QoderWork 给 AI 助理装了个"意识":会记忆、会反思、会自己长技能

阿里桌面 AI 助理 QoderWork 今日上线"意识"功能,集成记忆、反思和技能进化三个模块,让 AI 不再是每次对话都从零开始的金鱼。背后是一套分层记忆、快照回滚、Fork Session 的工程化方案。
QoderWork 给 AI 助理装了个"意识":会记忆、会反思、会自己长技能
6 月 16 日,阿里桌面 AI 智能体 QoderWork 上线了一个叫"意识"(Consciousness)的功能模块。听起来玄乎,拆开看其实是三件事:记忆、反思、技能进化。一句话概括——让这个跑在你电脑上的 AI 助理别再做"金鱼",每次对话都从零开始。
这是 QoderWork 自今年 1 月发布以来比较有分量的一次更新。前几个月它主要在补齐"能干活"这一层——能操作本地应用、能读文件、能调起设计和幻灯片工作台;这次的"意识"模块,瞄准的是"能记住活怎么干"这一层。从产品节奏看,阿里这条线已经开始往 Anthropic Cowork、月之暗面 Kimi Work、腾讯 Workbody 一票桌面 Agent 的竞争范式上靠了。
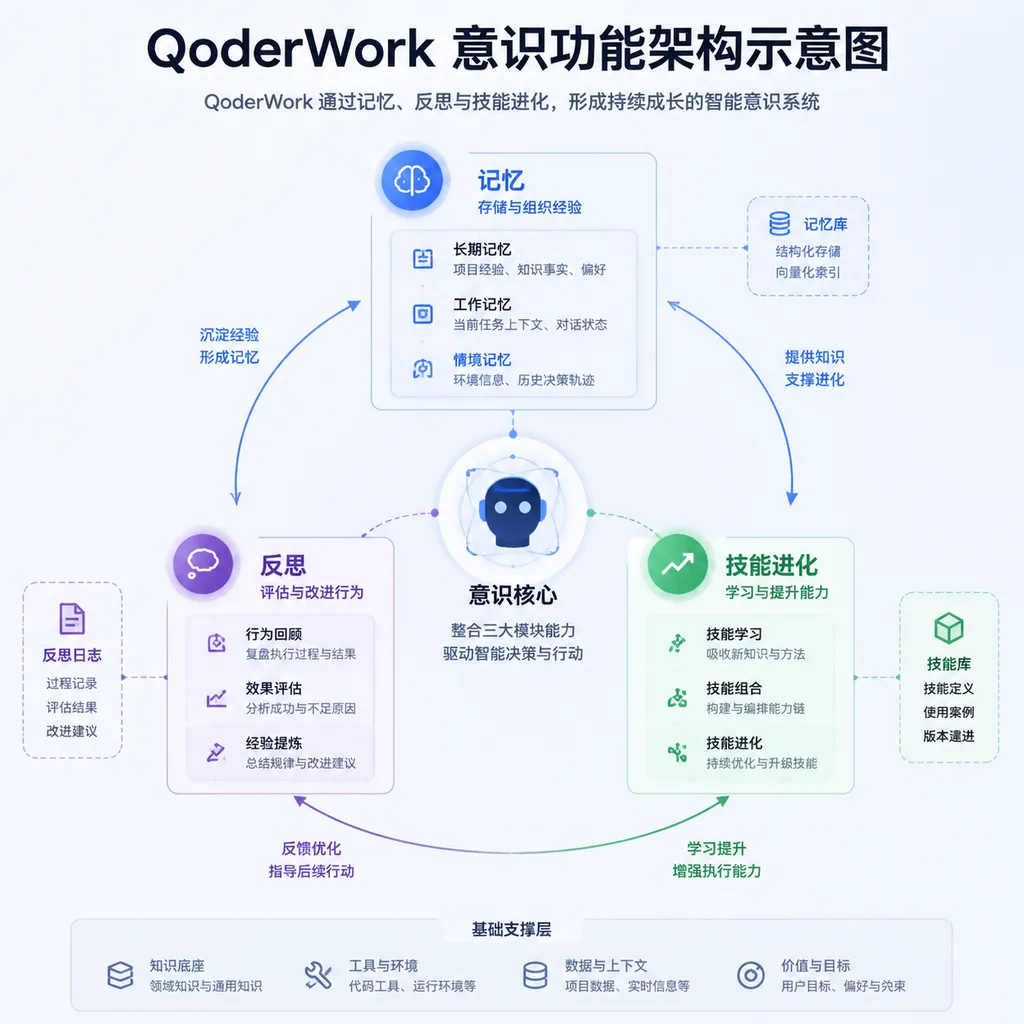
不只是"存对话",是分层记忆 + 主动淘汰
如果"记忆"等于"存历史会话",那这事 ChatGPT 两年前就在做了,没什么新意。QoderWork 这次的差别在于两点:分层和主动整理。
按官方描述,记忆系统分短期和长期两层:日常对话先沉到短期记忆,跨会话有复用价值的内容才晋升到长期记忆。这套结构本身不新鲜,Generative Agents 那篇 2023 年的论文就提过类似的分层架构,MemGPT、Letta 之类的开源方案也跑通过。但 QoderWork 把它落到了桌面 Agent 这个具体场景——你昨天让它整理过的发票格式、上周交代过的工作目录习惯、跟它聊过的项目背景,理论上都该在这一层里被沉淀下来。
关键是怎么"淘汰"。Agent 的记忆要是只进不出,半年下来上下文就被噪声塞爆,检索精度和推理质量都会塌方。QoderWork 给的方案是借鉴人脑的"选择性遗忘":每次反思前先做一次快照备份,反思动作完成后用硬规则做后校验,一旦发现关键信息被误删,自动回滚。
这一步"回滚"很重要。LLM 自己整理记忆是非常不可靠的——它可能把你最重要的客户名字当噪声给清了,或者反过来把一条临时调试日志当成长期偏好留着。硬规则 + 快照这种工程兜底,比纯靠模型自我裁决更工业级。
还有一个值得点赞的设计:所有记忆以 Markdown 文本明文存在本地,用户可以直接看、改、删。这跟动不动就把数据吃进黑盒向量库、用户连存了什么都不知道的方案完全是两种哲学。对开发者来说这意味着两件事:一是隐私和可审计性都立得住;二是这些 Markdown 文件本身就是可以被其他工具消费的语料,你完全可以把它们 grep 出来喂给别的 Agent。
反思机制:评分阈值才触发,不滥用 Token
"反思"是这次功能里最容易被讲虚的部分。AI 反思什么?怎么反思?反思一次烧多少钱?
