谷歌 Magenta RealTime 2:延迟降至 200 毫秒的本地音乐 AI
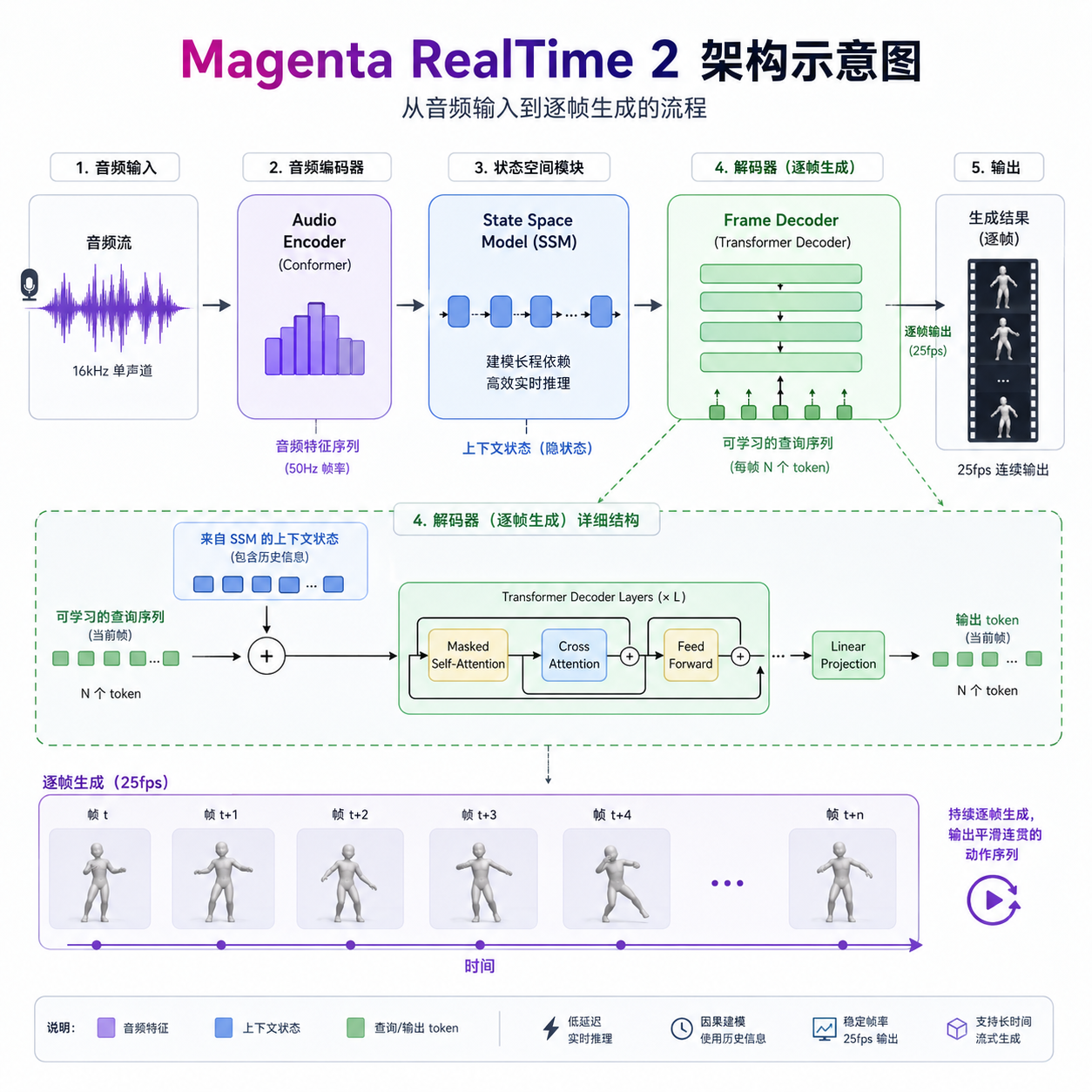
谷歌 Magenta 团队在 6 月 4 日发布了 Magenta RealTime 2(MRT2),这是一个可以在本地设备上实时运行的音乐生成模型。最大的突破是延迟:从上一代的 3 秒控制延迟压缩到 200 毫秒,降低到原来的 1/15。这个数字意味着什么?对于音乐人来说,200 毫秒已经接近真实乐器的反馈速度,你弹下一个音符,AI 几乎能同步响应。
这不是个纸面参数的优化。实时音乐生成的核心问题一直是「能不能跟上人的演奏节奏」。上一代 Magenta RealTime 需要 TPU 或高性能 GPU,还要以 2 秒为单位生成音频块,这种延迟让它更像是个「慢半拍的伴奏者」,而不是能即兴互动的乐手。MRT2 改成逐帧生成,每帧 40 毫秒,彻底改变了交互体验。
两个版本,针对 Apple Silicon 优化
MRT2 提供两个规模的模型:高质量版本 mrt2_base 有 24 亿参数,高速版本 mrt2_small 只有 2.3 亿参数。谷歌明确表示这两个版本都针对 Apple Silicon 芯片优化,其中 mrt2_small 可以在搭载 M1 及后续芯片的 Mac 上实时运行。
这个选择很有意思。音乐制作圈子里 Mac 占有率极高,Logic Pro、Ableton Live、FL Studio 这些主流 DAW 都把 macOS 当作第一优先级平台。谷歌这次直接把优化重心放在 Apple Silicon 上,而不是 CUDA GPU,说明他们清楚目标用户在哪里。
对比一下就能看出差异。上一代 Magenta RealTime 需要 TPU 或者至少是中高端的 NVIDIA GPU 才能跑起来,这对独立音乐人来说门槛太高。现在一台 M1 MacBook Air 就能跑 mrt2_small,这是质的变化。当然,如果你追求音质,24 亿参数的 mrt2_base 肯定更好,但 2.3 亿参数的版本已经足够用于实时演奏和快速原型制作。
控制方式的进化
MRT2 在控制层面比前代完整得多。它支持文本提示、音频风格参考、MIDI 音符输入,还有鼓组的开关控制。这几种输入方式可以组合使用,比如你可以先用文本描述「80 年代的合成器流行乐」,再用 MIDI 键盘弹奏旋律,模型会跟随你的音符实时调整生成内容。
更细节的是 Auto-Strum 模式。开启这个模式后,模型会自动决定拨弦或起音的时机,让生成的音乐听起来更自然。关闭后,你可以精确指定每个音符的起始时刻,适合需要严格控制节奏的编曲场景。对于鼓组,系统支持切换有鼓或无鼓的输出,这在多轨编曲里很实用——你可能只需要旋律和和声,鼓组部分留给其他音轨处理。
