谷歌祭出 DiffusionGemma:扩散模型杀进文本生成,本地推理快 4 倍

谷歌 DeepMind 本周开源 DiffusionGemma,把图像扩散模型的并行去噪思路搬到了文本上。260 亿参数 MoE 架构,H100 单卡破千 token/秒,但谷歌自己也承认:这是一款"为速度刻意妥协质量"的实验性模型。
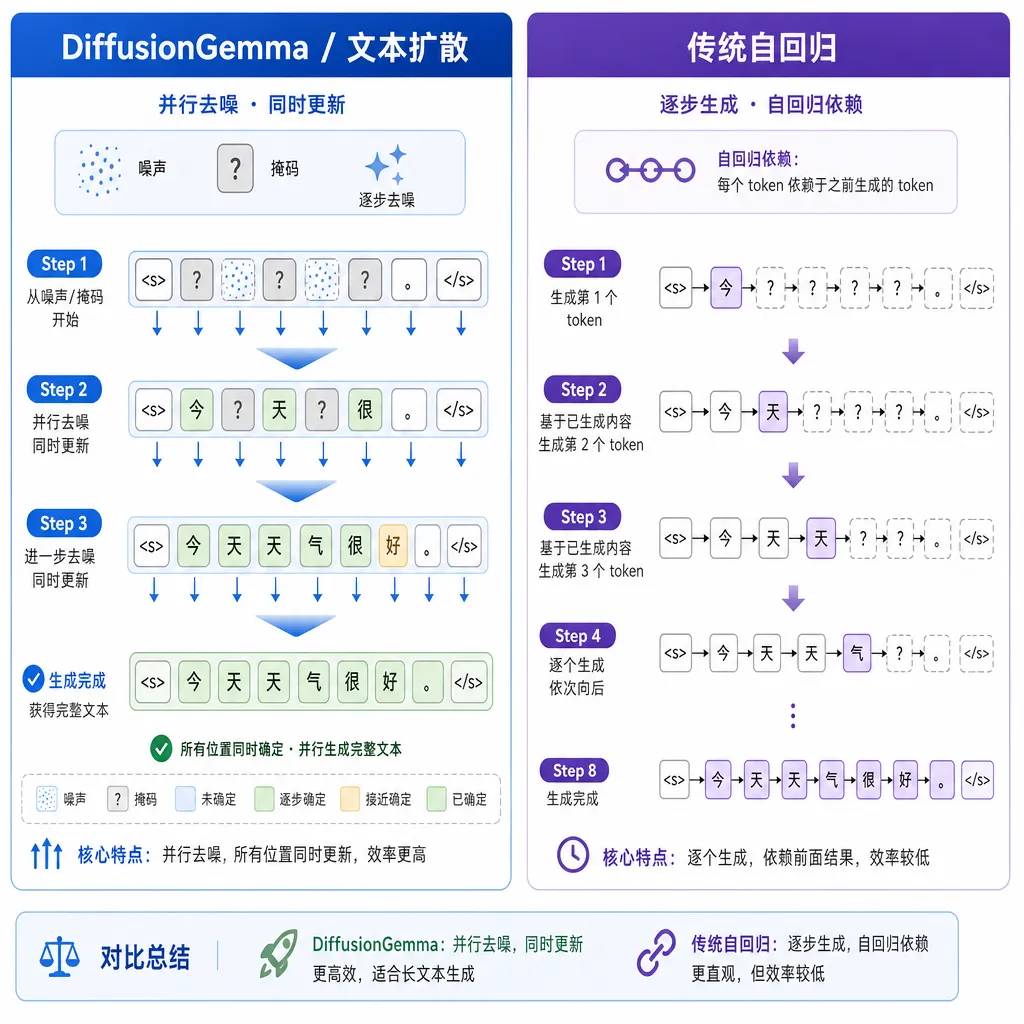
6 月 11 日,谷歌 DeepMind 把 DiffusionGemma 扔进了 Gemma 家族——这是一款不走自回归路线的开放权重文本模型,借的是图像扩散的思路:先在"画布"上铺 256 个占位符,再多轮迭代去噪,让文字一块块浮现出来。
官方给的数据很扎眼:单张 H100 突破 1000 token/秒,RTX 5090 也能跑到 700+ token/秒,DGX Station 上甚至能到 2000 token/秒,约为同尺寸自回归模型的 4 倍。Apache 2.0 协议,权重已经挂在 Hugging Face 上。
但别急着拍手——谷歌在公告里说得很坦白:这是一款"为了把速度推到极限而刻意妥协质量"的实验性模型。换句话说,它不是来取代 Gemma 4 标准版的,是来探路的。
从"打字机"到"印刷机"
要理解这事的意义,得先看清楚自回归模型卡在哪。
GPT、Gemini、Claude 这些主流大模型,本质上都是"打字机"——前一个 token 出来了才能预测下一个,严格按从左到右顺序生成。这种范式在云端跑大 batch 的时候效率不错,多个请求可以拼在一起填满 GPU。但本地场景就尴尬了:单用户、单请求,token 一个一个挤,GPU 大部分时间在等内存带宽,算力根本喂不饱。
这也是为什么消费级显卡跑 LLM,瓶颈往往不是 FLOPs 而是 HBM 带宽。你那张 RTX 5090 算力够用,但 token 还是一个个往外蹦。
DiffusionGemma 走的是另一条路。它一次前向传播并行处理一整块 token(最多 256 个),通过多轮迭代去噪逐步修正。谷歌用了个挺贴切的比喻:自回归是打字机,扩散是印刷机——印刷机一次压一整页。
这种做法有几个直接好处:
- 并行度拉满:Tensor Core 的并行算力终于能吃满了,NVIDIA 在配套博文里特意点了这一点;
