微软 MAI 模型训练数据争议:「干净」承诺遇到 Common Crawl
微软 MAI 系列模型刚发布几个月,就因为训练数据来源问题被打脸了。
科技媒体 The Decoder 昨天(6 月 5 日)发布报道,称微软在 MAI 技术论文中披露的训练数据构成,与其此前对外宣称的「完全基于企业级、干净且商业授权数据」存在明显不符。论文显示,MAI 模型的训练数据不仅包括授权语料,还包含 Common Crawl 这类从公开互联网抓取的数据集。
这不是个小问题。去年 8 月微软推出 MAI-1 预览版时,AI 部门 CEO Mustafa Suleyman 强调这是「从头到尾自主训练的基础模型」,并特别强调未使用第三方模型蒸馏数据。这种表述给外界的印象是:微软走的是正规军路线,所有训练数据都经过合法授权,和那些靠爬公网数据起家的模型不一样。
但技术论文说的是另一回事。
技术论文里的真实数据来源
根据微软披露的技术文档,MAI 模型采用的是「公开可得数据」(publicly available data)与「授权的人类生成数据」(licensed human-generated data)的混合方案。前者包括 Common Crawl 这类互联网抓取数据集,后者才是真正经过商业授权的内容。
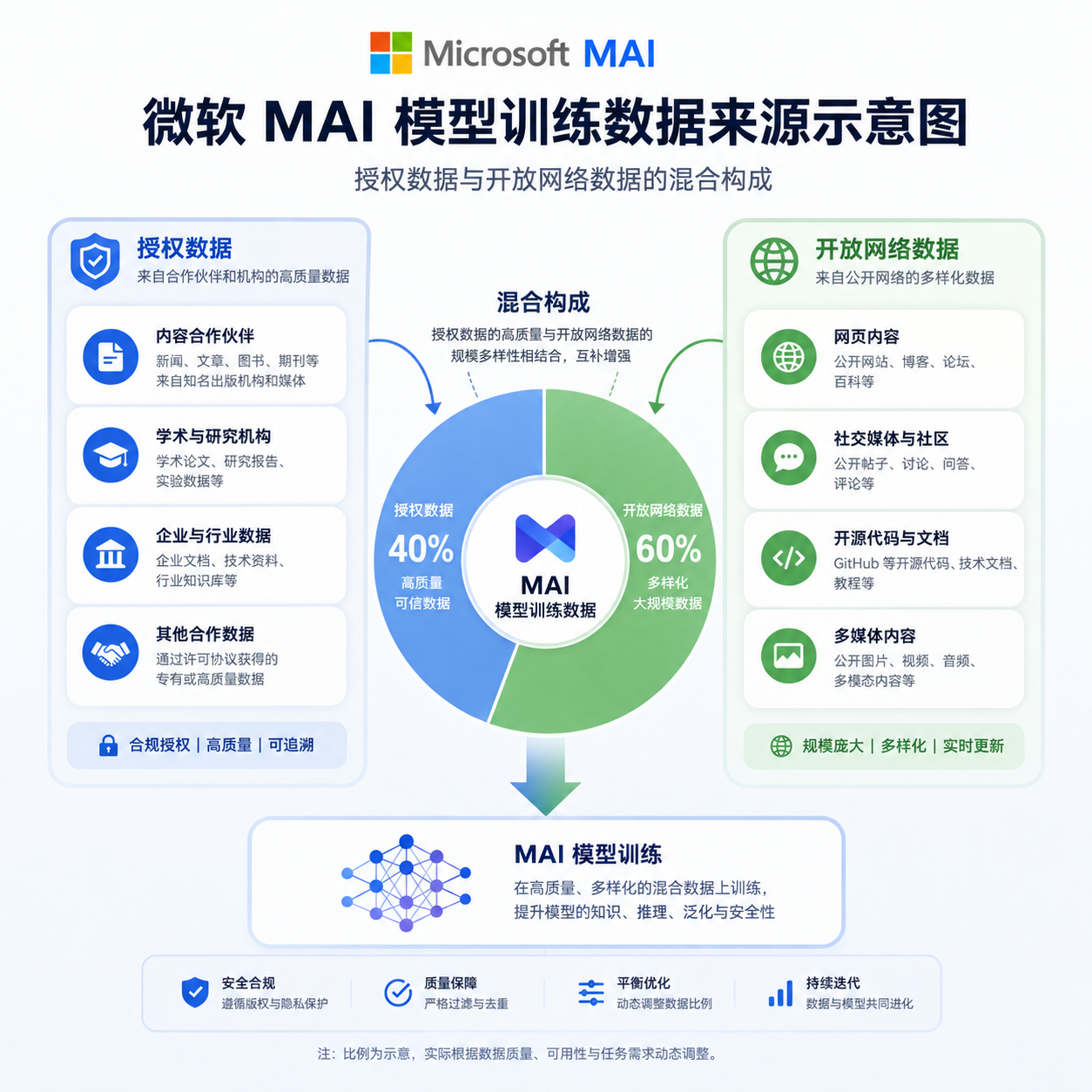
Common Crawl 是什么?这是一个非盈利组织维护的公开网页抓取项目,从 2008 年开始定期爬取互联网内容并开放数据集。GPT-3、LLaMA、Stable Diffusion 等几乎所有主流大模型都用过它。问题在于,Common Crawl 收录的内容是否合法使用,一直存在争议——它确实是「公开可得」的,但「公开」不等于「授权」。
微软在论文中对这一点的处理方式也颇为微妙。他们称使用自有爬虫收集网络数据,并遵守 Robots Exclusion Protocol(robots.txt)和相关 HTML 元标签。换句话说,只要网站没有主动屏蔽,就默认视为可以抓取。
The Decoder 对此的评价一针见血:这种逻辑类似于「没锁门就等于同意进入」。责任被推给了内容提供方——你想保护自己的内容?那就得主动配置 robots.txt 或元标签。不配置?那我就当你默认同意了。
这不是第一次,也不会是最后一次
微软这次暴露的问题,本质上是整个 AI 行业都在面对的困境:如何在「需要海量数据」和「版权合规」之间找到平衡。
今年 3 月,大英百科全书起诉 OpenAI 未经授权使用近 10 万篇百科全书文章训练 ChatGPT,并指控生成内容「近乎逐字复制」原文。OpenAI 的回应是老一套:「基于公开可获得数据,符合合理使用原则」。但出版商显然不买账——如果 AI 通过摘要分流了原本访问网站的用户,这不是「转化性使用」,而是商业模式层面的生存威胁。
类似的案例还包括作家群体起诉 Meta 使用盗版电子书训练 LLaMA 模型,以及多家新闻机构对 AI 公司的集体诉讼。AI 公司的辩护逻辑基本一致:合理使用、转化性创作、推动创新。但法律判例尚未形成共识,这些案件大多还在审理中。
有意思的是,部分媒体机构已经选择了合作而非对抗。新闻集团今年 3 月与 Meta 达成每年最高 5000 万美元的内容授权协议,英国出版商 Reach 也和亚马逊就 Nova AI 模型签订按使用量付费的协议。这说明「授权模式」是可行的,只是成本高、谈判慢,不如直接爬公网数据来得快。
微软的两难:自研路线与 OpenAI 关系
微软推出 MAI 系列模型,本身就是在与 OpenAI 的关系中寻找新的平衡点。
