阿里开源HappyHorse:8步生成音画同步视频

阿里由P11张迪领衔的新团队开源多模态视频生成模型HappyHorse,采用单Transformer Transfusion架构,仅需8步推理即可生成带音效、旁白的720p视频,曾匿名登顶Artificial Analysis Video Arena双榜。
阿里悄悄干了一件大事。
一个叫 HappyHorse 的视频生成模型,4 月初匿名出现在 Artificial Analysis Video Arena 的盲测榜单上,V1 和 V2 两个版本同时刷新了文生视频和图生视频的 Elo 分数,把 Seedance 2.0、Kling 3.0、PixVerse V6 这些一线选手全部压在身后。几天后 HappyHorse 1.0 又从榜单上消失了,只留下一堆截图和猜测。
现在谜底揭开——这匹黑马来自阿里,由 P11 张迪领衔的新团队打造,而且宣布完全开源。
先说最重要的:它开源了什么
不是那种「开源个 Demo 让你看看」的开源,是真刀真枪的全家桶:
- 基础模型权重
- 蒸馏模型权重
- 超分模块
- 完整推理代码
这意味着你拿到手就能跑,不用等官方 API,不用猜推理细节。对于一个刚登顶过 Arena 榜单的模型来说,这个开源力度相当罕见。要知道同级别的 Seedance 2.0 和 Kling 3.0 到现在还是纯闭源 API 模式。
架构上的野心:一个 Transformer 搞定一切
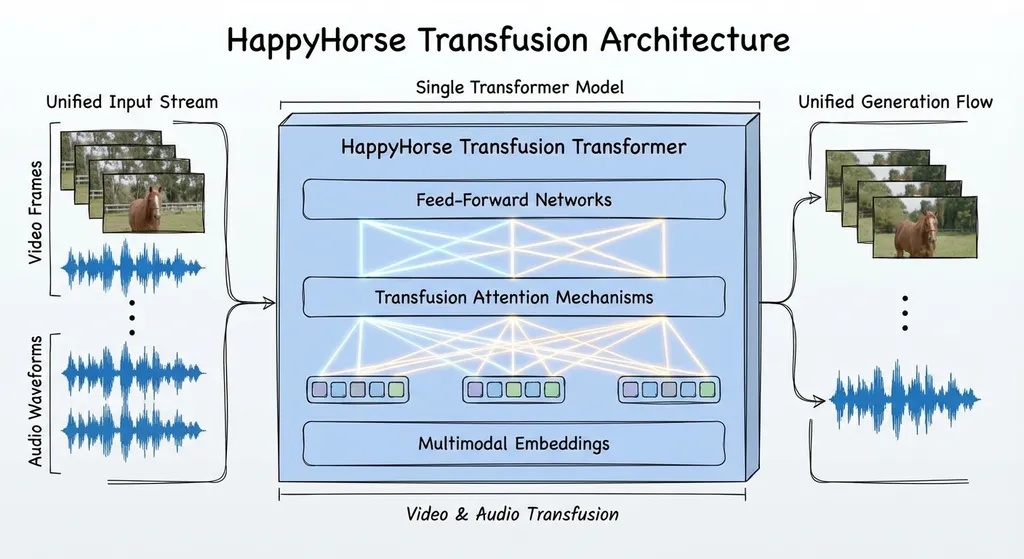
HappyHorse 最值得聊的不是分数,是架构选择。
当前主流的视频生成模型,音频和视频通常是两条管线。先生成视频,再用另一个模型配音、配音效,或者反过来。这种「拼装」方案的问题很明显:音画对不上、口型对不上、环境音和画面脱节。你用过就知道,AI 生成的视频里一个人在拍手,声音却晚了半拍,那种违和感比没有声音还难受。
HappyHorse 的做法是把视频和音频塞进同一个 Transformer,用 Transfusion 范式统一处理。简单说就是:模型在生成每一帧画面的同时,就在「想」这一帧该配什么声音。不是后期配音,是原生同步生成。
这个思路并不新鲜,阿里自家的通义万相 Wan2.5 就已经在探索原生多模态架构,能生成和画面匹配的人声、音效和背景音乐。但 HappyHorse 把这件事做得更极致——它连 CFG(Classifier-Free Guidance)都不用了。
做过图像生成的开发者对 CFG 不会陌生。它本质上是用两次前向传播来提升生成质量,代价是推理时间翻倍。HappyHorse 直接砍掉了这一步,只靠 8 步推理就能出片。作为对比,很多扩散模型需要 25-50 步,即使用了各种加速 trick 也很难压到 10 步以下还保持质量。
8 步,无 CFG,单 Transformer。这三个关键词叠在一起,指向一个很实际的好处:推理成本大幅下降。对于想在生产环境跑视频生成的团队来说,这可能比 Elo 分数更有吸引力。
具体能生成什么
参数层面:
| 参数 | 规格 | |------|------| | 分辨率 | 1280×720(720p) | | 帧率 | 24fps | | 生成时长 | 5 秒 | | 推理步数 | 8 步 | | 音频能力 | 音效 / 环境音 / 旁白 | | 支持语言 | 中 / 英 / 日 / 韩 / 德 / 法 |
