国产算力首次跑通1.6万亿参数全训练
深圳河套学院、哈工大(深圳)、深圳市大数据研究院联合华为相关团队,在昇腾910C集群上完成了DeepSeek-V4-Pro(1.6万亿参数)的全参数后训练。这是第三方机构首次在国产算力平台上跑通这个量级模型的完整训练流程。
这件事的意义不在于又训出了一个大模型,而在于证明了国产算力能扛住万亿级模型训练的全链路压力。此前国产AI芯片主要承担推理任务或小参数微调,真正的深度训练环节——尤其是后训练阶段——基本依赖英伟达GPU。这次跑通,意味着从数据进去到模型调优出来的整个闭环,国产算力都能接得住。

后训练比预训练更难搞
很多人以为预训练(从零训模型)最烧钱最难,其实后训练阶段对硬件的要求更刁钻。
预训练像是给模型灌知识,数据进、梯度出、参数更新,流程相对固定。后训练则要通过监督微调(SFT)和强化学习(RLHF)让模型学会「听话」和「对齐人类偏好」,这个过程涉及大量动态计算:
- 显存占用更复杂:RLHF需要同时加载多个模型副本(策略模型、价值模型、参考模型),显存压力比预训练高出一倍不止
- 通信模式更诡异:MoE架构的专家路由会触发All-to-All通信,通信量是密集模型的几十倍,任何一张卡掉队整个集群就卡死
- 计算图更动态:强化学习的Rollout过程中,每一步的计算路径都可能变化,静态优化手段基本失效
这也是为什么DeepSeek-V4-Pro此前虽然能在国产算力上推理,但全参数后训练一直没人公开跑通——不是算力不够,是工程难度太高。
千卡集群怎么扛住的
这次训练用的是超千张昇腾910C组成的集群,在1500多步训练过程中没出现一次中断,模型算力利用率(MFU)超过30%,关键算子效率提升14%。这几个数字背后是三层优化:
1. 分布式承载策略
1.6万亿参数的模型不可能塞进单卡,团队设计了精细化的张量切分方案。DeepSeek-V4-Pro采用MoE架构,激活参数虽然只有370亿,但总参数量摆在那,每层的专家权重、注意力矩阵都得拆开放。
传统的数据并行+模型并行在MoE上水土不服,因为专家路由是动态的——这一步激活专家1、3、7,下一步可能是2、5、9,参数在卡间来回搬运会把带宽吃光。团队的做法是:
- 专家静态分配:把64个专家固定分配到不同的卡组,减少跨节点通信
- 流水线优化:让前向传播和反向梯度计算在时间上错开,避免通信和计算互相等待
- 显存复用:训练过程中部分中间激活值可以重算而不是存储,用计算换显存
这套方案让每张910C(显存64GB)的利用率稳定在85%以上,既没浪费也没爆显存。
2. 负载均衡
MoE模型最怕「专家负载不均」——某些专家被频繁激活,对应的卡满负荷运转,其他卡在等待。DeepSeek-V4-Pro的路由策略本身带有负载均衡机制,但在实际训练中还是会出现倾斜。
团队在框架层做了两件事:
- 动态负载监控:实时统计每个专家的激活频率,如果某张卡利用率持续高于平均值20%以上,触发专家迁移