过去几年,微软累计向 OpenAI 投资超过 130 亿美元,并通过 Azure 提供核心算力支持。但 OpenAI 最近开始更多依赖 CoreWeave、谷歌和甲骨文的云服务,微软在去年甚至将 OpenAI 列入年度报告的竞争对手名单,与亚马逊、苹果、谷歌和 Meta 并列。
这个背景下,MAI 系列模型的意义不仅是技术层面的「拥有自研能力」,更是战略层面的「减少单一依赖」。Suleyman 在接受采访时也明确表示,微软未来会使用多种模型来源,包括 OpenAI、开源模型和自研模型,关键是通过「编排器」(orchestrator)决定何时调用哪个模型。
但 MAI-1 的表现目前还不算亮眼。在 LMArena 排行榜上,它排在第 13 位,落后于 Anthropic、DeepSeek、谷歌、Mistral、OpenAI 和 xAI 的模型。微软强调这只是预览版,性能会随着用户反馈不断提升,但要追上头部模型,还需要时间和投入。
与此同时,微软还推出了语音生成模型 MAI-Voice-1,号称能在单张 GPU 上不到一秒生成一分钟高保真音频,已经集成到 Copilot Daily 和 Podcasts 等应用中。相比 MAI-1 的排名尴尬,语音模型的落地速度和效率倒是展现了微软在特定垂直领域的执行力。
「干净数据」到底有多干净?
回到训练数据本身,微软这次的问题不在于使用了 Common Crawl,而在于表述上的模糊和前后不一致。
如果从一开始就说「我们使用了混合数据来源,包括授权语料和经过筛选的公开网络数据」,这没什么好质疑的——几乎所有模型都是这么干的。但微软选择的宣传策略是强调「企业级、干净且商业授权」,给外界留下了「完全不碰灰色地带」的印象。技术论文一出,这个印象就站不住脚了。
更深层的问题是,「干净数据」这个概念本身就缺乏统一标准。是指没有盗版内容?没有有害信息?还是所有来源都经过法律授权?不同公司的定义不一样,监管层面也没有明确界定。
微软在论文中提到他们使用了自有爬虫,并遵守 robots.txt 协议。这在技术层面是负责任的做法,但在法律层面依然存在争议空间。robots.txt 只是一个「君子协定」,不是法律文件。遵守它能减少道德风险,但不能完全规避版权诉讼。
从实际效果看,MAI 模型在 1.5 万张 H100 GPU 上完成训练,这个规模在当下算中等偏小。Suleyman 强调他们展示了「可以在相对较小的集群上训练出世界级性能」,这说明数据筛选和训练效率确实做得不错。但这也从侧面印证,训练数据来源的多样性(包括公网数据)对模型性能有直接影响。
行业需要新的共识
AI 训练数据的版权问题,最终需要通过立法和行业共识来解决,而不是靠各家公司各说各话。
欧盟的 AI Act 已经在数据使用透明度上提出了要求,要求 AI 公司披露训练数据来源并遵守版权法。美国方面,多个州也在推动类似立法,但联邦层面尚未形成统一规则。在此之前,「合理使用」的边界会在一个又一个诉讼案中被反复测试。
对开发者来说,这意味着在选择模型时,除了性能、成本和 API 兼容性,还得考虑模型提供方的数据合规性。虽然使用模型本身不会直接承担版权责任,但如果模型因版权问题被下架或受限,依赖它的应用也会受影响。
微软这次的争议,本质上是整个行业都在经历的阵痛:从「能用就行」到「合规可持续」的过渡期。MAI 模型的技术能力没问题,数据策略的透明度还需要改进。对于一个市值全球第一、声称要「负责任地推动 AI 发展」的公司来说,标准应该更高一些。
参考来源
- 微软 MAI 系列 AI 模型训练数据曝光,「仅商业授权」说法存在出入 - IT之家 — IT之家关于微软 MAI 模型训练数据争议的报道
- 微软推出两款 MAI-1 系列自研模型,下一代模型 MAI-2 研发工作已启动 - 腾讯新闻 — 微软 MAI 系列模型发布背景及技术细节