QoderWork 给的回答是一个多因子加权评分模型:综合用户意图深度、对话长度、任务复杂度等维度,实时给每次对话打分,超过阈值才启动进化流程。换句话说,并不是每次你跟它聊天它都在背后偷偷开个会复盘——那种设计上线一周就能把 API 账单打爆。
触发之后呢?这里有个挺聪明的工程取巧:进化任务通过 Fork Session 机制从主会话分叉出一个轻量子会话,复用原始上下文。官方给的数据是缓存命中率 99% 以上,额外成本控制在主对话总开销的 5% 以内。
这个数字怎么理解?现在主流的长上下文模型基本都支持 prompt caching(Anthropic、OpenAI、Gemini 都有),命中缓存的 token 价格通常是非缓存的 1/10 甚至更低。Fork 出来的子会话只要不重复发送原始上下文,几乎只为新增的"反思指令"和模型输出付费。5% 的成本上限放在工程实践里是站得住的。
这套组合拳的意义在于:"让 AI 自我反思" 从一个 demo 级别的概念,被压成了能在 ToC 产品里铺量的成本结构。否则你想想,如果每次反思都要重发全部上下文,一个重度用户一天烧的钱比订阅费还高,商业模型立刻不成立。
技能进化:从"重复劳动"到"可复用脚本"
三个模块里,"技能进化"是离开发者日常体验最近的。
系统检测到你反复在做某类任务——比如每周一从某个文件夹批量重命名截图、每次写周报都先去抓某个 Dashboard 的数据——"意识"模块会自动生成一条技能建议。注意,是建议,不是直接写进你的技能库。用户可以采纳、忽略、驳回;被驳回的建议进入冷却,不会反复弹窗骚扰。
这套交互节奏背后体现的是一种克制:Agent 自动学习这件事很容易做成"自作主张",最后用户每天花一半时间在审查 AI 偷偷加了哪些怪东西。明确把决策权留给用户、加上冷却机制,是把产品做成了"建议者"而非"执行者"——至少在技能这一层是这样。
从技术抽象层面看,这其实是把 Anthropic 一直在推的 Skill 体系(Agent 通过编码持续扩展能力)和自适应学习结合起来。Claude Code 也好,Qoder 也好,背后都依赖 Programmatic Tool Calling 这类机制让模型能自己写工具、自己调工具。QoderWork 在这之上加了一层"自我观察":不仅能调技能,还能从历史调用中归纳出新技能。
跟 Manus、Kimi Work、Cowork 比,QoderWork 在哪一档
聊到这里就不得不放到桌面 Agent 这个赛道里看。2026 年这条线已经挺拥挤:
- Anthropic Cowork:最早把 Desktop Agent 概念做出来的,背后是 Claude 4.6+ 的长上下文和 Skill 体系,技术深度最稳
- Manus:上半年最出圈的,把 Agent + 浏览器 + 文件操作做成一个 Cloud Workspace 形态
- 月之暗面 Kimi Work:刚出 Beta,定位通用本地 Agent
