OpenCV 5 发布:DNN 引擎重构,直接跑 Transformer
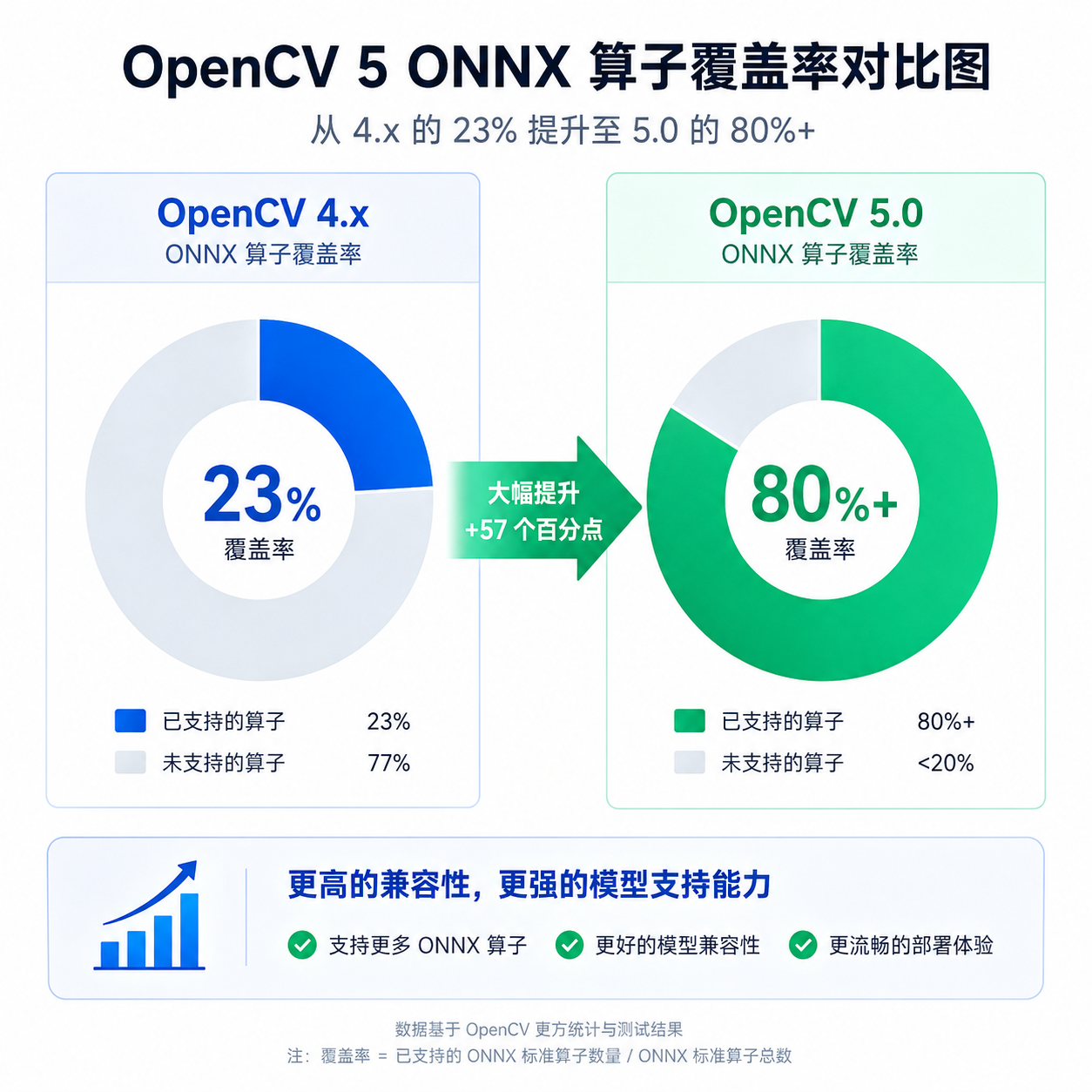
OpenCV 团队今天正式发布 5.0 版本,这是这个计算机视觉库 20 多年来最大的架构调整。核心变化是彻底重写了 DNN 模块,从过去"能用但难受"的推理层,变成了基于图优化的现代推理引擎,ONNX 算子覆盖率从 4.x 的 23% 直接跳到 80% 以上,现在可以直接加载 Transformer 模型和视觉语言模型了。
这个升级对 OpenCV 用户意味着什么?过去你在 PyTorch 或 TensorFlow 里训好模型,想用 OpenCV 部署到嵌入式设备或生产环境,经常遇到算子不支持、推理慢、硬件加速接不上的问题。OpenCV 5 的新 DNN 引擎解决的就是这些痛点:更完整的 ONNX 支持、算子融合优化、统一的硬件加速接口,以及对 FP16/BF16 这些现代数据类型的原生支持。
新 DNN 引擎:从"能跑"到"好用"
OpenCV 4.x 的 DNN 模块本质上是个推理运行时,但架构设计停留在 2016 年前后。它能加载 Caffe、TensorFlow、Darknet 这些早期框架的模型,但对复杂图结构和动态形状支持很弱,遇到 Transformer 的多头注意力、层归一化这些算子就抓瞎。
OpenCV 5 的新引擎彻底推倒重来,采用了基于计算图的架构。这意味着什么?模型加载后会先构建完整的计算图,然后做算子融合、常量折叠、内存优化这些编译器级别的优化,最后再执行。这套流程跟 TensorRT、ONNX Runtime 这些专业推理引擎是一个思路,只是 OpenCV 的实现更轻量,没有那么多依赖。
具体到算子支持,OpenCV 5 把 ONNX opset 13-19 的常用算子基本补齐了。官方给的数据是覆盖率超过 80%,这意味着你导出的 ONNX 模型大概率能直接跑,不用像以前那样手动改模型结构或者写自定义层。
更重要的是对 Transformer 的支持。OpenCV 5 可以直接加载 Vision Transformer(ViT)、CLIP、BLIP 这些视觉语言模型,也能跑纯文本的 BERT、GPT 这类模型(虽然用 OpenCV 跑 LLM 不是主流场景,但技术上可行了)。这背后是对 LayerNorm、GELU、Multi-Head Attention 这些 Transformer 核心算子的原生实现,而不是像 4.x 那样靠用户自己拼凑。
硬件加速:统一接口,不再依赖 #ifdef
过去 OpenCV 的硬件加速是个历史包袱。CUDA、OpenCL、Vulkan、各家芯片厂商的私有加速库,都是通过 #ifdef 条件编译硬塞进代码里的,维护起来像屎山。你想用英伟达 GPU 加速?编译时带上 CUDA。想用英特尔核显?再带上 OpenCL。想用华为昇腾或者瑞芯微 NPU?那得厂商自己提交 patch,代码库里全是平台相关的分支判断。
OpenCV 5 引入了一个新的硬件抽象层(HAL),把加速后端的接口标准化了。硬件厂商只需要实现这套接口,就能无缝接入 OpenCV 的推理流程,不用再往主代码库里塞条件编译。这套设计借鉴了 PyTorch 的 dispatcher 和 ONNX Runtime 的 execution provider,但实现更轻量。
