GLM-5.1:能连续干8小时的开源模型来了

智谱今日发布开源旗舰模型 GLM-5.1,主打8小时长程任务能力,SWE-bench Pro 成绩超越 Claude Opus 4.6 和 GPT-5.4,同时提价10%,Coding场景价格首次对齐海外头部厂商。
智谱今天正式发布了 GLM-5.1。一句话概括:这是一个能连续工作 8 小时、在 SWE-bench Pro 上干翻 Claude Opus 4.6 的开源模型。
同一天,智谱股价盘中大涨近 19%,GLM 系列 API 再度提价 10%。国产大模型终于走到了一个微妙的拐点——不再卷低价,开始卷价值。
先说最硬的数据
直接看成绩单。智谱这次拿出了三个业内最有代表性的代码评测基准:
- SWE-Bench Pro:在真实 GitHub 仓库中定位并修复高难度工程 Bug,公认最接近真实软件开发的基准测试。GLM-5.1 刷新全球最佳成绩,超过 GPT-5.4 和 Claude Opus 4.6。
- Terminal-Bench 2.0:考察模型操作命令行解决问题的能力。
- NL2Repo:从零构建完整代码仓库。
三项综合下来,GLM-5.1 拿到全球第三、国产第一、开源第一。
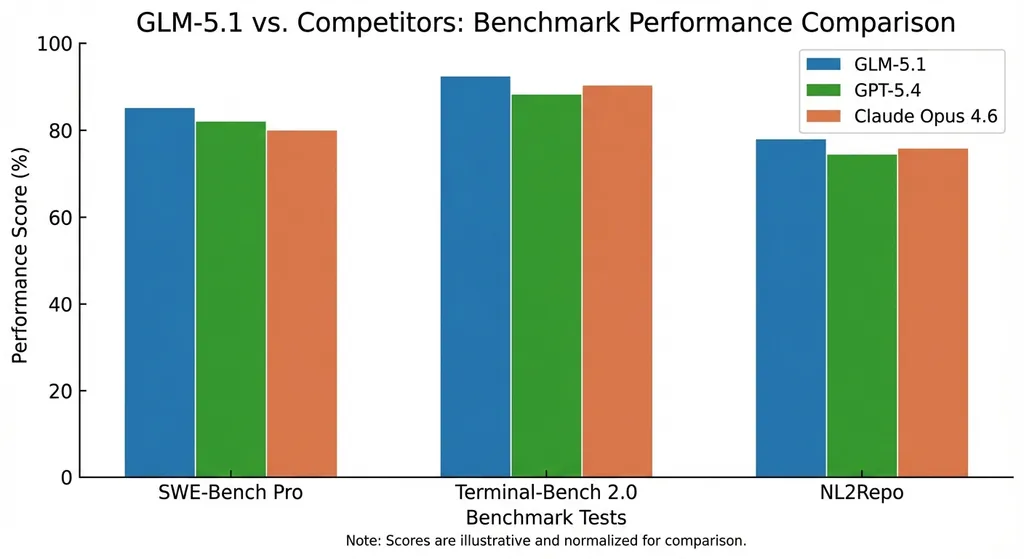
这里要多说一句 SWE-Bench Pro。这个基准之所以被行业认可,是因为它不是那种"给你一段代码补全下一行"的玩具测试。它要求模型理解一个真实的、有历史包袱的 GitHub 项目,在成千上万行代码里定位 Bug,然后写出能通过 CI 的修复补丁。能在这个测试上拿高分,基本等于说:这个模型可以当一个靠谱的 junior engineer 用了。
GLM-5.1 在这项测试上超越 Opus 4.6,是国产模型的第一次。考虑到 Opus 4.6 长期占据编程能力的王座,这个突破的含金量不低。
8 小时长程任务:从"能不能做"到"能做多久"
但比跑分更值得关注的,是 GLM-5.1 提出的一个新叙事:Long-Horizon Task(长程任务)。
过去两年,大模型的竞争逻辑是"谁更聪明"——Benchmark 分数越高越好。智谱这次试图把评价维度从"智力"拉到"耐力":模型不只要聪明,还要能持续工作。
这个思路其实很实际。你让现在的顶级模型写一个函数、改一个 Bug,它们都能做得不错。但如果你给它一个真实的工程任务——比如"把这个 Python 2 项目迁移到 Python 3,顺便把测试覆盖率从 40% 提到 80%"——大多数模型在 30 分钟内就会开始"走神":上下文丢失、目标偏移、重复犯错。
