华为云押注 Agentic AI,联合 20 家模型厂商抢滩智能体时代
华为云今天在上海正式摊牌了——Agentic AI 是接下来的战略主轴。
6 月 5 日的 INSPIRE 创想者大会上,华为云提出 Agentic Infra 新范式,发布了四款基础设施新品,并联合智谱、DeepSeek、Minimax、Kimi、阶跃星辰、百度、美团 LongCat、讯飞星火、爱诗科技、生数科技等 20 余家头部模型厂商,启动「百模千态,云聚共赢」生态合作计划。
这个动作意味着华为云的定位从「服务模型训练」进一步升级为「服务 Agent 应用落地」。过去两年云厂商拼的是谁能更快上线新模型、谁的推理成本更低,现在战场变了——智能体才是真正能落地赚钱的东西,而支撑智能体大规模运行的基础设施,才是云厂商的护城河。

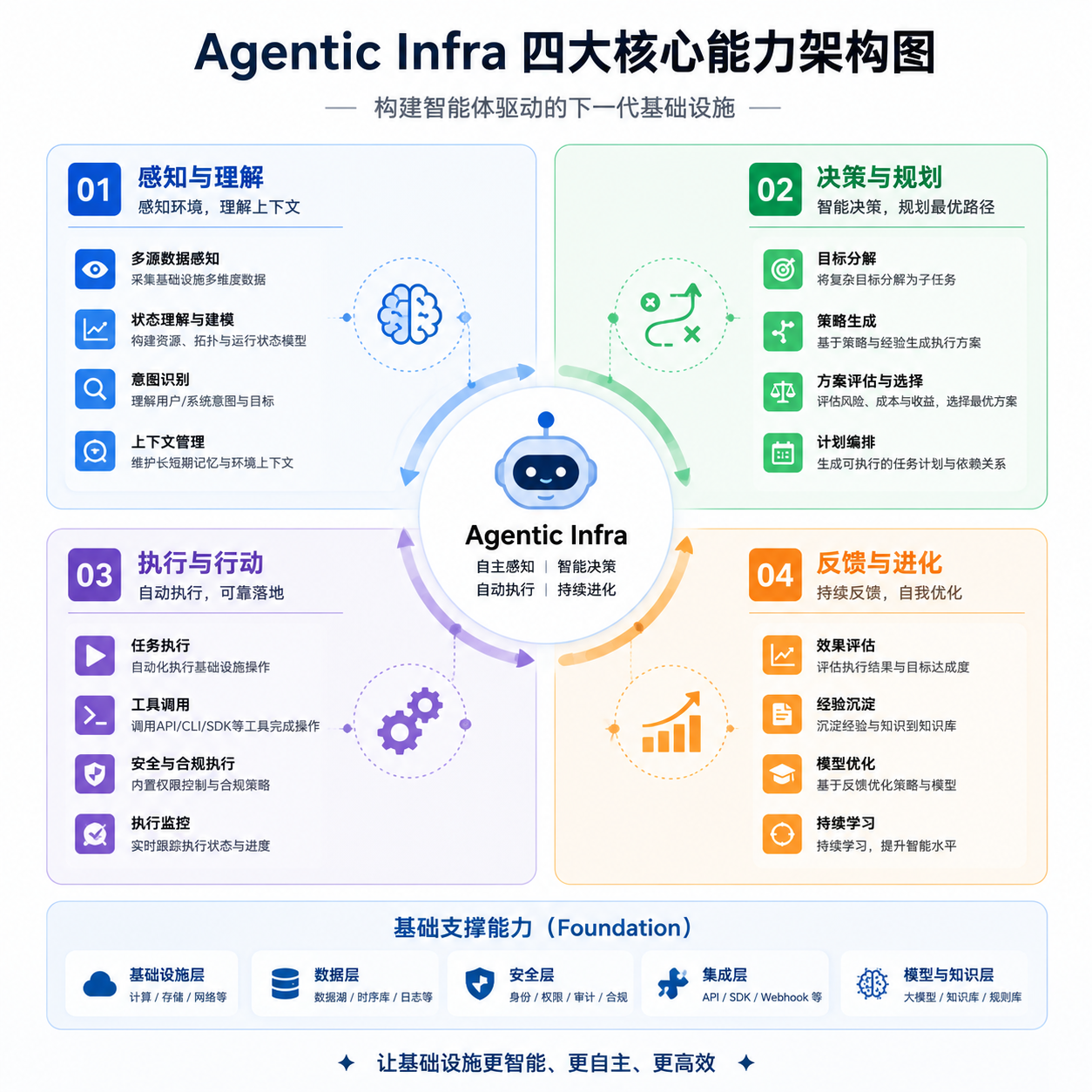
Agentic Infra 到底是什么?
