一份想当 Agent 时代 USB-C 的协议
几天前,一个叫 Universal Memory Protocol(以下简称 UMP)的开源项目悄悄上线,目标只有一句话:让所有 AI Agent 共享同一种记忆格式。
这件事听起来不性感,但在场的开发者一看就懂——这是冲着 Agent 生态最难啃的那块骨头去的。过去一年,Agent 产品爆发,但每家的记忆系统都是孤岛:ChatGPT 的 Memory 锁在 OpenAI 后台,Claude 的 Projects 上下文是 Anthropic 私有格式,Cursor 记得你写过的代码风格,Notion AI 记得你的写作偏好,但这些数据互不相通。换个工具,等于换一个失忆症患者重新认识你。
UMP 想干的就是这件事——定义一份跨厂商、跨 Agent 的标准记忆 schema,让你在 A 工具积累的记忆,能一键迁移到 B 工具。
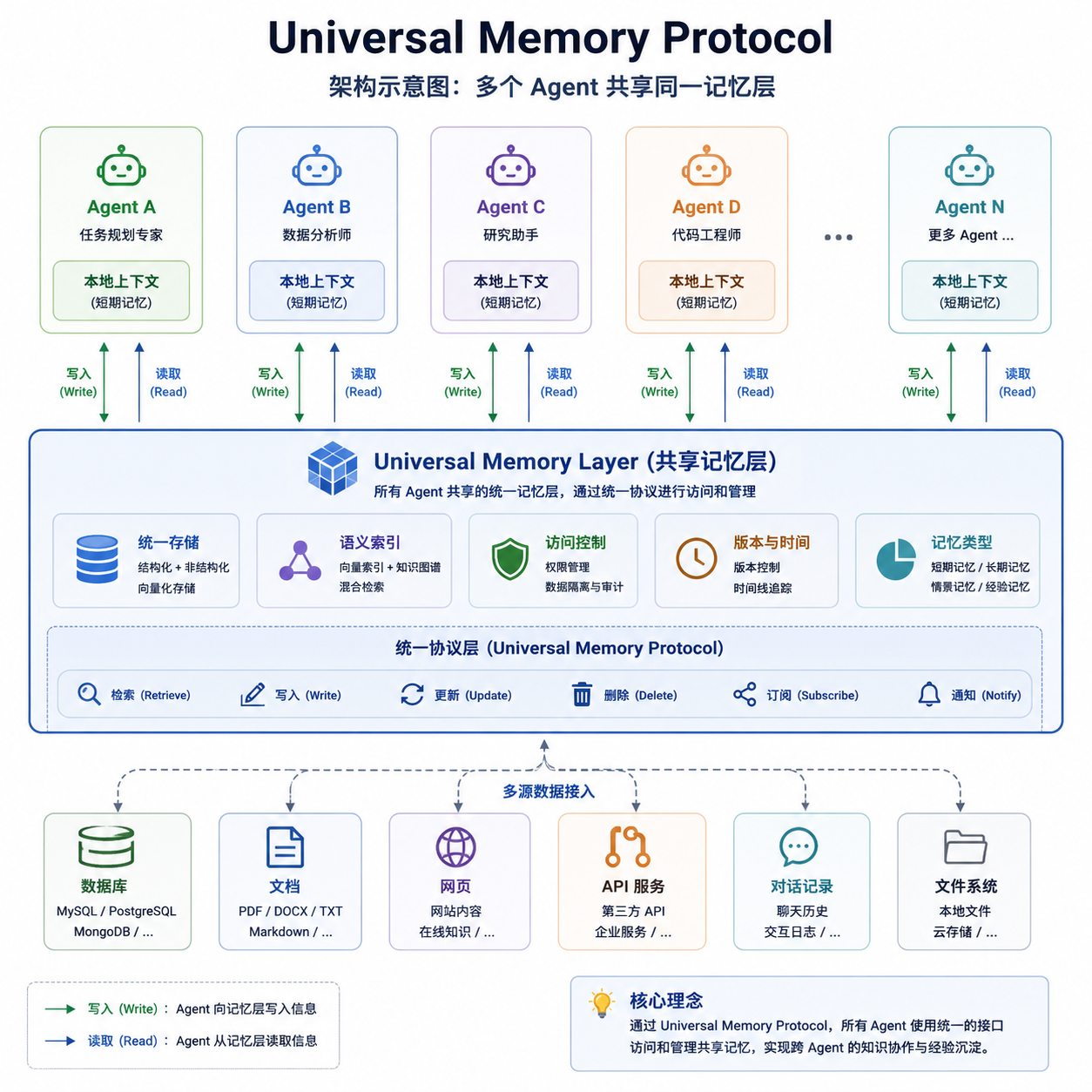
它到底定义了什么
翻完文档,UMP 的设计思路其实比想象中克制。它没有去发明一套全新的记忆存储引擎,而是聚焦在数据交换格式这一层——这点和当年 MCP(Model Context Protocol)的思路如出一辙:协议先行,实现各管各的。
核心定义包含三个层级:
- Atomic Memory(原子记忆):最小记忆单元,类似一条结构化的事实陈述。比如「用户偏好用 TypeScript 而非 JavaScript」「用户所在时区是 UTC+8」。每条记忆带有时间戳、置信度、来源 Agent 标识和过期策略。
- Episodic Memory(情景记忆):一段完整交互的摘要,保留时间线和因果关系。比如「6 月 2 日用户调试了一个 React hydration 错误,最终通过 suppressHydrationWarning 解决」。
- Semantic Memory(语义记忆):从大量原子记忆中抽象出来的稳定偏好和知识图谱节点,类似用户画像,但是结构化、可解释的。
这套分层很眼熟——稍微熟悉认知科学的人会看出来,它直接借鉴了人类记忆系统中 Tulving 那套经典分类。但更值得关注的,是它对记忆所有权的处理。
UMP 规定,所有记忆数据归用户所有,存储在用户指定的位置(本地、自建 S3、或任何兼容的对象存储),Agent 只能在获得授权后读取。这套权限模型有点像 OAuth:用户登录一个新 Agent,Agent 申请访问哪些 scope 的记忆(比如「编程偏好」「日历偏好」),用户授权后才能读。
这是 UMP 最大的产品判断——它赌的是开发者和用户都受够了被各家 Agent 厂商绑架数据。
一个标准格式示例
协议本身定义在 JSON Schema 之上,单条原子记忆大致长这样:
{
"id": "mem_01HXYZ...",
"type": "atomic",
"subject": "user",
