Concept-Vector 开源:让词向量变成人能读懂的概念表

一个独立开发者把词向量的'黑盒坐标'重新拆解成带标签的可读概念维度,每一维都对应人类能定义的语义或句法属性。框架还在早期,但思路值得 NLP 圈一看。
一个数据设计师,跑去拆词向量的黑盒
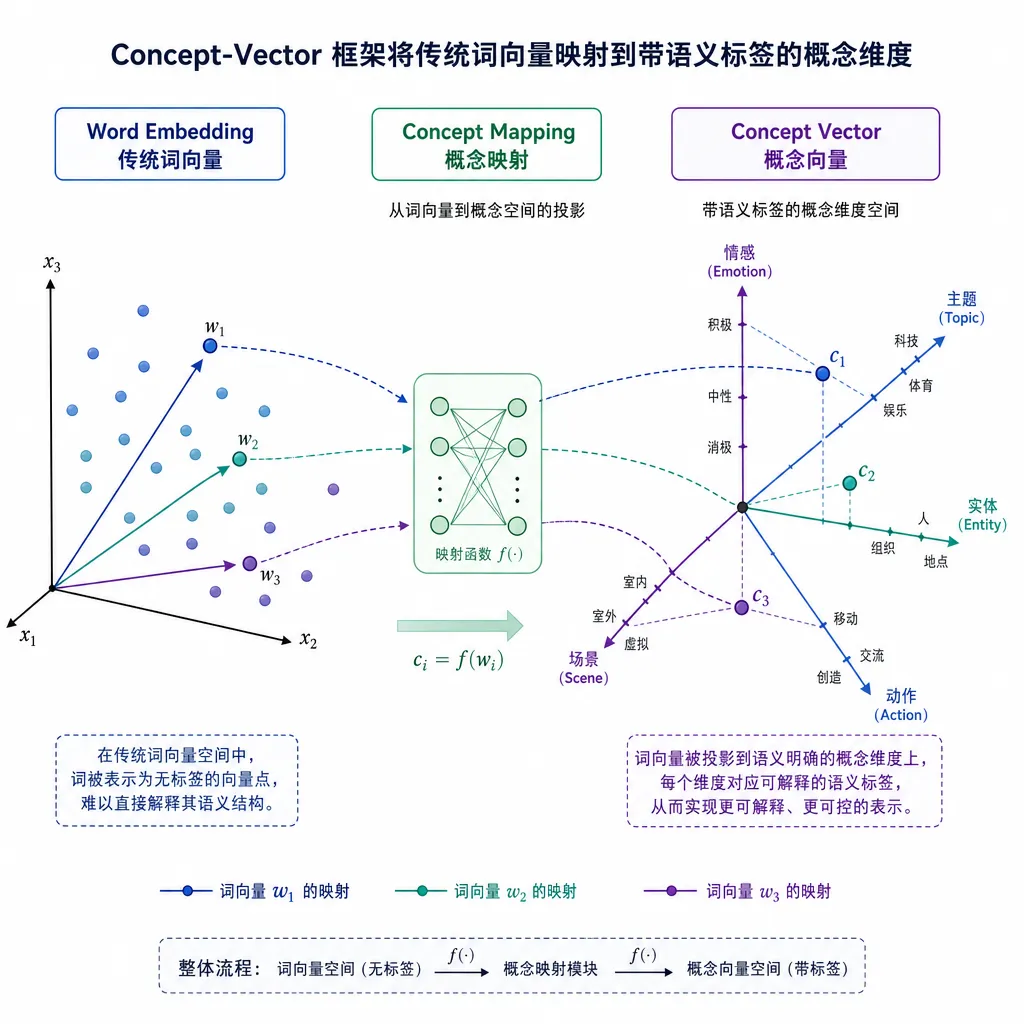
6 月初,一个 ID 为 true-hum 的开发者把自己折腾了一段时间的项目 Concept-Vector 扔到了 r/MachineLearning。项目的目标听起来有点反潮流:在所有人都在堆参数、堆上下文窗口的时候,他想做的是把词向量(word embedding)那 300、768、4096 维的黑盒坐标,重新拆成人类看得懂的概念维度。
说白了,就是给词向量的每一维贴标签:这一维管「是不是动物」,那一维管「是不是过去时」,再下一维可能管「在语料里出现频率高不高」。每一维都有一个人类可读、并且可以由人去定义的 label。
作者很坦诚,开头就说自己是个数据设计背景的人,数据变换、数据建模玩得熟,但神经网络经验有限。项目目前还没在真实模型上跑过完整实验,连一个像样的测试数据库都没钱搭。他发帖主要是为了收集反馈,顺便把想法亮出来——这是他暂时能推到的极限。
这种坦诚在 ML 社区其实挺难得,大多数自荐项目要么吹得天花乱坠,要么用一堆论文引用糊脸。Concept-Vector 没有 Benchmark,没有 SOTA,就是一份设计文档加一些 scratch notebook。但它点中的问题是真的:词向量从 2013 年 Word2Vec 出来到现在,可解释性这件事一直没解决干净。
为什么这个问题十几年没被啃下来
要理解 Concept-Vector 想做什么,得先回到词向量本身的问题。
Word2Vec、GloVe、FastText 这一代分布式表示,核心思路是「上下文相似的词,向量也相似」。这套思路非常 work——「国王 - 男人 + 女人 ≈ 女王」这种线性类比成了入门教材的经典案例。但代价是,每一个维度本身没有任何固定语义。你拿到一个 300 维的 king 向量,第 47 维到底代表什么?没人知道。它可能在一次训练里捕捉了「皇室属性」,下一次训练换个随机种子,第 47 维就变成了别的东西。
后续的研究试过很多路径:
- 稀疏化:通过 L1 正则或字典学习,让向量大部分维度为 0,希望非零维度能凸显某种语义。结果是稀疏是稀疏了,可解释性还是看运气。
- Probing classifier:训练小型分类器去探测向量里编码了什么信息。能告诉你「句法信息在第 6 层」,但没法告诉你哪一维对应主语。
- Disentangled representation:VAE 系列搞过的解耦表示,在图像上有些效果,在 NLP 上一直没成主流。
- Dictionary learning + Sparse Autoencoder:Anthropic 这两年大力推的方向,用 SAE 把模型隐层激活分解成数万个可解释 feature。效果不错,但训练成本高,而且 feature 还是模型自己长出来的,人类只是事后命名。
Concept-Vector 走的是另一条路——它不是去事后解释,而是从设计阶段就让维度有意义。
设计逻辑:把维度变成「人可定义的字段」
按作者放出的 readme 和 scratch notebook,Concept-Vector 的核心抽象大概是这样:
- 一个 concept-vector 是一组字段的集合,每个字段对应一个可读 label。
- 字段的类别可以涵盖语义(是不是动物、是不是抽象名词)、句法(词性、时态、单复数)、统计(频次、共现强度),理论上也可以加任何你能定义的属性。
- 每个字段的取值方式由设计者决定——可以是 0/1 的二值,可以是连续标量,也可以是离散桶。
- 多个字段组合起来,就构成一个完整的概念向量,原则上能映射到任何下游模型的 embedding 空间。
这个设计思路其实更像数据库 schema 而不是机器学习模型。作者是数据设计出身,这一点骗不了人。他把每个词当成一行记录,把每个语言学属性当成一列字段,向量空间被强行打回到关系模型的世界里。
这种做法的优势很明显:
- 可控。你想让模型对「时态」敏感?加一个时态字段。想让它能区分专有名词?加一列。维度的含义是设计出来的,不是猜出来的。
- 可调试。某个词的向量在某个维度上数值异常,你能直接定位到是哪个语言学属性出了问题,而不是面对一堆浮点数发呆。
- 可组合。不同语种、不同领域可以共享一部分字段(比如词性),再各自扩展专属字段(比如中文的量词、日语的敬语等级)。
但代价也同样明显。
问题在哪:标注成本与表达力的两难
稍微做过 NLP 的人都会立刻反应过来:这些字段从哪来?谁来标?