智谱把这个演进路径讲得很清楚:
3 分钟的 Vibe Coding → 30 分钟的 Agentic Engineering → 8 小时的 Long-Horizon Task
从氛围编程到智能体工程,再到长程任务。每一步跨越的不只是时间长度,而是模型在自主规划、执行、纠错方面的能力门槛。
8 小时意味着什么?意味着你晚上睡觉前给模型派一个任务,早上起来它交付了一个完整的工程级成果。智谱官方的说法是:"你睡觉的 8 小时,是模型上班的 8 小时。"
这话听着像营销口号,但背后的技术挑战是真实的。要让一个模型在 8 小时内保持稳定输出,至少需要解决几个核心问题:
- 超长上下文的记忆管理:8 小时的工作会产生海量的中间状态,模型需要知道哪些信息该记住、哪些可以丢弃。
- 目标保持与自我纠错:时间越长,模型越容易偏离最初的目标。它需要有能力定期"回头看",确认自己还在正确的方向上。
- 多步骤规划与执行:不是一次性生成答案,而是把大任务拆成子任务,按顺序执行,每一步的输出作为下一步的输入。
- 失败恢复:8 小时里一定会遇到错误。模型不能因为一个报错就卡死,它需要能诊断问题、调整策略、继续推进。
目前行业里,能做到分钟级 Agentic 任务的模型不少,但声称能稳定运行 8 小时的,GLM-5.1 是开源阵营里的第一个。当然,"8 小时"这个数字在实际场景中的表现如何,还需要更多开发者的实测验证。
提价 10%:国产模型的定价逻辑变了
伴随 GLM-5.1 发布,智谱同步提价 10%。
这在国产大模型圈子里是个反常操作。过去一年半,国内厂商的主旋律是降价——你降 50%,我直接免费。价格战打到最后,不少模型的 API 价格已经低到让人怀疑是不是在亏本获客。
智谱反其道而行,而且不是第一次了。从 GLM-5 到 GLM-5.1,这已经是又一轮提价。
提价后的结果很有意思:GLM-5.1 在 Coding 场景的缓存命中 Token 价格,已经接近 Anthropic 旗下 Claude Sonnet 4.6 的水平。这是国产大模型首次在核心场景实现与海外头部厂商的价格对齐。
36氪报道显示,市场对此的反应是正面的——智谱今日盘中大涨近 19%。投资者的逻辑很简单:能提价说明产品有议价能力,有议价能力说明用户真的在用、真的觉得值。
对开发者来说,这意味着什么?