"predicate": "prefers_language",
"object": "TypeScript",
"context": {
"domain": "programming",
"tags": ["frontend", "language_preference"]
},
"provenance": {
"source_agent": "cursor-ide",
"created_at": "2026-06-04T10:23:11Z",
"confidence": 0.92
},
"access": {
"scope": "programming.preferences",
"ttl": null
}
}
用 SPO(Subject-Predicate-Object)三元组承载事实,是知识图谱里很标准的做法,好处是天然可查询、可推理,缺点是表达力不够强。UMP 用 context 字段给三元组打补丁,允许附加非结构化元数据。这种折中比较务实——既保留了结构化查询的能力,又不至于让 Agent 在写入时被 schema 卡死。
为什么是现在
这事如果发生在两年前,没人在意。但 2026 年的语境完全不同了。
第一,Agent 已经从「单次对话工具」长出了「持续陪伴的数字助理」形态。GPT、Claude、Gemini 全都在做长期记忆,连国内厂商也跟得很紧——4 月份腾讯云发布的「龙虾」TencentDB Agent Memory,把记忆做成数据库插件,宣称在 PersonaMem 评测集上能把准确率从 48% 拉到 76%。各家都在卷记忆,但卷的方向是性能,不是互通。
第二,MCP 在 2025 年的成功证明了一件事——AI 生态确实需要协议层,且开发者愿意为协议买单。Anthropic 推 MCP 时也没人看好,结果一年下来主流 Agent 框架几乎都接了。UMP 显然是在复制这条路径:先把规范铺出来,让早期采用者尝甜头,等生态起来后形成事实标准。
第三,监管在变。欧盟 AI Act 已经开始要求高风险 AI 系统提供数据可携带性,记忆数据迟早会被纳入个人数据范畴。UMP 这种「用户拥有、Agent 借用」的模型,刚好踩在合规的甜区上。
跟现有方案比,UMP 强在哪、弱在哪
说实话,记忆这件事已经有不少人在做了,UMP 不是第一个。
LangMem、Mem0、Zep 这些项目都提供了 Agent 记忆能力,但它们都是实现而非协议——你用 Mem0,记忆数据就锁在 Mem0 的存储里;你用 Zep,就被绑在 Zep 的 API 上。换框架等于丢历史。
腾讯云的 Agent Memory 走得更彻底,直接做成数据库服务,性能强,企业级支持好,但封闭程度也最高——出了腾讯云生态就没法用。
UMP 选择了一条更难、但天花板更高的路:不做存储、不做检索、不做嵌入,只定义数据应该长什么样。理论上,Mem0 可以在内部把存储格式改成 UMP,Zep 也可以加一个 UMP 导入/导出,互不冲突。
这种「只定义协议」的路线弱点也明显:
- 采纳门槛取决于先行者:如果 OpenAI、Anthropic 这种巨头不接,协议就只能在开源圈子里转。
- 检索语义不统一:协议定义了记忆怎么存,但没定义 Agent 怎么查、怎么排序、怎么决定遗忘。两个都支持 UMP 的 Agent,行为可能完全不同。
- 隐私边界模糊:用户授权了「编程偏好」scope,但 Agent 在写入新记忆时,怎么判断这条该不该打上这个 scope?协议交给实现方处理,这是个隐患。
开发者该怎么看
如果你正在做 Agent,UMP 现阶段值得「读一遍文档、跑一下示例、暂不集成」。原因是协议还在 v0.1,schema 大概率会变,现在押注成本不低。
但有几个信号值得盯:
- 是否有头部 Agent 接入。如果半年内 Cursor、Cline、Claude Code 这类开发者高频使用的工具里有人率先支持,UMP 就有戏。
- 是否出现合规适配器。比如能不能把 ChatGPT 的 Memory 导出转成 UMP 格式?这是用户最直接的痛点。
- 检索层标准是否跟上。光有数据格式不够,得有配套的查询语义。这一块文档里写了 RFC 草案,还没落地。
对于做应用层的开发者,更现实的建议是:在自己的 Agent 里先用 UMP 的 schema 设计内部记忆结构。哪怕协议本身没火,这套结构化方法论用起来也不亏——至少调试时能看清 Agent 到底记住了什么、为什么记错了。
顺便提一句,国内开发者如果想同时测试 GPT、Claude、Gemini 在记忆任务上的表现差异,OpenAI Hub 现在一个 Key 就能调齐这几家主流模型,省得为了对比实验注册一堆账号、折腾各种代理。
协议会不会成,还要看生态
UMP 的处境其实挺像 2024 年初的 MCP——好的协议设计,开源、克制、踩在真痛点上,但能不能跑出来完全取决于生态势能。
乐观地看,Agent 互操作性已经是个绕不开的问题,早晚有协议把它解决,UMP 起步早、设计干净,占位优势明显。悲观地看,巨头有动力推自己的封闭记忆方案,毕竟用户记忆数据等于护城河,主动开放等于自废武功。
这事最终的走向,可能要看一个朴素的问题:用户到底有多在意自己的记忆能不能带走。如果在意,UMP 就有机会;如果大多数用户根本懒得换工具,那协议就只是协议。
开发者社区已经开始讨论,github 上的 Issue 区第一天就有人提议加入向量嵌入字段、记忆冲突解决策略、跨语言绑定等等。从讨论热度看,至少这一拨人是真在意的。
参考来源
- Hacker News - Universal Memory Protocol 讨论帖(reddit 同步讨论) - 开发者社区对 UMP 的早期反应与技术细节讨论
- LangMem 与 Agent 记忆框架对比(知乎专栏) - 国内开发者视角下的 Agent 记忆方案横向比较
- MCP 与新一代 Agent 协议层综述(掘金) - 协议层为何在 2025-2026 成为 AI 基础设施关键的分析