词汇表动辄几十万词,每个词要在几十甚至几百个字段上打分。如果靠人工,这就是上一代语言学家做 WordNet 的工作量;如果靠规则,覆盖不全;如果靠现成模型反推,那就回到了「用一个黑盒解释另一个黑盒」的循环。
作者自己也意识到这一点,所以 readme 里花了不少篇幅讨论字段可以是层级化的、可继承的——比如「动物」字段下可以挂「哺乳动物」「鸟类」子字段,这样标注一个上位概念能自动传播给下位概念。这是一种典型的本体论(ontology)思路,跟知识图谱社区那套东西天然对接。
另一个隐忧是表达力。Word2Vec 之所以打败传统的 one-hot 和共现矩阵,关键就是它捕捉到了那些没法用人类标签穷举的隐性语义。你能用语言学字段定义「皇室」「性别」,但你怎么定义「这个词读起来很高级」「这个词在金融语境里偏负面」?语言里有太多模糊、连续、上下文相关的东西,强行塞进 schema 会丢信息。
所以 Concept-Vector 大概率不会替代分布式表示,更可能的位置是作为它的可解释索引层——原始 embedding 还在底下跑,上面挂一层 concept-vector 用来调试、过滤、做规则注入。

跟 SAE、跟知识图谱的关系
把它放回当前的可解释性版图里看,Concept-Vector 的位置挺微妙的。
和 Sparse Autoencoder 比:SAE 是自下而上的,让模型自己长出 feature,再让人事后命名。Concept-Vector 是自上而下的,人先定义 feature,再去拟合。SAE 的优势是能发现人想不到的 feature,劣势是 feature 数量爆炸、命名成本高、有些 feature 至今没人能解释;Concept-Vector 的优势是从第一天起就可读,劣势是表达力受限于设计者的想象力。
和知识图谱比:知识图谱也是把概念结构化,但它处理的是实体之间的关系(北京 - 首都 - 中国),不是词的内部语义维度。Concept-Vector 更像把知识图谱的字段化思路下沉到了 token 层。
和 Probing 比:Probing 是事后诊断,Concept-Vector 想做的是先验设计。从工程角度,前者更像 APM 监控,后者更像写带类型的代码。
它能用来做什么
如果这套东西真能跑通(这是个大 if),它在几个场景会有意思:
- 对齐与安全:你能直接在向量里看到「攻击性」「色情」「政治敏感度」这种字段,过滤起来比训一个分类器更透明。
- 小语种与低资源场景:标注成本虽然高,但一旦把 schema 建起来,能复用到该语种的所有下游任务,不用每个任务都重新堆数据。
- 领域特化:医疗、法律、金融这些有强本体论传统的领域,本身就有现成的术语层级,Concept-Vector 能直接吃掉这些先验。
- 调试 LLM 的 embedding 层:当你怀疑某个 LLM 在某个语义上表现差,可以用 concept-vector 当探针,定位是哪个语言学维度被压缩或丢失了。
但要走到那一步,作者还差很多东西。最缺的不是想法,是算力和数据——他在帖子里明说没资源搭测试库。这个项目目前的状态更像一份 RFC,一份待证伪的设计草案。
一些不太客气的判断
说几句直接的。
Concept-Vector 这个项目现阶段没法直接用。没有训练好的权重,没有 benchmark 数据,没有跟现有 embedding 模型对接的工程脚手架。开发者自己也承认,他能推到的就是设计层面。
但作为一个思路,它值得 NLP 圈尤其是可解释性方向的人看一眼。原因有两点:
第一,它代表了一种被主流冷落的研究范式——从数据建模而非从模型架构出发去解决可解释性。过去几年 SAE 之所以火,是因为大模型时代「自下而上发现 feature」这件事变得可行了。但自上而下的设计思路并没有被证伪,只是没人愿意花时间做枯燥的本体论工作。
第二,它来自一个非 ML 背景的人。说实话,ML 这几年内卷的一个副作用是,大家都在卷同一套话语体系内的微创新,从外部学科带新视角进来的人越来越少。一个数据设计师跑来拆词向量,结论不一定对,但他看问题的角度就是不一样。
如果你对可解释性、symbolic-neural 混合表示有兴趣,建议直接去翻 readme 和 scratch notebook。这是那种读完会让你心里冒出新问题的项目,比读第 800 篇 RAG 优化论文有意思。
顺便一提,做这类实验性研究,常常要拿不同模型的 embedding 做对照——同样一段文本扔给 GPT、Claude、Gemini、DeepSeek 看它们各自的语义偏向。OpenAI Hub 把这些主流模型聚到一个 Key、一个 OpenAI 兼容接口下,国内直连,做这种横向对比的时候省心不少。
写在最后
词向量这个领域,热度已经被大模型和注意力机制盖过去很多年了。但**「一个词到底意味着什么」**这个问题,并没有因为模型变大而被解决,只是被掩埋了。Concept-Vector 这种小项目重新把它翻出来,提醒大家:可解释性不一定要等 SAE 训练完,也可以从数据 schema 开始想。
它能不能跑通,要看后续有没有人接力。但至少在 2026 年这个所有人都在拼 trillion-parameter 的时刻,看到有人安静地琢磨怎么把维度变得能读懂,是件挺让人舒服的事。
参考来源
- Concept-Vector: A design framework for human-interpretable word embeddings - Reddit — 原帖与项目作者的自述与讨论
- 一文读懂:词向量 Word2Vec - 知乎专栏 — 词向量基础概念与 Word2Vec 原理回顾