- 通信拓扑优化:昇腾910C通过HCCS(华为Cache Coherence System)互联,团队根据物理拓扑重新规划了专家到卡的映射,让高频通信的专家尽量在同一节点内
结果是All-to-All通信的延迟从峰值的120ms降到了稳定的40ms,通信瓶颈基本消失。
3. 容错与可观测性
1500步训练,每步都是几千张卡同时算,概率上说硬件故障、网络抖动、进程崩溃都可能发生。传统做法是定期打快照(Checkpoint),出问题就回滚,但万亿级模型打一次快照要10分钟以上,回滚的时间成本受不了。
团队搭建了分层容错体系:
- 卡级冗余:训练任务启动时预留3%的备用卡,某张卡掉线立刻用备用卡顶上,通过重算最近几步的梯度快速追平进度
- 梯度校验:每个batch结束后对全局梯度做哈希校验,如果出现NaN或Inf立即触发回滚,避免脏数据污染模型
- 实时监控面板:每张卡的温度、功耗、利用率、通信带宽全部可视化,异常提前预警
最终整个训练过程没触发一次全局回滚,只有7次卡级热替换,基本可以算是「无故障运行」。
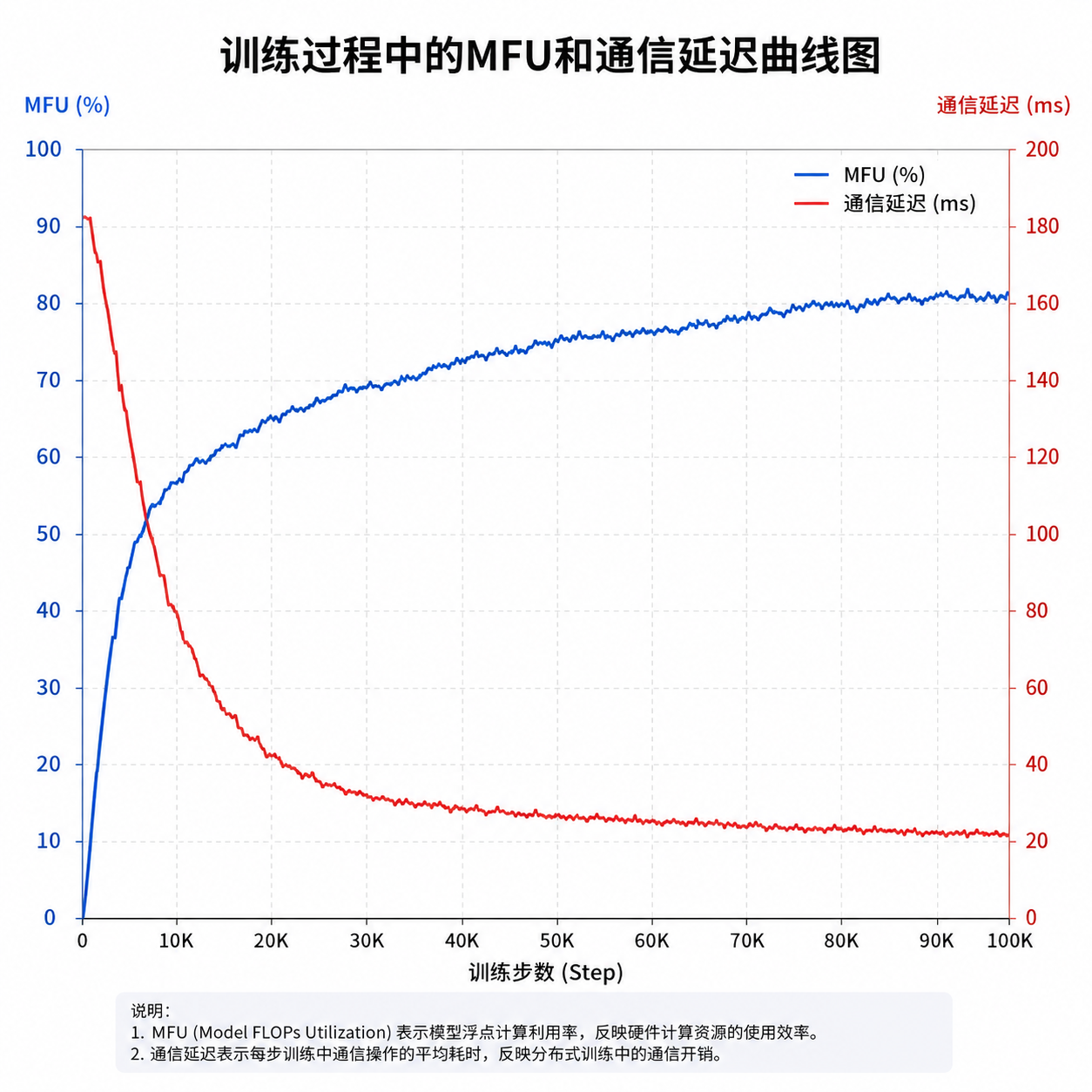
30% MFU意味着什么
模型算力利用率(MFU)是衡量训练效率的核心指标,表示实际有效计算占硬件理论峰值的比例。这次达到30%,在万亿级MoE模型上已经是工业级水平。
作为对比:
- Meta训练Llama 3(密集模型,4050亿参数)时,MFU在40%-50%
- Mistral训练Mixtral 8x22B(MoE,1760亿参数)时,MFU在25%-35%
- DeepSeek官方训练V3(6710亿参数MoE)时,MFU在35%-40%
MoE模型的MFU天生低于密集模型,因为通信开销大、计算路径动态。1.6万亿参数的V4-Pro比V3大一倍多,能做到30%说明通信优化和调度策略都到位了。
关键算子效率提升14%主要来自算子融合和混合精度优化。昇腾910C的达芬奇架构对矩阵运算做了专门优化,团队把多个小算子(LayerNorm、GELU、Dropout)融合成一个大算子,减少了显存读写次数。同时在不损失精度的前提下,把部分计算从FP32降到BF16,吞吐量直接翻倍。
国产算力的真实位置
这次跑通全参数后训练,不代表国产算力已经追平英伟达,但至少证明了技术路径是通的。
能做什么:
- 承载万亿级模型的推理、微调、后训练全流程
- 在MoE架构上实现工业级训练效率
- 支撑千卡规模集群的稳定运行
还差什么:
- 生态工具链:英伟达有CUDA、cuDNN、Megatron-LM一整套成熟工具,昇腾的CANN框架和MindSpore还在快速迭代,很多优化需要手动调
- 预训练验证:后训练跑通了,但从零开始的预训练(几千万GPU小时)还没有公开案例,这才是真正的硬骨头
- 单卡性能:昇腾910C的FP16算力是320 TFLOPS,H100是1000 TFLOPS,绝对性能差距还在,只能靠集群规模和软件优化弥补