720p、5 秒、24fps——单看这几个数字,说实话不算惊艳。通义万相 Wan2.5 已经能做 1080p、10 秒。Kling 3.0 和 Seedance 2.0 在分辨率和时长上也更激进。
但 HappyHorse 的差异化不在这些硬参数上,而在两个地方:
第一,音频是原生生成的,不是后挂的。它支持六种语言的旁白生成,加上音效和环境音,这意味着你给一段 prompt,出来的就是一个「能直接发」的视频,不需要再去找配音工具。对于短视频创作者和营销团队来说,这省掉了工作流里最烦人的一环。
第二,它是开源的。720p 5 秒听起来不多,但你可以在自己的机器上跑,可以微调,可以魔改。闭源模型给你 1080p 又怎样?你改不了一行代码,定价权完全在别人手里。
Arena 登顶又消失:一次精心策划的亮相?
回头看 HappyHorse 在 Arena 上的操作,挺有意思的。
4 月初匿名上榜,文生视频 Elo 1333,图生视频 Elo 1392,双双登顶。几天后 1.0 版本从榜单消失。紧接着团队身份曝光,宣布开源。
这个节奏很像是一次有计划的「先证明实力,再揭开面纱」。匿名盲测的好处是排除了品牌偏见——评测者不知道这是阿里的模型,纯粹凭生成质量打分。等分数站稳了再公布身份,说服力比直接发论文强得多。
当然也有人质疑:盲测环境下的表现能否代表真实生产质量?Arena 的评测样本量够不够大?这些都是合理的问题。但至少从方法论上说,这比自己跑 benchmark 然后自己发报告要可信。
跟竞品比,HappyHorse 处在什么位置
把 2026 年 Q1 的视频生成模型排一排:
闭源阵营里,Seedance 2.0、Kling 3.0、Veo 3.1 是第一梯队,分辨率高、时长长、商业化成熟,但都不开源,API 定价不便宜。
开源阵营里,之前基本没有能打的选手。通义万相 Wan 系列开源了不少模型,但主要集中在图像生成和基础视频能力上。HappyHorse 是第一个在 Arena 盲测中证明过自己、同时完全开源的视频生成模型。
这就是它真正的意义:不是说它现在就能替代 Kling 3.0 去做商业项目,而是它把「开源视频生成」的天花板一下子抬高了一大截。
用一个不太恰当的类比:HappyHorse 之于视频生成,有点像当年 Stable Diffusion 之于图像生成。参数不是最强的,但开源这件事本身就改变了游戏规则。
对开发者意味着什么
如果你在做视频相关的产品或功能,HappyHorse 开源带来几个直接的机会:
-
本地部署和微调。不用依赖第三方 API,数据不出域,适合对隐私敏感的场景。蒸馏模型的提供也意味着你可以在消费级显卡上跑推理,不一定需要 A100 集群。
-
音画同步的统一管线。之前要实现「生成视频 + 配音 + 配音效」需要串联三四个模型,现在一个模型一次推理就搞定。工程复杂度直接降一个量级。
-
作为 baseline 进行二次开发。8 步推理、无 CFG 的架构设计本身就是一个很好的研究起点,学术团队和创业公司都可以在这个基础上做文章。
当然,目前权重和代码的具体发布时间还没有最终确认。官方页面上 GitHub 仓库和 Model Hub 链接仍标注为 Coming Soon。建议持续关注官方动态,第一时间拉取代码验证。
如果你想现在就用上视频生成 API
在 HappyHorse 权重正式释出之前,如果你的项目等不了,可以先通过 API 调用已经商用化的视频模型。像 OpenAI Hub 这类聚合平台支持用统一的 OpenAI 兼容格式调用多家模型,等 HappyHorse 上线后切换 model 参数就行,不用重写代码。
一个典型的调用示例:
import requests
# 通过 OpenAI Hub 调用视频生成模型(OpenAI 兼容格式)
response = requests.post(
"https://api.openai-hub.com/v1/videos/generations",
headers={
"Authorization": "Bearer YOUR_OPENAI_HUB_KEY",
"Content-Type": "application/json"
},
json={
"model": "kling-3.0", # 未来可切换为 happyhorse-1.0
"prompt": "一只金色的马在草原上奔跑,阳光洒在鬃毛上,镜头跟随,环境音为风声和马蹄声",
"size": "1280x720",
"duration": 5,
"fps": 24,
"audio": True
}
)
print(response.json())
保持工具链中立是个好习惯。把 prompt 模板、审核流程、后处理管线先跑通,模型层面随时可以热切换。
更大的图景:2026 年视频生成的四个趋势
HappyHorse 的出现不是孤立事件,它折射出 2026 年视频生成领域正在发生的几个结构性变化:
单流 Transformer 替代多流复杂结构。以前视频生成模型动辄几个子网络串联,现在越来越多团队在验证「一个 Transformer 搞定一切」的可行性。HappyHorse 和通义万相 Wan2.5 都在走这条路。架构越简单,工程化越容易,社区生态越容易建立。
极少步推理替代几十步去噪。从 50 步到 25 步到 8 步,推理步数的压缩直接决定了部署成本和用户体验。8 步推理如果质量真的能打,那视频生成的实时化就不再是天方夜谭。
匿名上榜替代论文先行。越来越多的团队选择先在盲测中证明自己,再公布身份和技术细节。这种「用结果说话」的发布方式,比动辄几十页的技术报告更有效率,也更难造假。
开源承诺替代闭源 API。这一点最关键。当头部视频模型开始开源,整个生态的创新速度会指数级加快。想想 LLaMA 开源后发生了什么——几个月内社区就搞出了量化、微调、合并的完整工具链。视频生成领域可能正在迎来同样的拐点。
这四个变化任何一个单独出现都不算颠覆,但叠在一起,意味着视频生成正在从「少数大厂的专属游戏」变成「所有开发者都能参与的开放竞技场」。
冷静一下
话说回来,也别太上头。
720p、5 秒的规格在商业场景里确实偏弱。Arena 盲测的样本量和评测维度是否足够全面,还需要更多验证。开源承诺到实际放出权重之间,历史上也不是没有跳票的先例。
而且「登顶后消失」这个操作,虽然从营销角度很聪明,但也让人没法对模型做持续的独立评测。等代码和权重真正放出来,社区能跑起来、能复现 Arena 上的表现,那才是真正的盖棺定论。
不过有一点是确定的:阿里在视频生成上的投入在加速。从通义万相 Wan2.5 的原生多模态架构,到 Wan2.6 的多镜头叙事,再到现在 HappyHorse 的极简推理路线,不同团队在不同方向上同时推进。这种内部赛马的打法,在大模型时代已经被证明是有效的。
对开发者来说,最务实的做法就是:关注官方仓库,等权重放出后第一时间跑个 benchmark,同时保持现有工具链的灵活性,随时准备切换。
这匹快乐的马,值得你给它一个跑起来的机会。
参考来源:
- HappyHorse 模型幕后团队曝光 - Linux.do — 社区讨论帖,包含模型基本参数和团队信息
- 信源:微信公众号原文 — HappyHorse 模型官方信息发布