对开发者来说,这意味着你写的代码不用关心底层是用 CUDA 还是 Vulkan 跑的,只需要在初始化时指定后端,OpenCV 会自动选择最优的算子实现。如果你的设备上有多个加速后端(比如英伟达 GPU + 英特尔核显),OpenCV 5 还能做自动回退:优先用 CUDA 跑,某些算子不支持就回退到 OpenCL 或 CPU。
这套机制也让国产硬件接入变得更容易。华为昇腾、寒武纪、海光这些厂商只需要按照 HAL 接口实现自己的后端,就能让 OpenCV 跑在自己的 NPU 或 AI 加速卡上,不用等 OpenCV 官方合并代码。
Python 绑定:终于不用靠猜了
OpenCV 的 Python 接口一直是个槽点。因为底层是 C++ 写的,Python 绑定是自动生成的,导致很多函数的参数顺序、默认值、类型提示都很混乱。你想调用一个函数,经常得去翻 C++ 文档或者源码,或者干脆靠 IDE 的补全猜。
OpenCV 5 重新设计了 Python 绑定生成器,支持命名参数(keyword arguments)和完整的类型提示。现在你可以这样写:
import cv2 as cv
# 以前:参数顺序全靠记
img = cv.resize(src, (640, 480), 0, 0, cv.INTER_LINEAR)
# 现在:命名参数,清晰直观
img = cv.resize(
src=src,
dsize=(640, 480),
interpolation=cv.INTER_LINEAR
)
类型提示也补全了,IDE 能直接告诉你每个参数应该传什么类型,返回值是什么。这对 Python 用户来说是体验上的质变,尤其是新手不用再去猜"这个参数是传元组还是列表"、"返回值是 numpy 数组还是 OpenCV 的 Mat 对象"。
另一个改进是 NumPy 集成。OpenCV 5 的张量类型可以直接跟 NumPy 数组互转,不需要额外的拷贝。这对数据预处理很有用:你可以用 NumPy 或 Pandas 处理数据,直接传给 OpenCV 做推理,再把结果传给 Matplotlib 可视化,整个流程零拷贝。
新数据类型:FP16/BF16 原生支持
OpenCV 4.x 只支持 FP32、INT8、INT16 这些传统数据类型,对 FP16 和 BF16 的支持是通过第三方库(如 Half)或者手动转换实现的,性能不好也不稳定。
OpenCV 5 把 FP16 和 BF16 作为一等公民,内置了高效的转换和计算内核。这对现代 AI 模型很重要:大部分 Transformer 模型训练时用的是 BF16 或 Mixed Precision,推理时用 FP16 能显著降低显存占用和延迟。OpenCV 5 可以直接加载 FP16 的 ONNX 模型,不用手动转换精度。
对硬件加速也有好处。英伟达的 Tensor Core、苹果的 ANE、ARM 的 Neon 这些硬件单元对 FP16 的支持比 FP32 好得多,OpenCV 5 的新引擎能自动利用这些硬件特性,推理速度能提升 2-4 倍。
3D 视觉:ChArUco 标定与多相机支持
除了 DNN 模块,OpenCV 5 在 3D 视觉方面也有显著改进。最实用的是对 ChArUco 标定板的原生支持。ChArUco 是一种混合了棋盘格和 ArUco marker 的标定板,比传统棋盘格更鲁棒,部分遮挡或光照不均时也能准确检测。