如果你之前选 GLM 系列纯粹是因为便宜,那现在需要重新评估了。但如果你选它是因为能力够用、开源可控,那提价 10% 换来的 SWE-bench Pro 全球第一和 8 小时长程任务能力,这笔账算得过来。
开源的意义:不只是能下载权重
GLM-5.1 是开源模型,这一点值得单独拿出来说。
在 SWE-bench Pro 上超越 Opus 4.6 的模型,之前都是闭源的。GLM-5.1 是第一个以开源身份做到这件事的。
开源对开发者的实际价值在于:
- 私有化部署:对数据安全有要求的企业可以把模型跑在自己的机房里,代码不出内网。
- 微调定制:可以在特定领域的数据上做 fine-tuning,让模型更懂你的业务。
- 成本可控:大规模调用时,自建推理服务的边际成本远低于 API 调用。
- 不受供应商锁定:不用担心某天 API 涨价或者停服。
当然,开源模型的部署和运维成本也不低。对于大多数开发者来说,通过 API 调用仍然是最高效的方式。好消息是,GLM-5.1 已经可以通过多个平台的 API 直接调用,OpenAI Hub 也已支持,兼容 OpenAI 格式,切换成本几乎为零。
实际调用:怎么用上 GLM-5.1
对于已经在用 OpenAI 格式 API 的开发者,接入 GLM-5.1 非常简单。以下是一个通过 OpenAI Hub 调用的示例:
from openai import OpenAI
client = OpenAI(
api_key="your-openai-hub-key",
base_url="https://api.openai-hub.com/v1"
)
response = client.chat.completions.create(
model="glm-5.1",
messages=[
{
"role": "system",
"content": "你是一个资深软件工程师,擅长定位和修复复杂代码库中的 Bug。"
},
{
"role": "user",
"content": "以下是一个 Python 项目的报错日志和相关代码文件,请帮我定位问题根因并给出修复方案。\n\n报错日志:\nTraceback (most recent call last):\n File 'app/services/auth.py', line 47, in validate_token\n payload = jwt.decode(token, SECRET_KEY, algorithms=['HS256'])\njwt.exceptions.ExpiredSignatureError: Signature has expired\n\n相关代码见附件。"
}
],
temperature=0.2,
max_tokens=4096
)
print(response.choices[0].message.content)
如果你想体验 GLM-5.1 的长程任务能力,更典型的用法是结合 Agent 框架,让模型在循环中持续工作:
from openai import OpenAI
import json
client = OpenAI(
api_key="your-openai-hub-key",
base_url="https://api.openai-hub.com/v1"
)
def run_long_horizon_task(task_description: str, max_iterations: int = 100):
"""简化的长程任务执行循环"""
messages = [
{
"role": "system",
"content": (
"你是一个能够独立完成复杂工程任务的 AI 工程师。"
"请先制定计划,然后逐步执行。每一步完成后,评估进度并决定下一步行动。"
"如果遇到错误,请自行诊断并修复。"
)
},
{"role": "user", "content": task_description}
]
for i in range(max_iterations):
response = client.chat.completions.create(
model="glm-5.1",
messages=messages,
temperature=0.3,
max_tokens=8192
)
assistant_msg = response.choices[0].message.content
messages.append({"role": "assistant", "content": assistant_msg})
# 检查模型是否认为任务已完成
if "[TASK_COMPLETE]" in assistant_msg:
print(f"任务在第 {i+1} 轮迭代后完成")
break
# 执行模型输出的操作,将结果反馈给模型
result = execute_action(assistant_msg) # 你的执行逻辑
messages.append({"role": "user", "content": f"执行结果:\n{result}"})
return messages
这只是一个简化示例。实际的长程任务框架会更复杂,涉及工具调用、文件系统操作、Git 操作等。但核心思路是一样的:让模型在循环中持续规划和执行,直到任务完成。
和竞品比,GLM-5.1 处在什么位置?
