腾讯混元 Stem 算法入选 ICML-26:25% 算力逼近全精度
腾讯混元今天宣布其 Stem 稀疏注意力算法被机器学习顶会 ICML-26 收录。这套算法用 25% 的算力就能逼近稠密注意力的精度,在 128K 上下文下把首字延迟降低 3.6 倍,论文和 HPC 算子库已经开源。
对开发者来说,这不是又一个「理论上很美」的优化方案。Stem 的核心价值在于把稀疏注意力的理论加速比真正转化成了端到端的实测性能,而不是停留在 FLOPs 计数的纸面游戏。
从因果信息流重新审视块级稀疏
Transformer 的注意力机制在长上下文推理时是个算力黑洞。业界常见的做法是用块级稀疏(block-sparse)来减少计算量,但传统方案要么精度掉得厉害,要么在真实硬件上跑不出理论加速比。
Stem 的思路是回到因果信息流的本质:在自回归生成中,后面的 token 依赖前面的 token,但这种依赖不是均匀的。它提出了两个关键创新:
Token 位置衰减(TPD):越靠前的 token 对当前生成的影响越弱,可以用更粗粒度的注意力处理。这不是简单的距离衰减,而是基于因果链路的衰减模式。
输出感知度量(OAM):不是静态地决定哪些 token 重要,而是根据输出的实际需求动态调整稀疏模式。这让 Stem 在不同任务和生成阶段都能保持接近稠密注意力的精度。
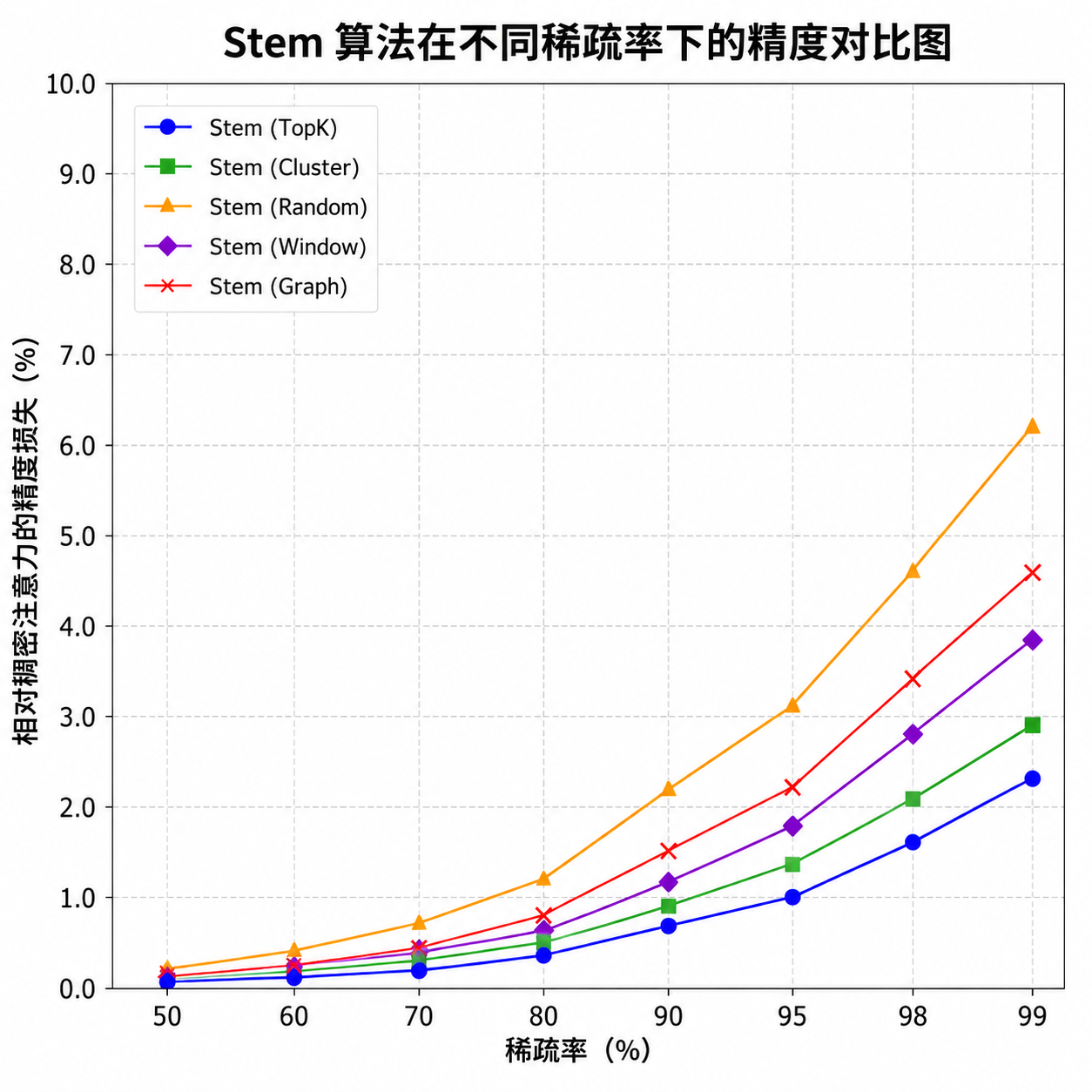
25% 算力预算下的近无损精度
论文给出的数据很直接:在 25% 的算力预算下,Stem 在多个基准任务上的表现都接近稠密注意力。这里说的「接近」不是 90% 的那种接近,而是差距在统计误差范围内的那种接近。
更关键的是,这个精度是在腾讯混元 Hy3 preview(W8A8-FP8)量化模型上测出来的,不是在 FP16/BF16 的理想条件下。量化本身就会带来精度损失,Stem 能在量化模型上保持性能说明它的设计足够鲁棒。
从开发者角度看,这意味着你可以在保持输出质量的前提下,把推理成本砍到原来的四分之一。对于需要处理长上下文的应用场景——代码补全、文档分析、多轮对话——这是实打实的成本优化。
