GitHub Rubber Duck:让Claude和GPT互相审代码

GitHub Copilot CLI 推出实验性功能 Rubber Duck,引入跨模型交叉审查机制,用 Claude 写代码、GPT 来审查,在 SWE-Bench Pro 上弥补了 74.7% 的性能差距。
GitHub 在 4 月 6 日干了一件挺有意思的事:给 Copilot CLI 加了个叫 Rubber Duck 的实验功能,核心思路是——让不同家族的 AI 模型互相审查代码。
简单说,你用 Claude Sonnet 4.6 写代码,写完之后 GPT-5.4 来帮你 review。不是同一个模型自己检查自己,而是跨家族的「第二意见」。
这个思路其实不新鲜。微软在 3 月底刚给 Microsoft 365 Copilot 的 Researcher 上线了类似的多模协作功能 Critique,让 GPT 和 Claude 在研究任务中协同工作。但 Rubber Duck 把这套逻辑搬到了代码生成场景,解决的问题更具体,效果也更容易量化。
单模型自审的天花板
先说为什么需要这个东西。
现在的编程智能体有个老问题:在代码规划阶段犯的错,会像滚雪球一样越滚越大。你让一个模型先规划、再实现、最后自己检查,听起来很合理,但问题在于——模型的训练偏差和盲点是系统性的。
打个比方,一个人写完文章自己校对,总会漏掉一些错误,因为你的思维惯性会让你「看到」你以为自己写的东西,而不是实际写的东西。模型也一样。Claude 在规划阶段如果做了一个有问题的架构假设,它在后续的自我审查中大概率不会质疑这个假设,因为这个假设本身就来自它的「思维方式」。
这不是能力问题,是结构性问题。
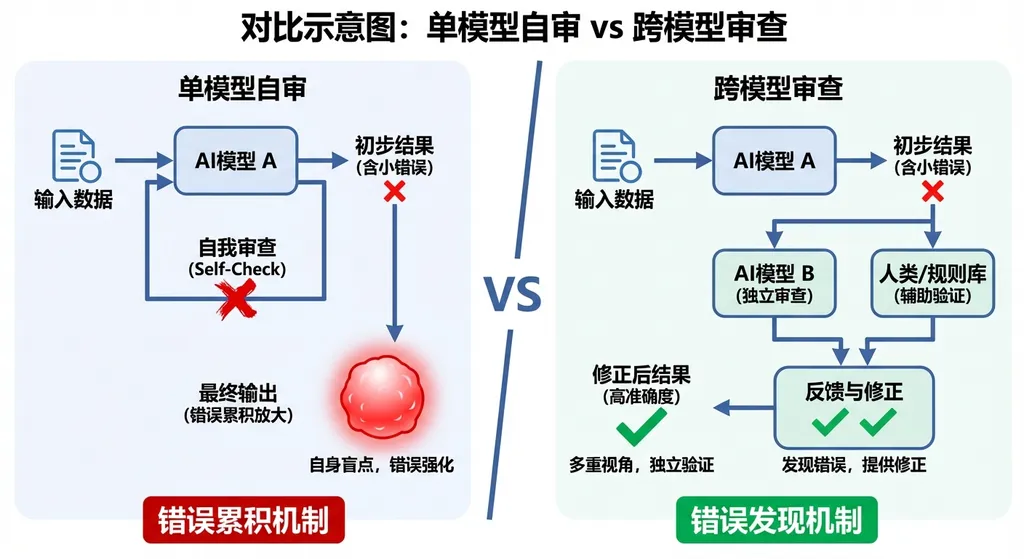
Rubber Duck 怎么工作
Rubber Duck 的名字来自经典的「橡皮鸭调试法」——程序员对着一只橡皮鸭解释代码逻辑,往往能自己发现 bug。只不过这次,橡皮鸭换成了另一个 AI 模型,而且它真的会回嘴。
具体机制是这样的:
- 用户选择 Claude 系列模型作为主控智能体,负责代码规划和实现
- Rubber Duck 在关键节点自动调用 GPT-5.4 作为独立审查者
- GPT-5.4 的任务不是重写代码,而是输出一份「高价值关注点清单」
这份清单包含三类内容:被遗漏的细节、值得质疑的假设、以及没有覆盖到的边缘案例。
审查会在三个关键检查点自动触发:
- 制定计划后——审查架构决策和技术选型是否合理
- 复杂实现后——检查实现逻辑是否存在漏洞
- 测试编写后——评估测试覆盖率和边界条件
除了主动触发,系统还有被动模式:当智能体陷入循环(比如反复修改同一段代码但测试始终不过)时,Rubber Duck 会自动介入。用户也可以随时手动请求审查。
这里有个设计细节值得注意:所有审查反馈和修改依据都会展示给用户。这不是黑箱操作,你能看到 GPT-5.4 提了什么意见,Claude 采纳了哪些、拒绝了哪些,以及为什么。
74.7% 这个数字怎么来的
说实话,看到「性能提升接近 75%」这种表述,第一反应是怀疑。但仔细看数据,GitHub 的说法其实比较克制。
他们用的基准是 SWE-Bench Pro,这是目前评估编程智能体比较主流的 benchmark。测试逻辑是这样的:
- 先跑 Claude Sonnet 4.6 单独的成绩,作为基线
- 再跑 Claude Opus 4.6 单独的成绩,作为天花板
- 然后看 Sonnet 4.6 + Rubber Duck(GPT-5.4 审查)能弥补多少差距
结果是弥补了 74.7% 的性能差距。注意,不是说性能提升了 74.7%,而是说 Sonnet 加上跨模型审查后,接近了 Opus 单独跑的水平。
这个表述方式很聪明,也很诚实。它承认了一个事实:用便宜模型 + 审查机制,可以逼近贵模型的效果,但还是有差距。
更有意思的是在困难任务上的表现。在涉及 3 个以上文件修改或超过 70 步操作的任务中,Rubber Duck 的得分比基线高出 3.8%。这个数字看起来不大,但在困难任务上,每一个百分点的提升都意味着实际可用性的显著改善。
