OpenAI 上线 Dreaming V3:ChatGPT 记忆系统彻底重构
OpenAI 昨天(6 月 4 日)发布了 ChatGPT 记忆系统的最大一次架构升级。新版本 Dreaming V3 放弃了过去两年一直依赖的「保存记忆」列表,改用异步后台合成机制,把用户的对话历史、上传文件、连接的第三方应用(Gmail、日历等)当作原始数据源,持续生成一份结构化的「记忆状态」。
这次升级不是打补丁,而是把整个记忆层的设计逻辑推倒重来。从 2024 年 4 月那版需要用户主动说「记住这个」的 Saved Memories,到现在能自己判断什么该记、什么过时了该删的 Dreaming V3,ChatGPT 的记忆能力终于从「备忘录工具」进化成了「持续更新的用户画像引擎」。
从手动保存到异步合成:架构层的根本性转变
Dreaming V3 最核心的改变是把记忆从「用户主动保存的事实列表」变成了「系统持续合成的派生状态」。过去的 Saved Memories 机制下,你得明确告诉 ChatGPT「记住我喜欢喝黑咖啡」,它才会把这条写进记忆列表。但这种设计有两个致命缺陷:一是用户得记得去维护这个列表,二是保存下来的信息永远不会自己更新——你三个月前说喜欢黑咖啡,现在改喝拿铁了,ChatGPT 还会按老记忆推荐。
Dreaming V3 的做法完全不同。它在后台跑一个异步进程,不断扫描你的所有对话、文件、邮件,从中提取关键信息,合成出一份「当前你是谁」的快照。这个快照不是静态的——每隔一段时间,系统会重新跑一遍合成流程,把新对话里的信息加进来,把过时的细节标记为历史状态,把相互矛盾的事实做调和。
举个例子。你 5 月底跟 ChatGPT 说「下周去新加坡出差」,Dreaming V3 会记下这是个临时状态,不会把你标记为「常住新加坡」。到了 6 月中旬你回国了,系统会自动把「在新加坡」这个状态归档,推荐餐厅时不再给你推新加坡的店。这种「区分临时状态和长期事实」的能力,是 Saved Memories 完全做不到的。
技术实现上,Dreaming V3 把记忆拆成了三层:原始数据源(对话、文件、应用数据)、合成引擎(异步后台进程)、查询层(对话时快速检索相关片段)。记忆本身不是源数据,而是对源数据的持续再解读。这个设计解释了为什么 OpenAI 强调「删除记忆需要同时删除摘要、对话记录、归档和断开应用连接」——因为只要源数据还在,下次合成时记忆就会再生成出来。
三个标准定义「好记忆」:延续、遵循、更新
OpenAI 在官方公告里给出了他们评估记忆质量的三个维度:
1. 延续有用的上下文
这是最基础的能力:用户在过去对话里提到的细节,应该在后续对话中被自然调用。比如你之前说过「我是前端开发者,主要用 React」,下次问技术问题时,ChatGPT 应该默认给 React 方案,而不是从 Vue 或 Angular 讲起。
Dreaming V3 的改进在于,它能从碎片化的对话里提取结构化信息。你不需要专门说一句「我是 React 开发者」,只要在几次对话里自然提到过 React 项目、讨论过 hooks 写法、问过状态管理方案,系统就能归纳出这个结论。
2. 遵循偏好和限制
这一层涉及用户的主观倾向和硬性约束。比如饮食限制(素食、过敏源)、沟通风格(要不要 emoji、回复长度)、工作流程(代码要不要注释、需不需要单元测试)。