这种控制粒度的提升,背后是模型架构的改变。MRT2 本质上还是个 Codec Language Model(编解码器语言模型),基于 SpectroStream 音频编解码器处理 48kHz 立体声音频,以 25Hz 的帧率生成音频标记。每帧 40 毫秒,意味着模型每秒要做 25 次决策,这对推理速度的要求极高。谷歌能在 Apple Silicon 上跑通这个流程,说明他们在模型量化、算子优化上下了功夫。
Jam 应用和 DAW 插件
谷歌同步发布了两个配套工具。第一个是 Jam,一个免费的独立应用。你可以在文本框里输入想要的音乐风格,比如「jazz with piano and drums」,模型开始生成后,你可以通过下方的虚拟键盘调整音高。输入设备不限于鼠标点击,还支持 MacBook 的物理键盘和外接的 MIDI 键盘。
Jam 的定位是快速实验工具。如果你想测试某个音乐想法,或者需要一段背景音乐的灵感,打开 Jam 输入描述就能开始。它不是专业级的制作工具,但对于头脑风暴和概念验证来说够用。
第二个工具是 MRT2 插件,这个更重要。它让你可以在自己常用的 DAW 里调用 Magenta RealTime 2。对于已经有成熟工作流的音乐人来说,这个插件提供了接入路径。你不需要切换到新的应用,也不需要改变现有的项目结构,只要把 MRT2 当作一个乐器或效果器插入到音轨里就行。
这个设计思路很务实。音乐制作工具的生态系统非常成熟,专业用户不会因为一个 AI 模型就放弃自己用了多年的 Logic 或 Ableton。谷歌选择以插件的形式融入现有工作流,而不是试图用独立应用替代 DAW,说明他们理解这个市场的实际需求。
开源策略和竞争格局
MRT2 以开源形式发布,采用 Apache 2.0 许可证。模型权重托管在 Hugging Face 上,代码仓库在 GitHub。谷歌在模型卡片里明确声明:「对于你使用 MRT2 生成的输出,谷歌不主张任何权利,用户需要对输出内容及其后续使用承担全部责任。」
这个开源策略值得注意。MRT2 是 Lyria RealTime 的开源版本,而 Lyria RealTime 是支撑 Music FX DJ 和 Google AI Studio 实时音乐 API 的闭源模型。谷歌同时维护开源和闭源两条线,开源版本用于研究和社区实验,闭源版本服务商业产品。这种双轨策略在 AI 领域越来越常见——OpenAI 用 GPT 做商业模型,Meta 开源 Llama;Google DeepMind 用 Gemini 做产品,Magenta 团队发布开源模型。
对比其他音乐生成工具,MRT2 的优势在于实时性和本地运行。Suno、Udio 这些服务生成一首完整的歌曲可能需要几十秒,而且必须联网调用 API。Stable Audio、AudioCraft 这些开源模型虽然可以本地运行,但主要针对一次性生成,不是为实时交互设计的。MRT2 填补了「本地 + 实时 + 可控」这个细分需求。
当然,MRT2 也有明显的局限。它的音质和音乐性肯定比不上专门训练的高质量生成模型,毕竟 2.3 亿到 24 亿的参数规模放在音乐生成领域不算大。它更适合作为创作工具的一部分,而不是完全替代人类作曲。谷歌在文档里也明确提到,MRT2 继承了上一代的一些限制,比如对复杂和声结构的处理能力有限,生成的音乐可能缺乏长期的结构连贯性。