拉一张表来看当前第一梯队的编程模型格局:
| 模型 | SWE-Bench Pro | 长程任务 | 开源 | 备注 | |------|:---:|:---:|:---:|------| | GLM-5.1 | 🥇 全球最佳 | 8 小时 | ✅ | 国产第一、开源第一 | | Claude Opus 4.6 | 🥈 | 未公开 | ❌ | 长期编程王者 | | GPT-5.4 | 🥉 | 未公开 | ❌ | OpenAI 最新旗舰 | | Gemini 3 Pro | 第二梯队 | 未公开 | ❌ | Google 旗舰 |
需要注意的是,SWE-Bench Pro 的成绩会受到 Agent 框架、提示词工程等因素的影响,不同评测条件下的结果可能有差异。智谱公布的是官方评测成绩,社区独立复现的结果可能会有波动。
从开发者实测反馈来看,知乎上已经有不少第一手体验报告。总体评价是:编程能力确实有质的飞跃,在特定场景下已经可以作为 Claude Opus 4.6 的平替。但在一些复杂的多文件重构任务上,稳定性还有提升空间。
另外一个值得关注的细节是,GLM-5.1 是基于华为芯片训练的。在当前的国际环境下,这意味着整个技术栈——从训练芯片到模型权重——都实现了自主可控。对于有合规要求的政企客户来说,这是一个重要的加分项。
行业影响:开源模型的天花板被抬高了
回看过去一年,开源模型的进化速度超出了大多数人的预期。
从 Llama 3 到 DeepSeek-V3,再到现在的 GLM-5.1,开源模型和闭源模型之间的差距在快速缩小。GLM-5.1 在 SWE-bench Pro 上超越 Opus 4.6,某种程度上标志着:在编程这个最硬核的能力维度上,开源已经追平甚至超越了闭源。
这对整个行业的影响是深远的:
对开发者:选择更多了。以前想要顶级编程能力,只能用 Claude 或 GPT 的 API,现在多了一个开源选项。可以 API 调用,也可以私有化部署。
对企业:大模型的采购决策变得更复杂了。不再是"闭源=强,开源=弱"的简单二分法。需要根据具体场景、数据安全要求、成本预算来综合评估。
对 Anthropic 和 OpenAI:护城河在收窄。当开源模型在核心能力上追平,闭源厂商的优势将更多体现在生态、工具链和企业服务上,而不仅仅是模型能力本身。
冷静看几个问题
当然,也不必过度兴奋。几个需要冷静看待的点:
-
Benchmark 不等于实际体验。SWE-bench Pro 成绩全球第一,不代表在所有编程场景下都是最强的。实际开发中的体验受太多因素影响——响应速度、上下文窗口利用效率、对特定语言和框架的熟悉程度等等。
-
8 小时长程任务的实际表现有待验证。官方声称能持续工作 8 小时,但在什么样的任务上?成功率如何?中间会不会出现质量衰减?这些都需要社区大规模实测后才能下结论。
-
提价是双刃剑。价格对齐海外厂商,说明智谱对产品有信心,但也意味着"性价比"这张牌不能再打了。GLM-5.1 必须在能力上真正站住脚,否则用户会用脚投票。
-
Coding Plan 瞬间断货的现象说明产能还是个问题。知乎上有用户反映 GLM-5.1 上线后 Coding Plan 迅速售罄,这对想要第一时间体验的开发者来说不太友好。
写在最后
GLM-5.1 的发布,让 2026 年的大模型竞争变得更有意思了。
一个国产开源模型,用华为芯片训练,在最硬核的编程基准上超越了 Claude 和 GPT,还能连续工作 8 小时。放在两年前,这是不可想象的。
但竞争远没有结束。Anthropic 的 Claude 5 系列、OpenAI 的下一代模型都在路上。开源阵营里,DeepSeek、Llama 也不会坐视不理。
对开发者来说,最好的策略永远是:保持关注,快速试用,用实际项目验证,而不是只看跑分。GLM-5.1 值得你花一个下午去认真测一测。
参考来源
- 智谱发布可持续工作 8 小时的旗舰模型 GLM-5.1,同时提价 10% — IT之家对 GLM-5.1 发布的详细报道,含官方完整介绍
- GLM 再度提价 10%,智谱大涨近 19% — 36氪关于智谱提价及股价表现的快讯
- GLM-5.1 上线,编程表现贴 Opus 4.6,Coding Plan 瞬间断货 — 知乎上关于 GLM-5.1 上线首日的开发者反馈
- 太强了!GLM-5.1 第一手实测,平替 Claude Opus 4.6? — 知乎专栏的 GLM-5.1 实测体验报告
