处是同尺寸的编程模型质量肉眼可见地在涨,坏处是大家都在卷专项榜,模型的"通用聪明度"和"刷榜能力"会越来越脱钩。下次看到某个新模型在某个 Bench 上爆表,记得先问一句——它的训练集长什么样。
参考来源
- SWE-bench Leaderboards——SWE-Bench 官方榜单,可对比各家模型在 Verified 与 Pro 上的最新成绩
- reddit 上关于 MAI-Code-1-Flash 的讨论——LocalLLaMA 社区对该模型架构与部署成本的早期分析