实际案例中,Rubber Duck 能有效发现的问题包括:
- 架构逻辑漏洞(比如模块间的循环依赖)
- 循环覆盖错误(比如 for 循环的边界条件没处理好)
- 跨文件冲突(比如两个文件对同一个接口的理解不一致)
这些都是单模型自审最容易漏掉的问题,因为它们需要「换一个角度」才能看到。
跟微软自家的 Critique 比呢?
前面提到,微软在 3 月底给 Microsoft 365 Copilot 推出了 Critique 和 Council 功能,也是让 GPT 和 Claude 协同工作。但两者的定位和架构有明显区别。
Critique 面向的是研究场景:GPT 撰写初稿,Claude 按学术标准核查事实和逻辑,未来还会支持双向互审。它采用的是并行对比架构——两个模型独立生成报告,然后由一个「裁判模型」评估两份产出,提炼共识和分歧。
Rubber Duck 面向的是代码生成场景:一个模型主控,另一个模型审查。不是并行工作,而是串行的「写-审」流程。这种设计更适合编程任务,因为代码生成本身是有序的——你得先有计划,再有实现,最后有测试。
从更大的视角看,微软在短短两周内连续推出两个跨模型协作功能,释放的信号很明确:单一模型的时代正在过去,未来的 AI 产品会越来越多地采用多模型编排架构。
这对开发者来说意味着什么?你的工具链需要能灵活调用不同的模型。今天是 Claude + GPT,明天可能是 Gemini + DeepSeek。如果你的基础设施只绑定了一个模型供应商,切换成本会很高。像 OpenAI Hub 这样的聚合平台在这种趋势下就比较实用——一个 API 端点切换不同模型,不用为每个供应商单独维护接入逻辑。
开发者怎么用
目前 Rubber Duck 还是实验性功能,启用方式:
- 安装最新版 GitHub Copilot CLI
- 运行
/experimental命令启用实验功能 - 选择 Claude 模型作为主控智能体
- 确保已开通 GPT-5.4 的访问权限
启用后,Rubber Duck 会在上述三个检查点自动工作,不需要额外配置。
如果你想在自己的项目中实现类似的跨模型审查逻辑,思路其实不复杂。核心就是:用一个模型生成,用另一个模型审查,然后把审查结果反馈给第一个模型。
下面是一个基于 OpenAI Hub 兼容格式的简单示例,展示如何用 Claude 生成代码方案、再用 GPT 审查:
import openai
# 通过 OpenAI Hub 统一调用不同模型
client = openai.OpenAI(
base_url="https://api.openai-hub.com/v1",
api_key="your-openai-hub-key"
)
def generate_plan(task: str) -> str:
"""用 Claude 生成代码方案"""
resp = client.chat.completions.create(
model="claude-sonnet-4.6",
messages=[
{"role": "system", "content": "你是一个资深软件工程师,请为以下任务制定详细的实现方案。"},
{"role": "user", "content": task}
]
)
return resp.choices[0].message.content
def rubber_duck_review(plan: str, task: str) -> str:
"""用 GPT 审查方案,输出关注点清单"""
resp = client.chat.completions.create(
model="gpt-5.4",
messages=[
{"role": "system", "content": """你是一个独立的代码审查者。
请审查以下代码方案,输出高价值关注点清单,包括:
1. 被遗漏的细节
2. 值得质疑的假设
3. 未覆盖的边缘案例
不要重写方案,只提供审查意见。"""},
