Anthropic花1000万美元让人类教AI写代码
Anthropic正在用一种看起来有些「反潮流」的方式训练Claude Code——雇1000名真人工程师做数据标注,每项任务支付280美元。
这个代号"Marlin"(马林鱼)的项目由数据标注公司Snorkel AI执行。据Business Insider披露,参与项目的外包工程师需要对两个不同模型生成的代码做A/B测试,挑出更符合实际开发场景的那个,并判断模型是否真正理解了prompt里的技术要求。一项任务平均耗时一小时,但考虑到需要和Snorkel审批层多轮沟通,实际时薪可能低于280美元。

不是缺数据,是缺「对的」数据
大模型公司普遍面临一个困境:公开代码库已经被爬得差不多了,继续扩大训练数据规模的边际收益在递减。Anthropic这次选择的路径是精细化——与其让模型见更多代码,不如让它理解什么样的代码是「好的」。
参与项目的外包人员透露,Marlin的核心目标是训练Claude Code生成"更简化、更易于维护"的代码。这个表述很微妙。在实际开发中,能跑的代码和好维护的代码是两回事。前者可能嵌套五层循环解决问题,后者会拆成三个清晰的函数。模型在GitHub上学到的更多是前者,因为那些能跑通就提交的代码占绝大多数。
Snorkel AI这家公司的背景也值得说。它不是传统的数据标注血汗工厂,而是斯坦福出来的团队,主打「弱监督学习」——用少量高质量标注撬动大规模数据。Anthropic把这个项目交给它,说明看重的不是标注量,而是标注质量和工程师背景的真实性。
280美元一小时,值不值?
这个价格放在外包市场算中等偏上。硅谷资深工程师时薪普遍在150-300美元,但那是全职岗位的折算,包含福利和稳定性。Marlin项目的外包工程师拿的是纯任务费,没有五险一金,也不知道下个月还有没有活。
更关键的问题是规模。1000名工程师如果持续工作一个月(按每天8小时、每月20个工作日算),总成本是280美元 × 8小时 × 20天 × 1000人 = 4480万美元。即使项目只运行几周或工程师并非全部满负荷,这个数字也轻松过千万美元。对比OpenAI训练GPT-4传闻中的上亿美元算力成本,Anthropic这笔钱花得不算多,但方向完全不同——它在买人类判断力,而不是GPU集群。