技术细节:从块状生成到逐帧生成
延迟优化的核心在于生成策略的改变。上一代 Magenta RealTime 以 2 秒音频块为单位生成,每个块不仅要基于用户输入的提示,还要考虑前 10 秒的音频上下文,这样才能保证音乐的连贯性。问题是,生成一个 2 秒的块本身就需要时间,加上前后块之间的衔接处理,整体延迟很难降下来。
MRT2 改成逐帧生成,每帧 40 毫秒,25Hz 的帧率。这意味着模型需要在 40 毫秒内完成一次推理,包括编码、Transformer 计算、解码。要在 Apple Silicon 上达到这个速度,量化和算子优化是必须的。从 GitHub 仓库的代码来看,谷歌使用了 Core ML 框架,这是苹果专门为 Apple Silicon 优化的机器学习框架,可以充分利用 Neural Engine 和 GPU。
SpectroStream 音频编解码器也是关键组件。它负责把 48kHz 的立体声音频压缩成离散的音频标记,然后 Transformer 模型在标记空间里做生成。这种 Codec-based 的架构是当前音频生成的主流方案,Meta 的 AudioCraft、微软的 VALL-E 都采用类似设计。区别在于编解码器的质量和压缩比,这直接影响生成音频的保真度和推理速度。
对音乐制作流程的影响
MRT2 这类实时音乐生成模型,对音乐制作流程的影响可能不是「替代作曲家」,而是「改变创作起点」。传统的音乐制作流程是:想法 → 编写旋律和和声 → 编曲 → 混音。AI 工具介入后,流程可能变成:描述想法 → AI 生成初始版本 → 人工调整和精修 → 混音。
这种变化对不同类型的创作者影响不同。对于专业音乐人,MRT2 可能更像是个快速原型工具,帮助他们快速验证某个和声进行或编曲思路是否可行。对于游戏开发者或视频制作者,MRT2 提供了一个低成本的配乐方案,虽然音质可能不如请专业作曲家,但对于预算有限的独立项目来说足够用。
更有趣的可能性在于现场表演。实时生成意味着每次演出都可以是独一无二的,音乐人可以根据现场观众的反应即兴调整 AI 的输出。这种人机协作的演奏形式,在电子音乐和实验音乐圈子里可能会有市场。当然,这需要演出者对 AI 的行为有足够的理解和控制能力,不然很容易翻车。
开源生态的下一步
Magenta 项目从 2016 年启动到现在,一直是音乐 AI 领域的重要开源力量。早期的 MusicVAE、Music Transformer、Magenta Studio 插件,都为社区提供了可用的工具和研究基线。MRT2 的发布标志着 Magenta 在沉寂一段时间后的回归,谷歌在公告里也提到「我们很高兴 Magenta RT 标志着 Magenta 开源发布的回归」。
从技术路线上看,实时生成是个明确的方向。音乐生成 AI 已经过了「能不能生成」的阶段,现在的问题是「怎么生成得更可控、更实用」。实时交互是可控性的一个重要维度,它把生成过程从黑盒变成了可调试的循环:你输入 → AI 输出 → 你调整 → AI 再输出。这种快速迭代对创作流程的影响,可能比单纯提高音质更大。