OpenCV 5 还增强了多相机标定功能,可以同时标定多个相机的内参和外参,这对立体视觉、SLAM、3D 重建这些场景很有用。以前你得手动写循环,分别标定每个相机再做坐标系转换,现在一个函数调用就能搞定。
可视化方面,OpenCV 5 引入了新的 3D 可视化模块,基于 VTK 或者 OpenGL 后端,可以直接渲染点云、网格、相机姿态这些 3D 数据。这对调试 SLAM 算法或者展示重建结果很方便,不用再依赖外部工具如 MeshLab 或 CloudCompare。
代码清理:C API 终于退役
OpenCV 从 1.x 时代继承下来的 C API(IplImage、CvMat 这些)在 5.0 里正式标记为废弃。这些 API 已经被 C++ 接口(cv::Mat)替代超过十年了,但一直保留着是为了向后兼容。现在 OpenCV 团队决定彻底清理,减少维护负担。
如果你的代码还在用 C API,升级到 OpenCV 5 需要迁移。好消息是迁移成本不高,大部分 C API 都有对应的 C++ 或 Python 接口,而且性能更好。官方提供了迁移指南,列出了常用函数的替代方案。
另一个清理是模块结构。OpenCV 4.x 有 20 多个模块,很多功能重叠或者用的人很少。OpenCV 5 把一些边缘模块移到了 opencv_contrib 仓库,核心库只保留最常用的模块,编译出来的二进制文件体积减少了约 30%。对嵌入式设备来说,这意味着更少的存储占用和更快的启动速度。
文档重写:终于能看了
OpenCV 的文档一直被吐槽"能用但难用"。API 参考是自动生成的,格式死板,缺少示例。教程质量参差不齐,有的是十年前写的,代码还在用 C API。
OpenCV 5 的文档全面重写,采用了现代化的文档框架(可能是 MkDocs 或 Docusaurus),排版清晰,支持暗色模式,搜索功能也好用了。每个 API 都有代码示例,覆盖 C++、Python、Java 三种语言。教程部分也更新了,增加了深度学习、3D 视觉、嵌入式部署这些热门话题的实战指南。
对行业的影响:推理部署的新选择
OpenCV 5 的升级,最直接的影响是给推理部署提供了一个新选择。过去你想在生产环境部署 AI 模型,要么用 TensorRT、ONNX Runtime 这些重量级框架,要么自己手写推理代码。TensorRT 性能好但只支持英伟达 GPU,ONNX Runtime 跨平台但依赖多、编译麻烦。
OpenCV 5 的定位介于两者之间:性能不如 TensorRT,但比 ONNX Runtime 轻量,编译简单,跨平台支持好。对嵌入式设备、边缘计算、移动端这些场景,OpenCV 5 可能是更合适的选择。尤其是那些已经在用 OpenCV 做传统视觉任务(如图像处理、特征提取)的项目,现在可以无缝集成深度学习模型,不用引入额外的依赖。
另一个影响是对国产硬件的支持。华为昇腾、寒武纪、海光这些厂商都在推自己的 AI 加速卡,但生态是个大问题。开发者不愿意学习每家的私有 API,更愿意用标准接口。OpenCV 5 的硬件抽象层提供了一个统一入口,国产硬件只需要实现这套接口,就能接入 OpenCV 的庞大用户群体。这对国产硬件的生态建设是个利好。
谁会用 OpenCV 5?