这种做法在业内不算新鲜。OpenAI的RLHF(人类反馈强化学习)本质也是雇人打分,但Anthropic这次的特殊之处在于规模和专业度:不是随便找人标"这个回答好不好",而是要求标注者本身就是能写生产代码的工程师,去评判代码的可维护性、架构合理性这些需要经验才能判断的东西。

Claude Code到底在学什么?
外包人员不知道自己评估的是哪个版本的模型,但从项目设计可以推测Anthropic的意图。
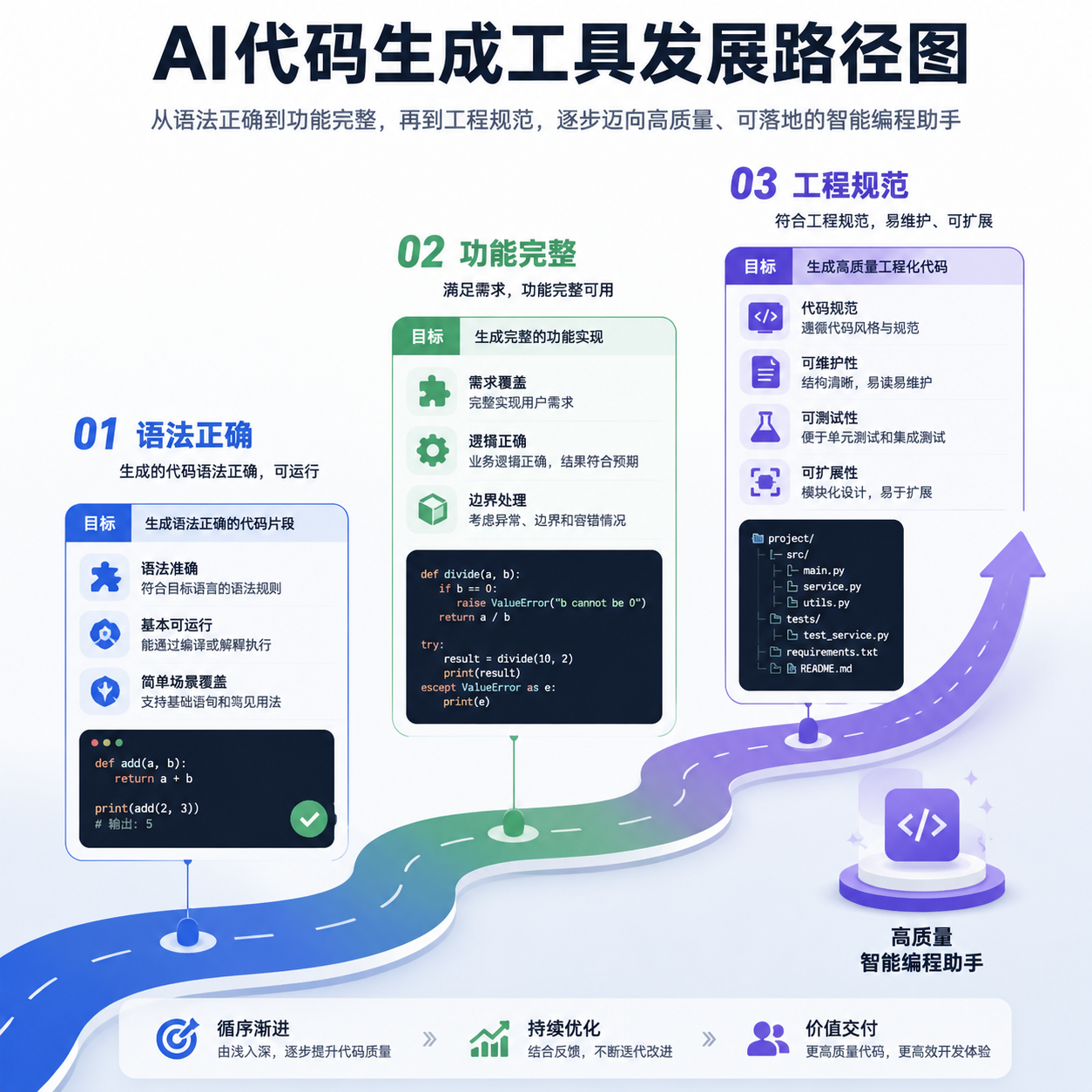
传统的代码生成模型训练更像是"填空题":给定上下文,预测下一行代码最可能是什么。这种方式让模型学会了语法和常见模式,但学不会「为什么这样写更好」。Marlin项目引入的A/B测试机制,本质是在教模型做选择题:两段都能实现功能的代码,哪个更符合工程实践?
这种训练方式对齐的是开发者的隐性知识。比如:
- 命名规范:变量叫
userData还是ud?前者冗长但清晰,后者简洁但三个月后没人记得是什么 - 错误处理:直接
try-catch包住整个函数,还是在关键节点细粒度捕获?前者省事但调试地狱,后者繁琐但可控 - 抽象程度:五行代码要不要抽成函数?过早抽象是万恶之源,但复制粘贴三次就该重构了
这些判断标准在教科书上写不清楚,在Stack Overflow上也很难量化,只能靠有经验的工程师case by case地权衡。Anthropic现在做的事,就是把这种权衡能力规模化地灌输给Claude Code。
开发者适配度是个真问题
代码生成工具这两年的最大槽点不是"写不出来",而是"写出来的不是我想要的"。GitHub Copilot早期版本经常自作主张补全一大段,开发者得逐行检查有没有埋坑。Claude Code之前的版本也有类似问题:给它一个复杂需求,它会生成一个看起来很完整的方案,但细看会发现有些边界条件没考虑,有些依赖关系理错了。
这就是"适配度"问题。模型和开发者的心智模型不匹配。开发者说"写个用户认证模块",脑子里想的是JWT + Redis缓存 + 权限中间件这套标准方案。模型可能给你写个session based的实现,或者直接上OAuth2把问题复杂化。技术上都没错,但不是这个场景下的最优解。
Marlin项目如果成功,Claude Code会更懂这些"不成文的规矩"。它会知道在什么技术栈下,开发者期待什么样的默认选择;会知道什么时候该保守(金融系统就别花里胡哨),什么时候可以激进(内部工具无所谓)。
对标的是谁?