华为云给出的定义是「高效 Token 工厂 + 持续学习 + 通智一体化调度 + 安全自治」。拆开来看,这四个能力分别对应智能体规模化运行的四个核心痛点。
Token 工厂:智能体的推理延迟直接影响用户体验。你让 Agent 帮你订机票,它思考 10 秒才给反馈,这体验就崩了。华为云发布的 AICS 灵衢智算集群支持 10 万卡级规模,总算力 200 EFLOPS,把 Tokens 生成延迟压到 10 毫秒以内,千卡每秒吞吐 500 万 Tokens,在线服务可用性 99.95%。这个数字意味着什么?对比一下,业界主流的推理集群延迟通常在 50-100 毫秒,华为这套系统直接干到了个位数。
持续学习:智能体需要记住上下文。你跟它聊了一小时,它突然忘了你刚才说的需求,这就是 KV Cache 容量不够的问题。华为的 AMS Agentic 记忆存储解决方案通过 NPU 直通 CMS(上下文记忆存储)硬件,打造 PB 级记忆空间,支持 KV Cache 分层池化,能扛住「天级」长程任务。这个设计的关键在于把热数据放在高速存储,冷数据沉到廉价存储,既降低成本又保证性能。
通智一体化调度:训练和推理任务往往跑在不同的集群上,资源利用率低。华为推出的 CCE VolcanoNext 通智一体化调度引擎做的事情是「训推共池 + 碎片整合」——训练任务跑完的卡可以立刻切给推理用,推理的碎片算力也能拼起来跑小任务,资源利用率提升 30% 以上。这对云厂商来说是真金白银的成本优化,对用户来说意味着更便宜的算力。
安全自治:智能体会调用外部 API、执行代码、操作数据库,安全风险比单纯的模型推理高得多。AgentSphere 提供的是一个「极速弹性 + 意图主动防护」的沙箱环境,100 毫秒启动,每分钟能批创十万级智能体实例。这个能力对应的场景是什么?想象一个客服系统,每个用户对话都启动一个独立的 Agent 实例,用完即销毁,既保证隔离又不影响响应速度。
从拼模型到拼生态
华为云这次拉了 20 多家模型厂商一起玩,名单很能说明问题:智谱、DeepSeek、Minimax、Kimi、阶跃星辰、百度、美团 LongCat、讯飞星火、爱诗科技、生数科技……基本把国内主流的闭源和开源模型供应商都覆盖了。
这个生态计划的核心逻辑是:云厂商不再只是「卖算力」,而是要帮模型厂商把模型「卖出去」。华为云提供的是一套完整的商业化工具链——从模型训练、推理优化、智能体开发,到应用分发、计费结算。模型厂商只需要专注做好模型本身,其他环节都有现成的基础设施支撑。
这个打法跟 AWS 做 SageMaker、Google 做 Vertex AI 是一个思路,但华为的切入点更激进——直接押注 Agentic AI。原因很简单:模型 API 调用的利润空间已经被压得很薄了,DeepSeek V3 把推理成本打到 0.14 元 / 百万 tokens,这个价格下云厂商能赚的钱有限。但智能体应用不一样,客户愿意为「能解决问题的 Agent」付更高的溢价。
华为云在会上还宣布上线「行业 AI 梦工厂」,首批落地智慧医疗、具身智能、智能制造、科学计算四个专区。这个动作的意图很明确——把通用能力变成行业解决方案,缩短 AI 从实验室到产线的路径。比如智慧医疗专区,华为云会接入医院的 HIS 系统、影像设备,提供开箱即用的诊断 Agent、随访 Agent;具身智能专区对接机器人厂商,提供仿真环境和任务调度能力。
这套基础设施有什么不一样?