短期内,OpenCV 5 的主要用户会是这几类:
嵌入式 AI 开发者:需要在树莓派、Jetson、瑞芯微这些设备上部署视觉模型,对依赖和体积敏感,OpenCV 5 的轻量特性很适合。
工业视觉工程师:质检、缺陷检测、OCR 这些场景,传统视觉算法 + 深度学习模型混合使用,OpenCV 5 可以统一技术栈。
机器人开发者:SLAM、导航、抓取这些任务需要 3D 视觉 + 深度学习,OpenCV 5 的 3D 功能增强和 DNN 模块正好满足需求。
教育和科研:OpenCV 的开源、跨平台、文档完善,一直是教学和原型验证的首选,OpenCV 5 的易用性改进会进一步巩固这个地位。
对云端推理或者大规模生产部署,OpenCV 5 不一定是最优选择。TensorRT、ONNX Runtime、TVM 这些专业框架在性能和功能上还是更强。但对中小规模、边缘计算、快速原型这些场景,OpenCV 5 的性价比很高。
升级建议
OpenCV 5 不是一个无痛升级。C API 废弃、模块重组、部分函数签名变化,这些都可能导致旧代码编译失败。官方提供了迁移指南,但实际升级还是需要测试和调整。
如果你的项目满足以下条件,建议尽快升级:
- 需要部署 Transformer 或视觉语言模型
- 需要 FP16/BF16 推理加速
- 需要更好的 ONNX 兼容性
- 需要在国产硬件上运行
- Python 项目,受益于类型提示和命名参数
如果你的项目只用 OpenCV 做传统视觉任务(如滤波、边缘检测、特征匹配),或者代码量很大、迁移成本高,可以暂缓升级。OpenCV 4.x 还会维护一段时间,重大 bug 会修复,但新功能不会回迁。
彩蛋:GitHub Stars 破 86,000
OpenCV 在 GitHub 上的 stars 数已经超过 86,000,日安装量超过 100 万次。这个数字放在整个开源生态里也是头部水平,比 TensorFlow(约 18 万 stars)少一半,但比 PyTorch(约 7 万 stars)多,跟 scikit-learn(约 6 万 stars)在一个量级。
考虑到 OpenCV 是个底层库,不像深度学习框架那样有大量应用层开发者,这个数字已经很夸张了。它的用户覆盖学术界、工业界、开源社区,从博士生的科研项目到特斯拉的自动驾驶,从安防摄像头到手机相机,OpenCV 无处不在。
OpenCV 5 的发布,是这个 20 多年老项目的一次自我革新。它没有追求颠覆式创新,而是在保持向后兼容的前提下,逐步清理技术债、拥抱现代架构。对开发者来说,这意味着一个更好用、更强大、更面向未来的计算机视觉工具箱。
参考来源
- OpenCV 5 发布:升级全新 DNN 引擎、原生支持大模型 - IT之家 — 官方发布信息和主要特性介绍
- OpenCV GitHub 仓库 — 源码和技术细节