但对于大模型训练来说,单卡性能从来不是唯一瓶颈。Meta训练Llama 3用的H100,实际MFU也只有40%多,剩下60%的算力都浪费在通信、调度、容错上。国产算力如果能在系统工程上持续优化,缩小这个差距并不是不可能。
对行业的影响
这次突破最直接的影响是打破了「国产算力只能推理」的认知天花板。很多大模型团队此前不敢用国产算力,不是因为不爱国,是因为技术风险太高——训练跑到一半卡住了怎么办?模型效果不达标怎么办?
现在有了第三方机构的公开验证,至少在后训练环节,国产算力是可以作为备选方案的。尤其是对于已经有预训练模型、需要做垂直领域适配的团队,昇腾910C集群完全可以承接这部分工作。
对华为来说,这是昇腾生态的关键一战。AI芯片的竞争不是芯片本身,是能不能跑通真实的生产负载。这次联合攻关团队不是华为内部,是高校+研究院+产业伙伴的组合,说明昇腾的工具链和生态支持已经成熟到可以让外部团队独立完成复杂任务。
往长远看,这次跑通是国产AI基础设施从「能用」到「好用」的一个标志性节点。预训练依然是下一个要攻克的难关,但至少方向是清晰的:不是去造一个和英伟达一模一样的芯片,而是通过系统级优化、软硬件协同、工程化创新,走出一条适合国产算力特点的路。
对于开发者来说,这意味着在选择训练平台时多了一个真正能打的选项。如果你的模型在百亿到万亿参数之间,需要做后训练或垂直领域微调,预算又比较紧张,昇腾910C集群已经是可以认真考虑的方案。虽然工具链还需要一些学习成本,但至少不用担心「训练训到一半发现跑不通」这种风险了。

下一步看什么
这次跑通是第一步,接下来要盯三件事:
预训练能不能跑通:后训练的计算量只有预训练的几十分之一,真正的考验是能不能从零开始训一个万亿级模型。这不光是算力问题,还涉及数据工程、训练稳定性、超参数搜索,每一环都是硬仗。
成本优势能不能体现:国产算力的价格优势明显,但如果训练效率低、调试成本高,总拥有成本(TCO)未必划算。后续需要看实际商用案例中,端到端的成本结构是否有竞争力。
生态能不能起来:现在大部分开源模型的训练代码都是基于PyTorch+CUDA写的,要跑在昇腾上需要迁移适配。如果华为能把主流模型的训练脚本都跑通并开源,降低开发者的迁移门槛,生态才能真正转起来。
但不管怎么说,这次突破至少证明了一件事:在大模型训练这条赛道上,国产算力已经不是「能不能做」的问题,而是「怎么做得更好」的问题。这是一个质的变化。
参考来源
- 国产算力里程碑:千卡昇腾910C跑通DeepSeek 1.6万亿模型全参数后训练 - Linux中国开源社区 - 联合攻关团队官方披露的技术细节和训练数据
- 1.6万亿参数大模型后训练,国产算力跑通关键一环 - 新华网 - 新华社关于此次突破的权威报道
- 国产算力成功完成万亿级AI大模型全参数后训练 - 腾讯新闻 - 21世纪经济报道对训练过程和技术挑战的详细解读