华为云强调的「软硬芯协同」不是空话。灵衢智算集群用的是华为自研的昇腾 AI 芯片 + 灵衢网络,这套硬件栈的优势在于网络和计算的深度集成。传统 GPU 集群的瓶颈往往在网络——AllReduce 通信占了训练时间的 30%-40%,华为通过定制网络协议和拓扑优化,把通信开销压下来。
AMS 记忆存储方案的亮点是 NPU 直通 CMS。传统架构里,KV Cache 存在显存或者主机内存,访问路径要经过 PCIe 总线,延迟高、带宽受限。华为做的是在 NPU 芯片上直接集成存储控制器,绕过 PCIe,把访问延迟降到纳秒级。这个设计对长上下文推理的收益巨大——当上下文长度从 8K 涨到 128K,KV Cache 访问的次数会呈指数增长,延迟优化带来的性能提升是线性的。
VolcanoNext 调度引擎解决的是「训推混合部署」的难题。训练任务是批处理,吃满所有卡跑几小时甚至几天;推理任务是在线服务,要求低延迟、高并发。传统的 Kubernetes 调度器处理不了这种异构负载,华为做的是在调度器里加了一层「意图识别」——根据任务的资源画像(计算密集 / 内存密集 / 通信密集)和 SLA 要求,动态分配合适的资源池。
AgentSphere 沙箱的「羽量级」设计值得细说。传统的容器启动要几秒,虚拟机更慢。华为用的是 WebAssembly 沙箱 + eBPF 安全策略,启动时间压到 100 毫秒。这个技术选型的好处是隔离性强(每个 Agent 独立运行)、开销低(不需要完整的操作系统),而且可以在沙箱里监控 Agent 的行为——比如检测到异常的 API 调用频率、可疑的数据访问模式,立刻熔断。

竞争对手在做什么?
Agentic AI 这个赛道现在很挤。
OpenAI 的 GPTs 和 Assistants API 是最早的智能体平台,但它是封闭生态,只能用 OpenAI 的模型。Google 的 Vertex AI Agent Builder 支持 Gemini 和开源模型,但部署灵活性不如云原生方案。微软 Azure 的 Semantic Kernel 和 AutoGen 更偏开发框架,需要开发者自己搭基础设施。
国内云厂商里,阿里云有 ModelScope Agent 和通义千问的智能体能力,腾讯云推了混元助手和 AI 开发平台,但它们的重心还是在「模型即服务」,基础设施层面的投入没有华为这么激进。华为这次直接提出 Agentic Infra 新范式,把智能体运行需要的算力、存储、调度、安全全链路打通,是把基础设施本身当成产品来做。
这个策略的风险在于:智能体的形态还没定型。现在大家做的 Agent 主要是「对话式助手 + 工具调用」,但未来可能会演化出完全不同的范式——比如多智能体协作、具身智能、自主决策系统。华为押注的这套基础设施能不能适配未来的形态,是个问号。
但换个角度看,云厂商做基础设施本来就是个「先手投资」——你不可能等所有应用形态都清晰了再去建数据中心。华为的打法是先把底层能力做扎实(算力、存储、调度、安全),上层应用怎么跑是开发者的事。这跟 AWS 早期做 EC2、S3 的逻辑一样——提供原子化的能力,让生态去组合。
开发者能拿这些东西干什么?