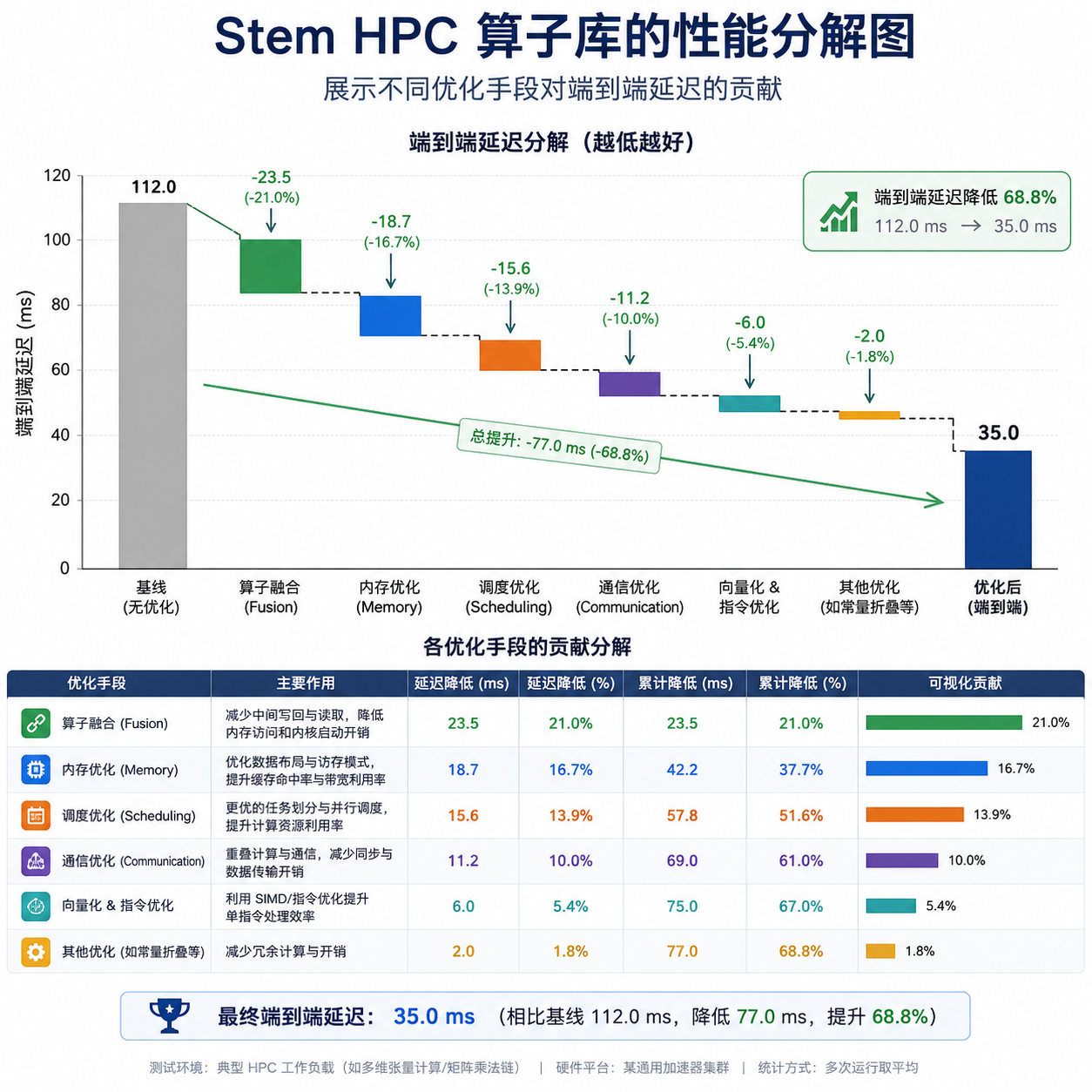
HPC 算子库让加速比落地
有过 GPU 优化经验的人都知道,理论 FLOPs 降低和实际延迟降低是两码事。内存带宽、kernel launch overhead、不规则访问模式,任何一个都能让你的理论加速比变成空谈。
Stem 配套开源的 HPC 算子库解决的就是这个问题。它提供了 Stem 和 BSA(Block-Sparse Attention)的 CUDA 实现,针对 H100/H800 这类硬件做了专门优化。
在 128K 上下文下,首字延迟降低 3.6 倍这个数据是端到端测出来的,包括 kernel launch、数据传输、所有真实推理场景会遇到的开销。这比那些只报告单个算子性能的方案靠谱得多。
对标其他稀疏注意力方案
稀疏注意力不是新概念。FlashAttention、PagedAttention、各种滑动窗口方案都在解决类似问题。Stem 的差异化在哪?
