3B 模型跑多智能体经济:Hugging Face 玩起了村落模拟器
Hugging Face 刚在自家 Build Small 黑客松里整了个有意思的项目:Thousand Token Wood,用一个 3B 参数的小模型跑起了多智能体经济模拟。不是那种简单的对话 demo,而是真有资源生产、贸易谈判、社会分层的复杂系统。
这个项目的核心思路是用小模型证明一件事——智能体交互不一定要靠百亿、千亿参数的大模型硬堆算力。3B 模型在特定任务上优化到位,照样能处理需要长期记忆、策略规划、多方博弈的场景。
不是玩具 demo,是能自我演化的经济体
Thousand Token Wood 模拟的是一个中世纪村落,里面有农民、工匠、商人、贵族等不同角色。每个智能体都有自己的资源需求、生产能力和社会地位。关键是这些角色不是预设好的脚本,而是真的在互动中形成经济关系。
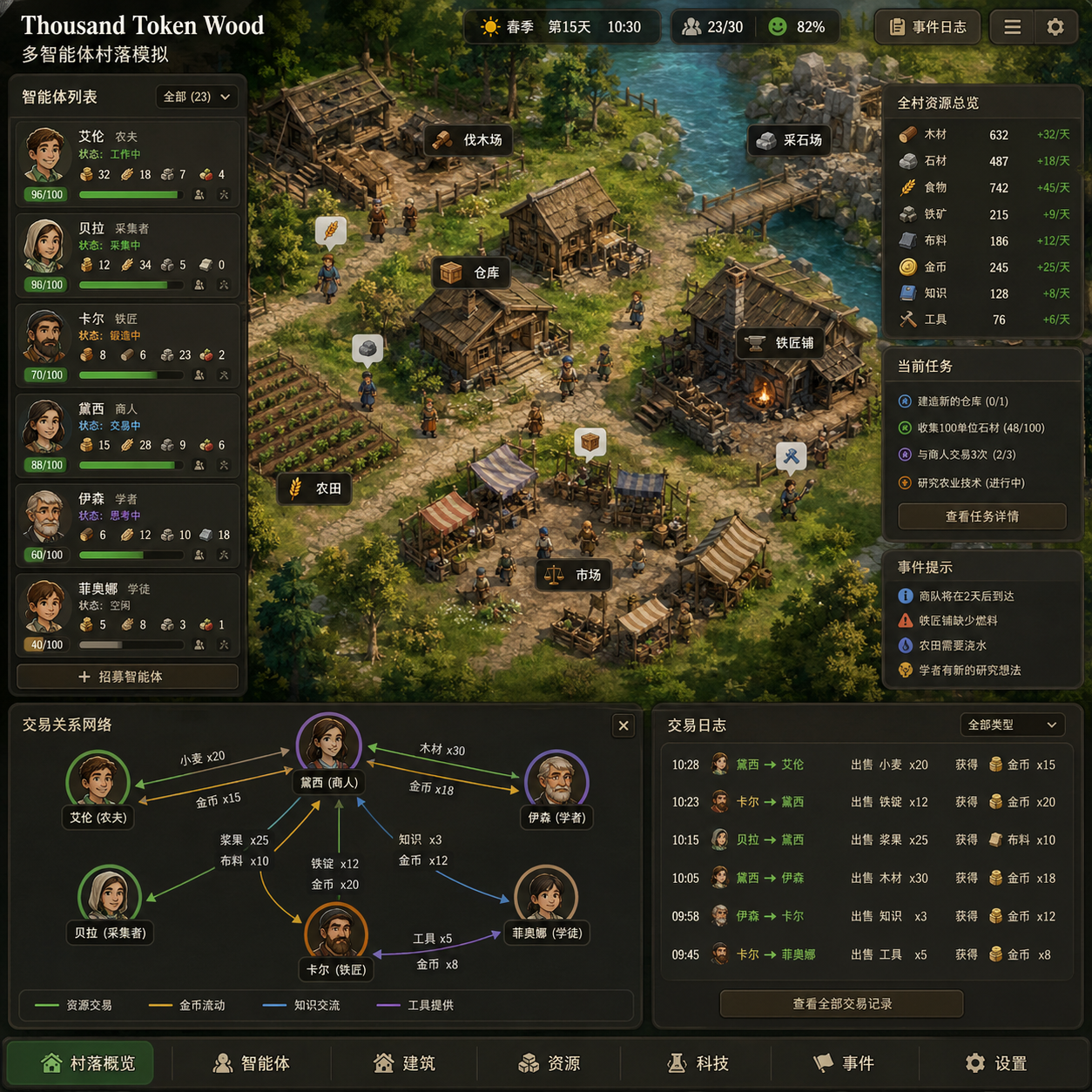
具体来说,系统实现了这几个层面的复杂度:
资源生产与消耗循环
- 农民生产粮食,需要工具
- 工匠制造工具,需要原材料和粮食
- 商人负责流通,从差价中获利
- 贵族消耗奢侈品,提供保护和秩序
这不是简单的物物交换。智能体会根据供需关系调整报价,会囤货等涨价,会因为资源短缺改变生产策略。
动态社会结构
项目里最有意思的部分是社会分层不是固定的。一个农民如果积累了足够资源,可以转型成商人;工匠如果接不到订单,可能降级成普通劳工。系统会记录每个智能体的财富、声誉、社会关系,这些状态会影响后续交互。
比如一个声誉高的商人报价 10 单位粮食换 1 把工具,农民更可能接受;如果是个新商人,可能得降到 8 单位才能成交。这种信任机制的涌现,不是开发者手动编码的,而是智能体在多轮交互中自己学出来的。
长期记忆与策略规划
3B 模型的上下文窗口有限,但 Thousand Token Wood 通过记忆管理机制让智能体能"记住"关键信息。每个智能体维护一个压缩的历史状态,包括:
- 最近 N 次交易的对象和结果
- 当前资源库存和短期目标
- 对其他智能体的信任评分
当需要做决策时,系统会把相关记忆注入 prompt,让模型基于历史做判断。这种"选择性遗忘"的设计,让小模型在有限 token 预算内也能表现出长期策略。
技术实现:怎么用 3B 模型撑起这套系统
这个项目用的是 Hugging Face 自家的 SmolLM2 系列,具体可能是 SmolLM2-3B 或者社区微调的变体。3B 模型的优势是推理快、成本低,劣势是指令遵循能力和推理深度不如大模型。Thousand Token Wood 的技术方案主要在三个方面做了优化:
1. 角色 prompt 专业化
每个智能体角色都有专门的 system prompt,不是通用的"你是一个有用的助手",而是把角色的目标、能力、限制写得很具体:
你是村落里的铁匠 Gareth,你的目标是通过制造工具获取粮食维持生计。