华为云同步发布了企业级智能体平台 AgentArts,覆盖智能体开发全流程:提示词工程、工具编排、记忆管理、多智能体协作、测试调试、部署监控。
具体场景举几个例子:
客服智能体:接入企业的工单系统、知识库,处理售前咨询、售后问题。AgentArts 提供的工具包括意图识别、多轮对话管理、知识检索(RAG)、工单创建 API 调用。关键能力是「上下文记忆」——用户打了三通电话,Agent 能记住之前的沟通内容,不用重复问。
RPA 智能体:自动化办公流程,比如从邮件里提取发票信息、填表、报销审批。AgentArts 的优势是可以编排复杂的任务流——先调 OCR 识别发票,再调财务系统 API 查重,最后提交审批。传统 RPA 工具需要写死流程,Agent 可以根据实际情况动态调整。
代码助手:帮开发者写代码、改 bug、写文档。这个场景对推理延迟要求极高——开发者敲完一行代码,等 5 秒才出补全建议,体验就废了。华为的 10 毫秒延迟在这个场景下是刚需。
具身智能:控制机器人完成仓储拣选、巡检、配送。AgentArts 提供的是「仿真 + 真机」联调环境——先在虚拟环境里训练 Agent,验证任务逻辑,再部署到真实机器人。关键能力是「持续学习」——机器人遇到新场景(比如货架摆放变了),Agent 可以在线调整策略。
华为还启动了「码道高校教学实践计划」,面向高校开发者提供免费算力和工具链。这个动作的用意很明确——抢开发者心智。云厂商的竞争最终是生态的竞争,谁能让开发者更早上手、更快出成果,谁就能建立先发优势。
商业化路径清晰了吗?
Agentic AI 的商业化现在还是个「摸着石头过河」的状态。
模型厂商靠 API 调用收费,但智能体应用的计费模式还没定论。按对话轮次收费?按任务完成度收费?按时间收费?不同场景可能需要不同的计费逻辑。华为云提供的「系统化商业生态」,一个重要组成部分就是帮模型厂商和应用开发者理顺这套商业模式。
另一个问题是:企业客户愿意为 Agent 付多少钱?如果 Agent 只是「更智能的聊天机器人」,客户不会付太高的溢价。但如果 Agent 能真正替代人工(比如客服、审计、编程),那付费意愿就会高得多。华为云推的「行业 AI 梦工厂」本质上是在验证这个假设——把通用 Agent 能力包装成行业解决方案,让客户看到 ROI。
从技术投入的角度看,华为这次发布的四款新品都是「重资产」——10 万卡智算集群、PB 级存储、定制芯片、自研调度器,这些东西的研发和运营成本不是小数目。能不能收回成本,取决于 Agentic AI 市场的增速。如果智能体应用在未来两年真的爆发,华为这套基础设施就是「卖铲子」的生意,躺着赚钱;如果市场起不来,这些投入就打水漂了。
但有一点可以确定:云厂商不做这个投入,就只能在「卖算力」的红海里卷价格。华为选择往上走一层,做智能体时代的基础设施,是个有风险但值得赌的方向。
写在最后
华为云这次发布会释放的信号很明确:Agentic AI 是接下来的主战场,云厂商要从「服务模型」转向「服务应用」。
这个转变背后的逻辑是:模型本身在快速商品化,开源模型的能力已经逼近闭源模型,API 调用的价格战没有尽头。但智能体应用的门槛还很高——开发者需要处理工具调用、记忆管理、安全沙箱、任务编排,这些能力不是一个模型 API 能解决的。谁能把这套能力做成开箱即用的基础设施,谁就能拿到下一个十年的船票。
华为的优势在于硬件栈的掌控力——自研芯片、网络、存储,可以做深度优化。劣势在于生态起步晚,开发者心智还在 AWS、Azure 上。这次联合 20 家模型厂商发布生态计划,是在补生态的短板。
至于这套基础设施能不能跑通,得看未来一年的落地情况。技术 demo 好做,规模化商用是另一回事。但至少方向是对的——Agentic AI 确实是下一个浪潮,谁先把基础设施做好,谁就能在浪潮里站稳。
参考来源
- 华为云联合 20 余家模型厂商发布生态合作计划 - IT之家官方报道,包含发布会核心信息和四大新品技术细节