- 支持双向注意力:每个 token 生成时能看到段落里所有其他 token,不再是单向"只能往回看";
- 自带纠错:迭代过程中模型可以对已经写出来的内容回头改,而不是错了就将错就错往下写。
第三点尤其有意思。传统自回归一旦走偏,要么硬着头皮编下去(幻觉),要么靠 beam search 之类的事后补救。扩散模型在生成中途就能整段重新评估,理论上对一致性是利好。
26B 参数,跑起来只用 3.8B
架构上 DiffusionGemma 名义参数 260 亿,但每步只激活约 38 亿——典型的 MoE 设计,多个专家子网络并排,模型按需挑几个上场。
这套组合拳的结果是:量化之后,18GB 显存的消费级高端 GPU 就能跑。也就是说,一张 4090(24GB)或者 5090 完全 hold 得住,不用云、不用 8 卡服务器、不用排队。
基准成绩谷歌也放了一些,混合参半:
- 代码:LiveCodeBench 30.9%,BigCodeBench 45.4%,HumanEval 89.6%——和 Gemini 2.0 Flash-Lite 互有胜负;
- 数学:AIME 2025 拿到 23.3%,反而超过了对比模型的 20.0%;
- 科学推理:GPQA Diamond 只有 40.4%,对比模型是 56.5%;
- 复杂推理:BIG-Bench Extra Hard 15.0%,对手 21.0%。
看得出来扩散架构在结构化任务(代码、数学)上挺有潜力,但在需要长链条推理、世界知识检索的任务上还顶不住。这也符合扩散模型的特性——擅长并行修正局部,弱在严格的因果链。
扩散文本不是新故事,但这次有点不一样
说实话,文本扩散这条路被人探了好几年了。Stanford 的 Diffusion-LM、Meta 的一些尝试、字节去年也放过类似研究。它一直没成主流,原因很明确:自然语言比图像更依赖语法顺序、上下文连贯、事实约束。图像里几个像素噪点没人在意,但文字里一个 token 错位整句就废。
DiffusionGemma 让人有点意外的地方在于:它是第一次有大厂用工业级权重把这条路跑通到能用的程度,并且明确给出了"速度优势在哪个区间成立"的边界条件。
谷歌很罕见地把适用场景和不适用场景都列出来了:
适合用:
- 本地、单用户、专属 GPU 的低延迟交互;
- 行内文字编辑、代码补全、需要快速反复试验的工作流;
- 非线性文本生成——比如填中间的代码、生成氨基酸序列、构造数学图形这种需要双向上下文的任务。
不适合用:
- 高 QPS 的云端大规模服务——并行解码的边际效益会快速递减;
- 共享内存架构(比如 Apple Silicon 的 Mac)——自回归本来就不太受带宽限制,扩散加速效果会打折;
- 对文字质量要求极高的正式产品输出——这种场景老老实实用 Gemma 4 标准版。
这段话翻译过来就是:DiffusionGemma 不是普适解,它是给 inline coding assistant、本地 IDE 插件、隐私敏感的桌面应用准备的尖刀。
速度数据怎么看
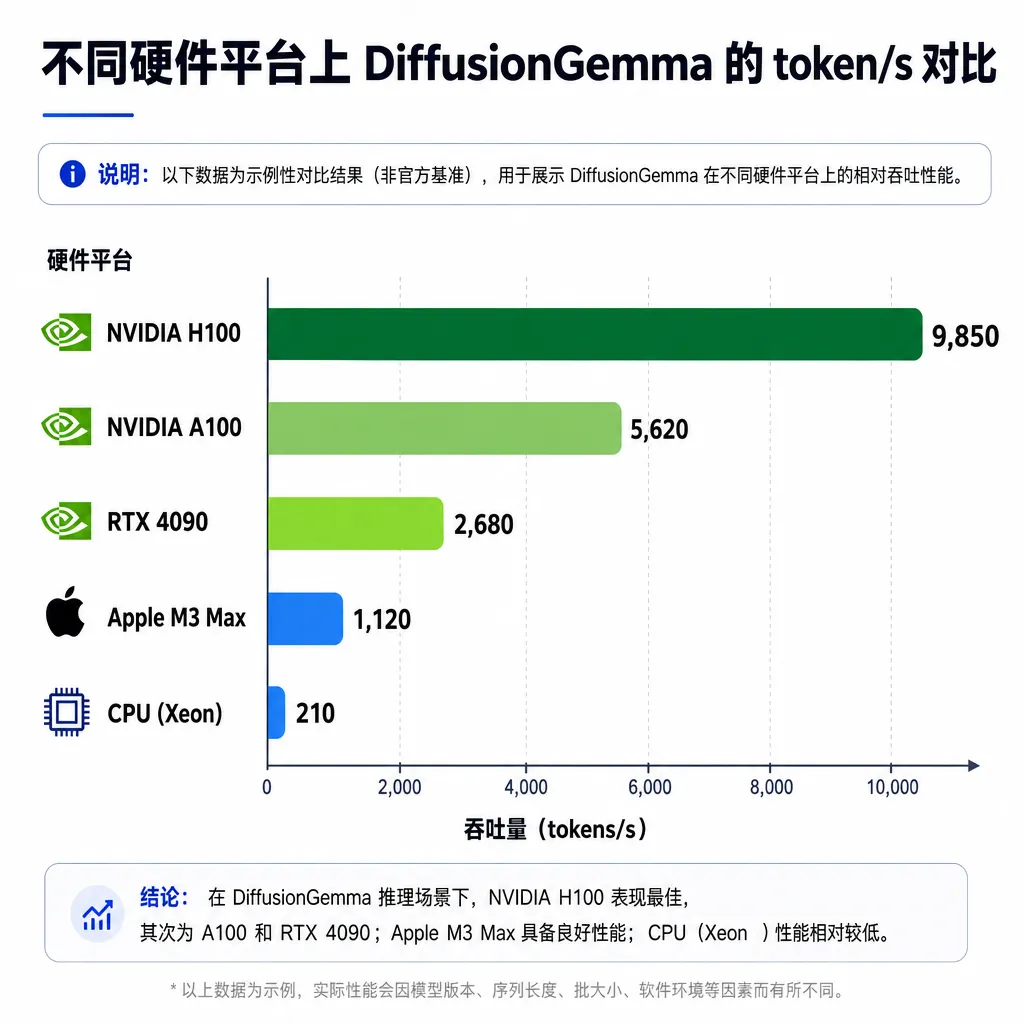
NVIDIA 测了一组数:H100 上约 1000 token/s,DGX Station 约 2000 token/s(这个数有不同口径,谷歌公告里给的是 800),DGX Spark 约 150 token/s,RTX 5090 突破 700 token/s。采样速度 1479 token/s,初始开销 0.84 秒。
这里要划个重点:4 倍加速是单请求、专属 GPU场景下的对比。如果你拿这个数去对比云端 vLLM batch 拉满之后的吞吐,那不公平也没意义。扩散的优势就是把单流速度推到极限,云端 batch 场景该用自回归还得用自回归。
另外 0.84 秒的初始开销也得注意——256 个占位符同时迭代意味着即使你只想生成一句话,最低延迟也下不去。短输出场景下,自回归的 first token latency 可能反而更优。
对开发者意味着什么
往大了说,这是大模型架构层面少见的一次非渐进式探索。过去两年大家卷的是 MoE、卷的是上下文长度、卷的是 RL 后训练,主干架构都是 Transformer 自回归这一套。DiffusionGemma 不一定能颠覆什么,但它至少证明了:在特定场景下,确实存在一条速度提升 4 倍的工程路径。
对开发者来说,几个值得关注的方向:
- 本地 AI 工具链:Cursor、Continue、Cline 这类编辑器辅助工具,最痛的就是云端延迟和隐私问题。一个能在本地 4090 上跑 700 token/s 的模型,对实时补全是质变;
- 填空类任务:双向注意力天然适合 fill-in-the-middle,比传统自回归靠 FIM token 模拟更优雅;
- 结构化生成:JSON、SQL、表格、数学符号这些有明确结构约束的输出,扩散的全局视野有先天优势;
- Agent 内部循环:Agent 经常需要短而快的工具调用决策,扩散模型的高吞吐配合自纠错可能是个不错的拍档。
但短板也别忽视:质量打了折,长文本一致性还没充分验证,事实准确性社区独立评测还得等一阵。生产环境上线之前,老老实实拿自己的真实负载跑一遍 A/B。
还有个伏笔
值得一提的是,Reddit 上有用户提到 NVIDIA 也几乎同时放了一个扩散模型。再加上 Gemini Diffusion 的研究基础——这次 DiffusionGemma 显然是那条线的开源版本——可以看出谷歌和 NVIDIA 都在把这条路当成正经赛道在投。
如果扩散文本能在 6-12 个月内把质量差距收敛到自回归同尺寸模型的 5% 以内,那本地 AI 部署的格局可能要重写。如果收敛不了,那它会留在"本地 IDE 插件"这个细分生态里,作为一个高速补充存在。
DiffusionGemma 的权重已经在 Hugging Face 上线,Apache 2.0 协议,可以直接拉下来试。OpenAI Hub(openai-hub.com)作为一个 Key 调所有主流模型的聚合平台,后续也会跟进开源模型生态的相关支持,目前对 Gemma 系列、Claude、GPT、DeepSeek 等已经覆盖到位。
速度这件事,开发者会用脚投票。
参考来源
- Reddit r/LocalLLaMA:DiffusionGemma 4x faster text generation 讨论 — 社区第一波实测反馈和与 NVIDIA 同期扩散模型的对比讨论
- IT 之家:谷歌推出 DiffusionGemma 文本扩散模型 — 国内媒体对发布会的中文整理,含 benchmark 详细数据
- Hugging Face:DiffusionGemma 模型权重 — 模型权重下载与官方 model card(Apache 2.0 许可证)