Dreaming V3 在这里做的优化是「条件化记忆」。你可以在记忆摘要页设置「讨论旅行时提醒我喜欢野生动物摄影」「写代码时默认加详细注释」这种带触发条件的偏好。系统会在合适的场景下激活对应的记忆片段,而不是无脑把所有记忆都塞进上下文。
3. 随时间自动更新
这是 Dreaming V3 最大的突破。过去的 Saved Memories 是「写一次,永久有效」,新系统则会持续判断每条记忆的时效性。
官方给的例子很直观:你早上 5 点在新加坡问「附近有什么早餐店」,如果用 Saved Memories,它会一直记得你在新加坡,哪怕你已经回国一周了。Dreaming V3 会追踪时间线,知道「在新加坡」是个结束了的临时状态,自动切换回你的常住地。
这个能力背后是对「事实的生命周期」的建模。系统要区分「我住在北京」(长期事实)和「我这周在出差」(临时状态),还要处理「我以前住北京,现在搬到上海了」(事实变更)这种情况。Dreaming V3 通过持续重新合成记忆快照来解决这个问题——每次合成时,都会重新评估每条信息的当前有效性。
性能优化:算力降至五分之一,免费用户即将开放
Dreaming V3 另一个关键改进是成本控制。OpenAI 提到,相比之前的架构,新系统为免费用户提供服务时的算力开销下降了约 5 倍。
这个优化很关键。记忆系统的成本主要在两个环节:一是后台合成时要处理大量历史对话,二是对话时要做相关性检索。Dreaming V3 的设计天然适合做增量更新——不需要每次都从头扫一遍所有对话,只需要把新增的部分合并到现有快照里。查询侧则通过「先判断是否需要个性化,再做精确检索」的两阶段设计来控制开销。
具体来说,当你发起一个新对话时,系统会先跑一个轻量级的「个性化判断」:这个问题是通用知识查询(比如「Python 怎么排序列表」),还是需要用到用户上下文(比如「帮我优化上次那个 API 设计」)。如果是前者,直接走标准回答流程,连记忆检索都不触发。只有后者才会去查相关的记忆片段和历史对话。
这个设计解释了为什么 OpenAI 敢把 Dreaming V3 作为独立的记忆底层——在他们的评估里,这套架构已经能在保证质量的前提下,支撑数亿用户的长期使用。目前功能已经向美国的 Plus 和 Pro 用户开放,未来几周会扩展到免费版、Go 方案和更多国家。
对比竞品:Claude 和 Gemini 的记忆策略
ChatGPT 不是唯一在做记忆系统的对话 AI。Anthropic 的 Claude 和 Google 的 Gemini 都有类似能力,但实现思路各不相同。
Claude 的记忆更偏向「项目级上下文」。它的 Projects 功能允许用户为每个项目创建独立的知识库,上传文档、设定指令,对话时自动调用相关内容。这种设计适合需要在特定领域深度工作的场景(比如一个软件项目的代码库 + 设计文档 + 过往讨论),但跨项目的长期用户画像能力相对较弱。
Gemini 的策略介于两者之间。它既有跨对话的全局记忆,也支持通过 Google Workspace 集成来调用用户的邮件、日历、文档。但 Gemini 的记忆更新机制目前还是偏被动——主要靠用户主动补充信息,自动提取和时效性更新的能力不如 Dreaming V3。