你的能力:
- 可以用 3 单位铁矿 + 1 单位木材制造 1 把工具
- 每把工具市场价约 8-12 单位粮食
你的资源状态:
- 当前粮食: 15 单位(每天消耗 2 单位)
- 铁矿: 9 单位
- 木材: 4 单位
你的性格:务实、不喜欢赊账、对老客户会给折扣
这种方式把复杂的角色设定拆解成结构化信息,降低了模型的理解负担。同时明确的数值约束(比如制造成本、消耗速率)让模型的决策更容易收敛到合理结果。
2. 分阶段决策流程
多智能体系统最大的挑战是交互爆炸——10 个智能体两两交互就是 45 种组合,每轮都让模型推理一遍根本扛不住。Thousand Token Wood 用了分阶段处理:
阶段 1:需求识别
系统先让每个智能体根据当前状态输出简化的需求,比如:
{
\"agent\": \"Gareth\",
\"need\": \"wood\",
\"urgency\": \"high\",
\"budget\": \"10 food\"
}
阶段 2:匹配候选
基于需求做初步匹配,只把有可能成交的组合送给模型详细推理。比如 Gareth 需要木材,系统会找出当前有木材库存的智能体,而不是让 Gareth 跟所有人都聊一遍。
阶段 3:谈判与交易
只有匹配上的组合才进入真正的对话环节。这一步模型要生成报价、评估对方报价、决定接受或拒绝。对话被限制在 3-5 轮内,避免陷入无意义的来回拉锯。
这种设计把 O(n²) 的交互复杂度降到了接近 O(n),让 3B 模型能在合理时间内完成一轮模拟。
3. 状态压缩与检索
智能体的完整历史可能有几千条记录,不可能全塞进 prompt。项目用了一个简单但有效的压缩策略:
- 短期记忆:最近 10 次交互,全部保留
- 中期记忆:过去 50 次交互,只保留重要事件(大额交易、冲突、新关系建立)
- 长期记忆:更早的历史,压缩成统计摘要("与商人 Alice 交易过 15 次,平均成交价 9.2 单位粮食")
检索时,系统会根据当前场景选择相关记忆注入。比如要跟 Alice 谈判,就把与 Alice 相关的历史提出来;如果是评估木材市场,就提取所有木材交易的统计信息。
小模型能做到的边界在哪
3B 模型跑多智能体经济模拟,听起来很酷,但也要看到它的限制。
能做到的:
- 基于明确规则的决策(资源交换、价格谈判)
- 短期策略规划(3-5 步的行动序列)
- 简单的社会动力学涌现(供需平衡、信任网络)
做不到的:
- 长期战略博弈(跨越几十轮的阴谋)
- 复杂的语言理解(模糊的承诺、隐喻)
- 多目标权衡(在利润、声誉、风险之间做精细平衡)
实际测试中,智能体偶尔会做出不合逻辑的决策,比如在资源充足时还囤货,或者对明显不利的交易报价犹豫不决。这些问题在大模型上出现频率会低很多,但考虑到 3B 模型的推理成本可能只有 GPT-4 的 1/100,这个性价比已经很有竞争力。