{"role": "user", "content": f"任务描述:{task}\n\n当前方案:\n{plan}"}
]
)
return resp.choices[0].message.content
def refine_plan(plan: str, review: str, task: str) -> str:
"""Claude 根据审查意见修订方案"""
resp = client.chat.completions.create(
model="claude-sonnet-4.6",
messages=[
{"role": "system", "content": "请根据审查意见修订你的方案。对每条意见说明采纳或拒绝的理由。"},
{"role": "user", "content": f"原始任务:{task}\n\n你的方案:\n{plan}\n\n审查意见:\n{review}"}
]
)
return resp.choices[0].message.content
# 使用示例
task = "实现一个支持并发的 LRU 缓存,要求线程安全且支持 TTL 过期"
plan = generate_plan(task)
print("=== 初始方案 ===")
print(plan)
review = rubber_duck_review(plan, task)
print("\n=== Rubber Duck 审查 ===")
print(review)
final_plan = refine_plan(plan, review, task)
print("\n=== 修订后方案 ===")
print(final_plan)
这段代码的关键在于:通过同一个 API 端点(OpenAI Hub)无缝切换 Claude 和 GPT,不需要维护两套 SDK 或两个认证体系。模型名称换一下就行。
这事儿的意义在哪
往大了说,Rubber Duck 代表的是一种范式转变:从「更大的模型」到「更聪明的编排」。
过去两年,AI 行业的主旋律是模型军备竞赛——参数更多、上下文更长、benchmark 分数更高。但 Rubber Duck 的数据说明了一个事实:一个中等模型加上好的审查机制,可以逼近顶级模型的效果。
Sonnet 4.6 的价格大约是 Opus 4.6 的五分之一。如果 Rubber Duck 能弥补 74.7% 的性能差距,那算上审查调用的额外成本,总成本可能只有直接用 Opus 的三分之一到二分之一。对于大规模使用编程智能体的团队来说,这是实打实的成本优化。
往小了说,这个功能解决了一个很实际的痛点:AI 生成的代码你不敢直接用,但人工 review 又太慢。让另一个 AI 来做第一轮审查,至少能过滤掉一批结构性问题,人类 reviewer 可以把精力放在更高层次的架构判断上。
当然,也有值得观察的地方。跨模型审查意味着额外的 API 调用和延迟。在需要快速迭代的场景下,每次都等 GPT-5.4 审查一遍,开发者的耐心够不够?三个自动检查点的设置是否合理?这些都需要实际使用中验证。
另外,目前 Rubber Duck 只支持 Claude 主控 + GPT 审查这一种组合。未来会不会支持反过来?或者引入 Gemini、DeepSeek 等更多模型?GitHub 的博文没有提,但从微软同时在 M365 Copilot 上推 Critique 的动作来看,多模型编排一定是长期方向。
写在最后
「橡皮鸭调试法」之所以有效,不是因为橡皮鸭有多聪明,而是因为向别人解释的过程迫使你重新审视自己的假设。Rubber Duck 把这个逻辑自动化了,而且「别人」不再是一只沉默的橡皮鸭,而是一个有不同知识结构和推理偏好的 AI 模型。
这可能是 2026 年 AI 编程工具最值得关注的趋势之一:不是单个模型变得多强,而是不同模型之间的协作方式变得多巧。
参考来源:
- 微软 GitHub 推出跨模型 AI 审查:Claude Sonnet 4.6 搭配 GPT-5.4,弥补 74.7% 性能差距 — IT之家对 GitHub Rubber Duck 功能的详细报道