Dreaming V3 的优势在于「完全异步 + 持续更新」。它不依赖用户手动维护,也不需要在每次对话时做重量级的实时合成。记忆是在后台慢慢「长」出来的,对话时只需要快速查询。这个架构在扩展性和成本上都更有优势,也更符合「AI 助理应该主动理解用户,而不是等用户来教」的产品理念。
隐私边界:记忆摘要页和临时对话
Dreaming V3 带来的便利性提升,也意味着 ChatGPT 会自动记录更多信息。OpenAI 在设计里加了几个隐私控制点:
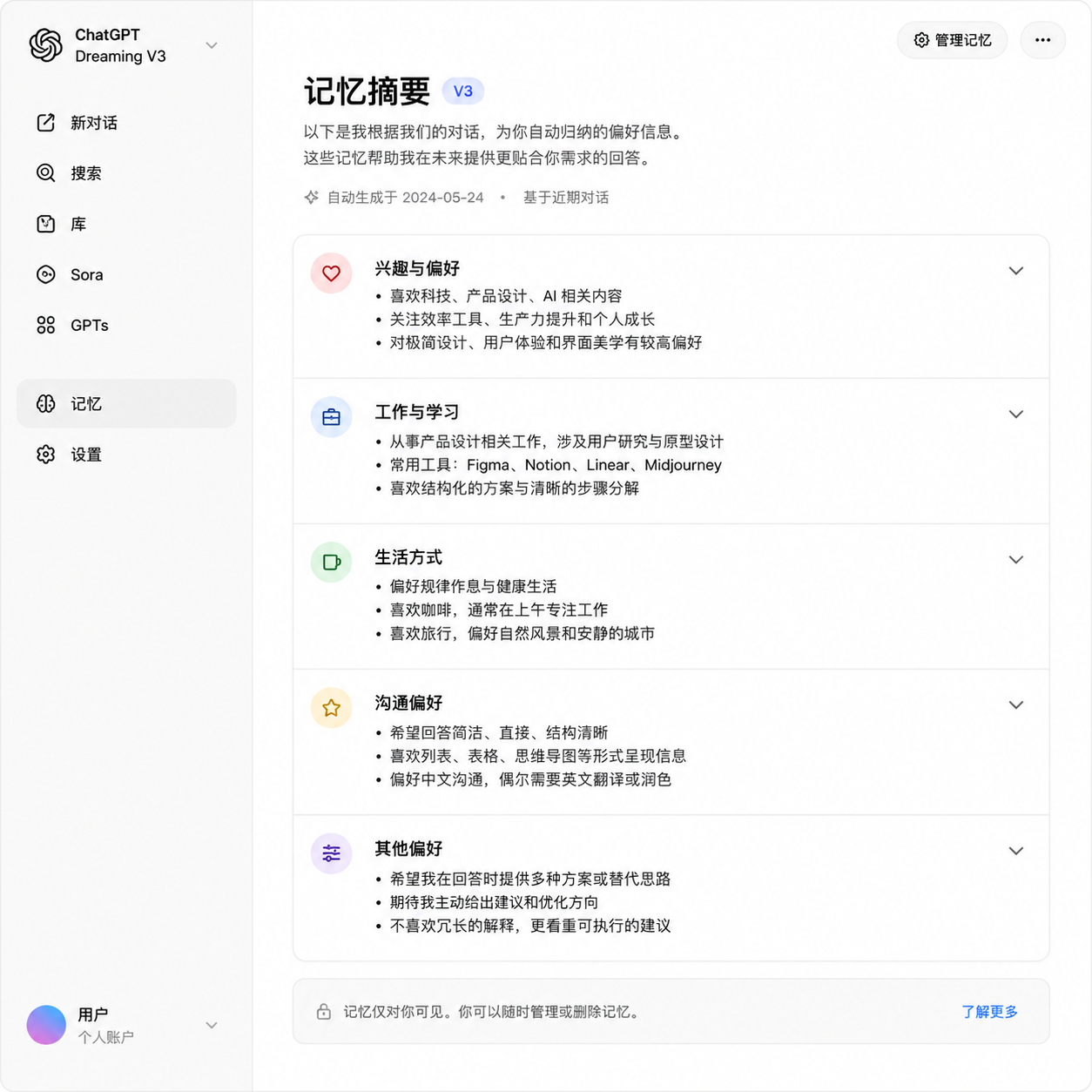
记忆摘要页:这是一个可视化界面,展示系统从你的对话里提取出的所有结构化信息。你可以看到 ChatGPT 认为你是谁、喜欢什么、在做什么项目。每条记忆都可以编辑或删除,也可以补充新信息(比如手动添加「我对海鲜过敏」这种系统可能没机会从对话里学到的事实)。
临时对话模式:如果你想问一些不希望被记录的问题(比如帮别人改简历、讨论敏感话题),可以开启临时对话。这个模式下的内容不会进入记忆合成流程,也不会影响你的用户画像。
关闭记忆功能:可以在设置里彻底关闭记忆系统。但要注意,关闭记忆不会自动清空已经保存的内容——如果想彻底删除某条信息,需要手动去记忆摘要页删除,还可能需要同时删除相关的对话记录和归档,甚至断开来源应用的连接(因为只要源数据在,下次合成时记忆就会重新生成)。
这些设计在便利性和隐私之间找了个平衡点,但也把「主动管理 AI 记住了什么」的责任推给了用户。如果你从来不去看记忆摘要页,就不会知道 ChatGPT 实际上对你形成了什么认知。这个问题在 Dreaming V3 时代会更突出——因为记忆是自动生成的,你很难预判系统会从哪些对话里提取出什么信息。
实际体验:记忆系统的「涌现行为」
Dreaming V3 上线后,Reddit 的 r/MachineLearning 板块已经有开发者在分析它的行为模式。有几个有意思的发现:
1. 系统会主动做「事实调和」
如果你在不同时间说了冲突的信息(比如「我是后端工程师」和「我主要写前端」),Dreaming V3 不会简单地保留最新的那条,而是会尝试理解上下文。可能的结果是「用户是全栈工程师,最近在做前端项目」,也可能是「用户转岗了,以前做后端现在做前端」。这个调和过程是在合成阶段自动完成的,用户不需要介入。
2. 对「隐式信息」的提取能力显著提升
你不需要明确说「我喜欢简洁的代码风格」,只要你在几次 code review 对话里都提到过「这个函数太长了」「能不能拆成小一点的模块」,系统就能归纳出这个偏好。这种从行为模式里提取隐式偏好的能力,是 Saved Memories 完全做不到的。
3. 时效性判断还不完美
虽然 OpenAI 强调了「随时间更新」的能力,但实际测试发现,系统对「什么时候该把信息标记为过时」的判断还比较保守。有用户反映,结束一个项目两周后,ChatGPT 还会时不时提到那个项目的细节。这可能是 OpenAI 有意为之——宁可多保留一些可能有用的上下文,也不要过早删掉还可能被引用的信息。
Dreaming V3 对开发者意味着什么
如果你在用 ChatGPT 写代码、做技术决策,Dreaming V3 会带来几个直接影响:
更连贯的多轮协作:之前你可能需要在每次新对话开始时重新说明「我这个项目用 TypeScript + React + tRPC」,现在这些信息会自动延续。讨论架构、写代码、改 bug,系统会记得你的技术栈和代码风格。
更精准的上下文理解:当你说「优化一下之前那个 API」,系统能更准确地定位到你指的是哪个 API、上次讨论到什么程度、还有哪些遗留问题。这种跨对话的引用能力,在 Saved Memories 时代需要你手动提供足够的上下文,现在会自动补全。
需要主动管理技术偏好:如果你习惯某种特定的代码组织方式(比如「API 层和业务逻辑要严格分离」「测试覆盖率必须 >80%」),可以在记忆摘要页显式设置,避免每次都要重新说明。
但也要注意,Dreaming V3 的「主动学习」特性意味着,如果你在对话里随口说了些不太准确的话(比如「我一般不写单元测试」),系统可能会当真并在后续对话中默认这个假设。定期检查记忆摘要页,确保系统对你的认知是准确的,会是个有必要养成的习惯。
从工具到助理:记忆系统的产品逻辑转变
Dreaming V3 的发布,标志着 OpenAI 在产品定位上的一个重要转向:ChatGPT 不再只是「你问我答」的对话工具,而是在往「长期陪伴、持续学习」的个人助理方向演进。
这个转变的核心在于「状态的持久化」。过去每次对话都是独立的,ChatGPT 不记得你是谁、你在做什么,每次都从零开始。Saved Memories 迈出了第一步,但那只是个备忘录,不会自己更新。Dreaming V3 则让 ChatGPT 真正拥有了「对用户的持续认知」——它知道你现在在做什么项目、你的工作方式是什么样的、你最近关注哪些技术,这些认知会随着你的真实状况同步更新。
这种产品形态对 AI 能力提出了更高要求。它不仅要能回答单次问题,还要能建模「一个人的长期状态」,要区分事实和偏好、临时和长期、明确和隐含。从技术角度看,这是从 stateless 到 stateful 的跨越,复杂度不在一个量级。
Dreaming V3 还不是这个方向的终点。目前它主要覆盖文本对话、文件、邮件这些结构化程度较高的数据源,未来可能会接入更多类型的信号(日历事件、代码仓库、浏览历史)。记忆的颗粒度也还有提升空间——现在是「用户级」的全局画像,将来可能会支持「项目级」「角色级」的细分记忆(比如工作场景和个人场景用不同的记忆集)。
对开发者来说,这个趋势意味着 AI 工具的使用模式会从「一次性任务」转向「长期协作」。你不再是每次都去「租用」一个 AI 来解决问题,而是在「培养」一个了解你工作方式的助手。这个转变会让 AI 的价值从「单次效率提升」变成「持续生产力增益」,但也要求用户投入更多精力去管理 AI 对自己的认知。
OpenAI Hub 现已支持通过标准接口调用最新的 ChatGPT 能力。虽然 Dreaming V3 的记忆合成机制目前是 ChatGPT 产品内的特性,暂未开放到 API 层,但随着这套架构的成熟,不排除未来会以某种形式向开发者开放——让第三方应用也能构建类似的「长期记忆」能力。
参考来源
- Reddit r/MachineLearning - How OpenAI Dreaming V3 works - 技术社区对 Dreaming V3 架构机制的深度分析
- IT之家 - OpenAI 升级 ChatGPT 记忆系统 - 中文科技媒体的官方发布报道