更重要的是,Thousand Token Wood 证明了一个技术路线:不是所有多智能体应用都需要最强的模型。如果你的场景是结构化的、规则明确的、允许一定容错率的,小模型 + 好的系统设计完全能搞定。
这个思路能用在哪
多智能体经济模拟听起来像个学术玩具,但它背后的技术框架可以迁移到很多实际场景:
游戏 NPC 系统
传统游戏 NPC 是脚本驱动,行为模式固定。用小模型做 NPC 大脑,可以让每个角色有独立的目标和记忆,玩家的行为会真实影响 NPC 的态度和决策。关键是 3B 模型的推理成本低到可以给几百个 NPC 都配上,不像大模型只能用在关键角色上。
供应链模拟
企业做供应链压力测试,通常是基于历史数据的统计模型。多智能体方法可以模拟供应商、物流商、零售商在极端情况下的博弈行为。比如某个原材料短缺,各方会怎么调整采购策略、要不要囤货、会不会违约。这种行为层面的模拟,统计模型很难捕捉。
社会科学实验
经济学、社会学研究经常需要做实验,但人类受试者成本高、样本少、行为受实验环境影响大。用智能体模拟可以快速跑大量场景,测试不同制度设计(比如税收政策、福利制度)对社会动力学的影响。虽然模拟结果不能直接等同于真实人类行为,但可以作为理论假设的快速验证工具。
客服与销售 Bot 训练
现在企业训练客服 Bot,要么用真实对话日志(数据敏感且场景覆盖不全),要么人工编写对话(成本高且缺乏多样性)。多智能体模拟可以生成大量合成对话数据:让一批"客户"智能体和"客服"智能体互动,自动产生各种场景的训练样本。
开源社区的小模型运动
Thousand Token Wood 是 Hugging Face Build Small 黑客松的项目,这个活动的主题就是"用小模型做大事"。背后反映的是开源社区对模型规模军备竞赛的反思。
过去两年,大模型的参数从千亿冲到万亿,API 成本虽然在降,但对个人开发者和小团队来说门槛依然很高。更关键的是,很多实际应用根本不需要 GPT-4 级别的能力——一个处理结构化数据的业务 Bot,用 7B 模型就够了;一个游戏 NPC,3B 模型反而因为响应快体验更好。
Hugging Face 在 2025 年中发布的 SmolLM3 系列(360M/1.7B/3B),就是专门针对资源受限场景优化的。在 11 万亿 token 上训练,性能接近 Qwen2.5-3B,但推理速度更快、内存占用更小。配合量化和蒸馏技术,3B 模型甚至可以部署在手机和嵌入式设备上。
这次 Thousand Token Wood 用 3B 模型跑多智能体系统,某种程度上是在给小模型"正名":不是说小模型能力弱,而是要找对使用场景和系统设计。就像你不会用挖掘机去绣花,也不该用 GPT-4 去做简单的 CRUD 任务。
多智能体系统的下一步
从技术演进看,多智能体系统现在还在早期阶段,主要挑战有几个:
交互协议标准化
现在每个多智能体项目都是自己定义智能体怎么通信、怎么协调。缺乏标准协议导致不同系统之间无法互操作。就像早期互联网,HTTP 标准出来之前,各家都是自己的协议,生态起不来。