- 腾讯 Workbody / MiniMax Desktop Agent:跟 QoderWork 同期的同形态产品
- Cognition Devin Desktop:从 Windsurf 升级而来,强调 Agent 指挥中心
横向对比,QoderWork 这次"意识"功能算是把长期记忆和自我进化这条线明牌打出来了。Cowork 的 Skill 体系强在工具维度的扩展,Manus 强在 Workspace 形态,QoderWork 选了一条偏认知架构的路线——更接近学术圈讲的 "Memory-Augmented Agent"。
是不是真比对手强?这个不好说,要看实际使用体验和长期效果。但至少从架构图上,分层记忆 + 快照回滚 + Fork Session + 阈值触发这套组合,在工程化程度上是经得起推敲的,不像某些 demo 产品只在 PPT 里好看。
几个值得开发者关注的细节
看完官方描述,我整理几条对开发者有实操参考价值的点:
- 记忆存储用 Markdown 明文:这意味着你可以脚本化处理它的记忆库,做迁移、做导出、做分析都很方便。也意味着出了问题你能 debug。
- Fork Session + 高缓存命中率:这是当下做"自我反思类"Agent 功能能不能扛住成本的关键。任何想自己造类似系统的团队,prompt caching 命中率是必须先压到 95%+ 的硬指标。
- 硬规则后校验回滚:不要相信 LLM 自己说"我整理过了没问题"。生产环境里所有让模型操作记忆/状态的动作,都必须有可回滚的快照和外部规则做兜底。
- 技能建议而非自动写入:自动化的边界要划清楚。Agent 自作主张是用户信任崩盘最快的方式。
写在最后
2026 年的 Agent 产品已经不能只靠"能调用工具"立住差异化了。Tool use 是基础设施,长上下文是基础设施,本地操作权限是基础设施——大家都有。下一步分胜负的是什么?
我的判断是:状态管理。
Agent 怎么记住你、怎么从历史里学、怎么避免噪声污染自己的判断、怎么把重复劳动沉淀成可复用资产,这些事比再多接一个 MCP server 都更接近用户实际的痛点。QoderWork 这次"意识"功能选的角度对,工程实现也看得出认真做过。能不能在产品体感上跑出来,还得看接下来几个月用户的真实反馈。
顺带提一句,QoderWork 本身的工作台架构(Chat / 设计 / 幻灯片 / 写作 + 行业专家套件)跟模型层是解耦的。对要做类似桌面 Agent 的团队来说,模型调用这一层用 OpenAI Hub 这种聚合平台会省不少事——一个 Key 切 GPT、Claude、Gemini、DeepSeek 这些主流模型,国内直连,兼容 OpenAI 格式,做 A/B 测试和成本优化都方便。
至于"意识"这个词用在 AI 产品上合不合适——见仁见智吧。但至少这次它指代的不是营销话术,是一套真实存在的工程机制。这一点比叫什么名字重要得多。
参考来源
- IT之家:阿里云 QoderWork 上线"意识"功能,让 AI 学会记忆、反思和成长 — 含分层记忆、反思机制、Fork Session 等技术细节的完整官方描述