GitHub Copilot现在的市场份额最大,但它的训练方式更依赖GitHub上的海量代码。优势是见多识广,劣势是鱼龙混杂。你永远不知道它学到的某个模式是来自Google的内部工具还是某个大学生的课程作业。
Cursor和Codeium这些新玩家走的是工程化路线:更好的IDE集成、更精准的上下文理解、更快的响应速度。它们在交互体验上卷得很细,但底层模型能力还是依赖OpenAI或Anthropic。
Anthropic这次的打法有点"降维打击"的意思。别人在卷产品形态,它回到模型层面解决代码质量问题。如果Claude Code真的能稳定输出"更易维护"的代码,那它在企业市场的吸引力会显著提升——毕竟技术债是CTO的头号敌人。
这种方式能持续吗?
短期看,Marlin项目是有效的。人类工程师的判断可以快速校准模型的输出偏好,让它在几个月内就接近"资深开发者"的代码品味。
但长期看,这种方式有规模上限。代码的"好坏"没有绝对标准,不同公司、不同团队、不同项目阶段的偏好都不一样。Google推崇的代码风格在创业公司可能就是过度设计。Anthropic现在雇的这1000名工程师,他们的偏好能代表整个开发者群体吗?
更根本的问题是:如果模型已经足够理解代码,为什么还需要人类来教它什么是"好代码"?这暗示当前的模型架构在某些方面还是有局限——它能记住模式,但理解不了原则。
Anthropic可能在押注一个中间状态:模型还不够智能到自己领悟工程美学,但已经足够智能到能从人类反馈中快速学习。如果这个窗口期够长,那花几千万美元买人类判断力就是值得的。如果下一代模型直接跨过这个阶段,那Marlin项目就是个过渡方案。
开发者该担心什么?
不是失业。至少现在不是。
Marlin项目恰恰说明,当前AI最缺的不是写代码的能力,而是理解「为什么这样写」的能力。只要这个gap存在,人类工程师的价值就在。
但这个项目确实在压缩某一类工作的空间:那种机械性的、模式化的编码任务。如果你的日常工作是"把产品需求翻译成标准CRUD",那Claude Code进化到下一阶段时,你的竞争力会削弱。
反过来,如果你的价值在于架构决策、技术选型、性能优化、跨团队协调这些需要上下文和判断力的事,AI短期内顶不了。Marlin项目的工程师们现在做的事——评估代码质量、权衡技术方案——正是AI还学不会的那部分。
讽刺的是,Anthropic在用人类来训练AI的同时,也在证明人类的某些能力暂时还无法被替代。280美元一小时的标注费,某种程度上就是这个gap的市场定价。
数据标注的尽头
这个项目还折射出大模型训练的一个深层矛盾:越往后走,瓶颈越不在算力,而在数据。
OpenAI、Anthropic、Google这些公司都快把互联网爬穿了。下一步要么去买专有数据(版权问题),要么合成数据(质量问题),要么像Marlin这样搞大规模人工标注(成本问题)。每条路都不轻松。
Snorkel AI的商业模式也很有意思。它实际上是在把"数据质量"这个模糊的概念产品化、服务化。以前数据标注是血汗工厂,现在变成了"工程师即服务"。等哪天模型真的不再需要人类反馈,这个行业又得找新的存在价值。
从这个角度看,Marlin项目既是Anthropic在追赶代码生成赛道的战术动作,也是整个行业在「后预训练时代」的一次战略试探——大家都在摸索,当公开数据用尽后,下一个规模化的质量提升点在哪里。
Anthropic的答案是:让最懂代码的人,来教AI什么是好代码。这个逻辑简单粗暴,但可能有效。至于能持续多久,就看下一代模型什么时候能自己悟出来了。
参考来源
- IT之家 - Anthropic 被曝雇1000名人类工程师训练Claude Code - 项目细节披露,包括定价和工作流程