FlashAttention 主要优化的是内存访问模式,本质上还是稠密注意力。它在短上下文下很高效,但长上下文的算力问题解决不了。
滑动窗口方案(比如 Longformer、BigBird)用固定模式做稀疏,简单但精度损失明显。在需要全局信息的任务上(比如文档问答)表现不行。
学习式稀疏方案(比如各种 learned sparsity)理论上更灵活,但训练成本高,而且通常需要从头训练或大规模 fine-tune。
Stem 的优势是它能直接应用到已有模型上,不需要重新训练,同时在精度和效率之间找到了更好的平衡点。TPD 和 OAM 的设计让它既能捕获全局信息,又能保持计算效率。
工程实现的细节
开源的代码里有几个值得关注的点:
分块策略:Stem 不是简单地把序列切成固定大小的块,而是根据 TPD 和 OAM 动态调整块大小和稀疏模式。越靠前的 token 块越大,越靠后的块越小。
混合精度处理:在 W8A8-FP8 量化场景下,Stem 对不同稀疏度的块用不同的精度策略。重要的块保持更高精度,次要的块可以用更激进的量化。
Kernel fusion:HPC 算子库把多个操作融合到一个 kernel 里,减少内存往返。这在稀疏场景下尤其重要,因为不规则访问本来就容易卡在带宽上。
预取和流水线:长上下文推理最怕 memory stall。算子库用了激进的预取策略和多流水线,让计算和数据传输尽量重叠。
ICML-26 收录说明什么
ICML 是机器学习的三大顶会之一,审稿严格,拒稿率常年在 70% 以上。Stem 能被收录说明它的理论贡献得到了学术界认可。
但更重要的是,这不是一篇纯理论论文。完整的开源实现、真实硬件上的测试数据、在量化模型上的验证,这些都是工程价值的体现。学术界和工业界在稀疏注意力这个方向上已经探索了好几年,Stem 的贡献是把理论和工程的 gap 缩小了一大步。
从国内大模型厂商的角度看,这也是个信号:在模型规模和训练数据之外,系统优化和算法创新同样重要。OpenAI、Anthropic 在推理优化上投入巨大,国内厂商如果只盯着参数量和 benchmark 分数,长期竞争力会有问题。
对开发者的实际意义
如果你在用腾讯混元的 API,Stem 的优化可能已经在后台生效了,表现就是长上下文场景下响应更快、成本更低。
如果你在做模型推理服务,HPC 算子库是个值得关注的工具。它不绑定特定模型,理论上可以集成到任何 Transformer 架构的推理引擎里。不过要注意,目前的实现主要针对英伟达 H 系列卡优化,在其他硬件上的表现可能会打折扣。
如果你在研究稀疏注意力,Stem 的 TPD 和 OAM 设计提供了新的思路。代码开源意味着你可以在它的基础上做实验,而不用从零开始实现一套稀疏注意力方案。
开源代码和资源
腾讯把 Stem 的完整实现都开源了:
- 论文:arxiv.org/abs/2603.06274,详细描述了 TPD 和 OAM 的设计原理、理论分析和实验结果
- 算法实现:github.com/Tencent/AngelSlimHPC,包含 Stem 的 Python 接口和参考实现
- HPC 算子库:github.com/Tencent/hpc-ops,CUDA kernel 和性能测试工具
代码质量不错,有完整的文档和使用示例。如果你想在自己的项目里集成 Stem,从 HPC 算子库开始是最直接的路径。
长上下文推理的未来
稀疏注意力只是长上下文推理优化的一个方向。还有其他几条并行的技术路线:
架构创新:像 Mamba 这样的状态空间模型,从根本上避开了注意力机制的二次复杂度
量化和压缩:更激进的量化方案(比如 4-bit、甚至 2-bit),或者动态精度分配
系统优化:更好的显存管理(PagedAttention)、更高效的调度策略、专用硬件加速器
Stem 在稀疏注意力这条路上走得比较深,但它不是唯一答案。未来可能是多种技术的组合:用 Mamba 处理超长上下文,用稀疏注意力处理中长上下文,用稠密注意力处理短上下文,再加上激进的量化和专用硬件。
从这个角度看,Stem 的价值不只是一个具体的算法,而是证明了在现有 Transformer 架构下,通过算法和系统协同优化,还能榨出不少性能空间。这对整个行业都是好消息,因为重写所有模型架构的成本太高,能在现有基础上优化是更现实的路径。
参考资源
- 腾讯混元提出 Stem 稀疏注意力算法,首字延迟降低 3.6 倍 - IT之家 - 官方发布信息和核心数据
- Stem 算法开源仓库 - GitHub - Python 实现和使用文档
- Stem HPC 算子库 - GitHub - CUDA kernel 和性能测试工具