另一个值得关注的是本地运行的趋势。云端 API 的问题是延迟、成本和隐私。音乐制作往往涉及未发布的作品,很多创作者不愿意把原始音频上传到第三方服务器。本地模型解决了这个顾虑,同时也降低了使用成本——你不需要为每次 API 调用付费,硬件投入是一次性的。Apple Silicon 的性能提升让这种本地部署变得现实,未来可能会有更多 AI 工具选择这条路线。
局限和改进空间
尽管 MRT2 在延迟和本地运行上取得了突破,但它仍然是个研究预览版本,有很多明显的局限。首先是音质,2.3 亿参数的模型生成的音频,在细节和表现力上肯定比不上 Suno 或 Udio 这些专门优化过的高质量模型。其次是音乐性,AI 生成的音乐往往缺乏长期的结构和情感起伏,听起来可能会比较平淡。
控制精度也是个问题。虽然 MRT2 支持 MIDI 输入和文本提示,但这种控制还是比较粗糙的。你可以指定「爵士风格」「快节奏」,但很难精确控制某个和弦的转位,或者某个乐器的音色细节。这种粗粒度的控制对于专业制作来说可能不够用。
另一个限制是乐器类型。从 Jam 应用的界面和文档来看,MRT2 主要针对常见的流行音乐乐器(钢琴、吉他、贝斯、鼓组、合成器),对于管弦乐、民族乐器、实验音色的支持可能有限。这跟训练数据的覆盖范围有关,也跟模型的表达能力有关。
改进空间很明显:更大的模型、更好的音频编解码器、更精细的控制接口、更丰富的乐器支持。但这些改进都需要权衡。模型变大意味着推理变慢,可能无法在 M1 上实时运行;控制接口变复杂意味着学习成本变高,可能吓跑普通用户。如何在这些维度之间找到平衡,是 Magenta 团队和社区接下来要解决的问题。
结语
MRT2 的发布时机挺有意思。2026 年 6 月,距离 ChatGPT 引爆生成式 AI 已经过去三年多,AI 音乐生成工具已经从「新奇玩具」变成了「可用工具」。Suno 和 Udio 证明了 AI 可以生成完整的、听起来还不错的歌曲;Stable Audio 和 AudioCraft 证明了开源模型可以在本地运行;现在 MRT2 证明了实时交互在消费级硬件上是可行的。
这三个方向——高质量生成、本地运行、实时交互——可能会在未来几年里融合。理想状态是:一个可以在本地运行的、音质接近专业水准的、延迟低到可以实时演奏的音乐 AI 模型。我们现在还没到那一步,但 MRT2 至少证明了其中一块拼图是可以实现的。
对于开发者来说,MRT2 的开源发布提供了一个可以 fork、修改、实验的起点。你可以基于它做自己的乐器应用,可以改进控制接口,可以尝试把它接入到其他创作工具里。对于音乐人来说,现在可能还不是完全依赖 AI 的时候,但至少多了一个值得尝试的工具。
最后,如果你是 Apple Silicon Mac 用户,可以直接去 GitHub 下载代码跑一下 mrt2_small,体验一下 200 毫秒延迟的实时生成是什么感觉。这种技术只有亲自用过,才能真正理解它的潜力和局限在哪里。