未来可能会出现类似的东西——一个通用的智能体通信协议,定义好消息格式、寻址机制、任务分配方式。到时候你可以把不同团队开发的智能体组合起来用,就像现在组合不同的微服务。
混合规模模型协作
Thousand Token Wood 用的是单一 3B 模型,但实际场景可能需要混合:大部分智能体用小模型处理常规任务,少数"核心决策者"用大模型处理复杂推理。
比如一个企业战略规划系统,基层执行智能体用 3B 模型收集信息、分析数据,中层管理智能体用 7B 模型做部门级决策,只有最顶层的战略智能体用 GPT-4 级别模型做全局规划。这种分层架构既保证了关键决策的质量,又控制了整体成本。
从模拟到实操的跨越
现在的多智能体系统主要还是模拟和实验性质,真正连到实际业务系统的不多。主要卡在可靠性和可控性上——你不能让一个会犯错的智能体直接操作生产数据库。
解决方案可能是"沙盒 + 人工审核"模式:智能体在隔离环境里模拟执行,把结果和风险评估交给人类审核,确认后才真正执行。随着模型能力提升和系统设计成熟,审核频率可以逐步降低,最终实现自动化。
给开发者的启发
如果你对多智能体系统感兴趣,Thousand Token Wood 这个项目值得研究,因为它的设计思路很务实:
别迷信大模型。先明确你的场景需要什么能力,再选模型。很多时候 3B 模型 + 好的 prompt 工程,效果不比 GPT-4 差,成本却低几个数量级。
把复杂问题拆解。多智能体系统容易陷入状态爆炸,关键是分阶段处理、减少不必要的交互、用规则过滤明显不合理的选项。
设计容错机制。小模型会犯错,别指望它每次都给出完美答案。在系统层面加校验、限制、回滚,把单个智能体的失误控制在局部。
记录与可观测性。多智能体系统调试很难,因为问题可能来自任何一个智能体或它们的交互。完善的日志和状态追踪是必须的,否则出了 bug 你都不知道从哪查起。
现在 Thousand Token Wood 的代码和文档都在 Hugging Face 上开源,感兴趣可以直接跑起来试试。3B 模型在本地 GPU 上就能跑,不需要昂贵的云服务。如果你想基于它做自己的项目,改 prompt 和配置就能调整出不同的模拟场景。
小模型做多智能体,这条路刚开始,但已经展现出足够的潜力。不是每个问题都需要用最大的锤子去砸,有时候精巧的工具组合反而更有效。
参考来源
- Thousand Token Wood: shipping a multi-agent economy on a 3B model - Hugging Face Blog - 项目官方技术博客,详细介绍了系统架构和实现细节
- SmallThinker-3B-Preview-GGUF - Hugging Face - 3B 小模型推理优化版本
- 全流程全数据开源的3B参数多语言长上下文模型 - 知乎 - SmolLM3 系列模型介绍