OpenRouter 推出 Fusion API:拼好模打平 Claude Fable 5
OpenRouter 上线 Fusion 复合模型 API,将一道题并行抛给多个模型再由裁判模型融合作答。预算组以 DeepSeek+Kimi+Gemini Flash 跑出 64.7%,逼平 Fable 5,成本只有一半。
多模型组团这事,终于被 OpenRouter 做成了产品
6 月 14 日,OpenRouter 在博客上甩出了一个叫 Fusion 的东西——一个复合模型 API。逻辑不复杂:你发一个 prompt 过去,它在背后同时分发给最多 8 个 LLM 并行作答,再用一个裁判模型把所有回答揉成一份最终结果。两天后的今天,社区里关于它的讨论几乎已经盖过了上周 Anthropic Fable 5 全球停服的风波。
这两件事撞在一块,时间点其实非常微妙。Fable 5 上周被美国政府以国家安全为由要求全球下架,开发者手里最强的那张牌瞬间失效。OpenRouter 紧接着在 14 日推出 Fusion,第一组对外宣传的成绩单就是:用 DeepSeek V4 Pro + Kimi K2.6 + Gemini 3 Flash 这三个便宜货组队,在 Perplexity 的 DRACO 深度研究基准上跑到 64.7%,距离 Fable 5 单跑的 65.3% 只差 0.6 个百分点,成本却只有一半。
这个时机和这个数字放在一起,意味就不一样了。
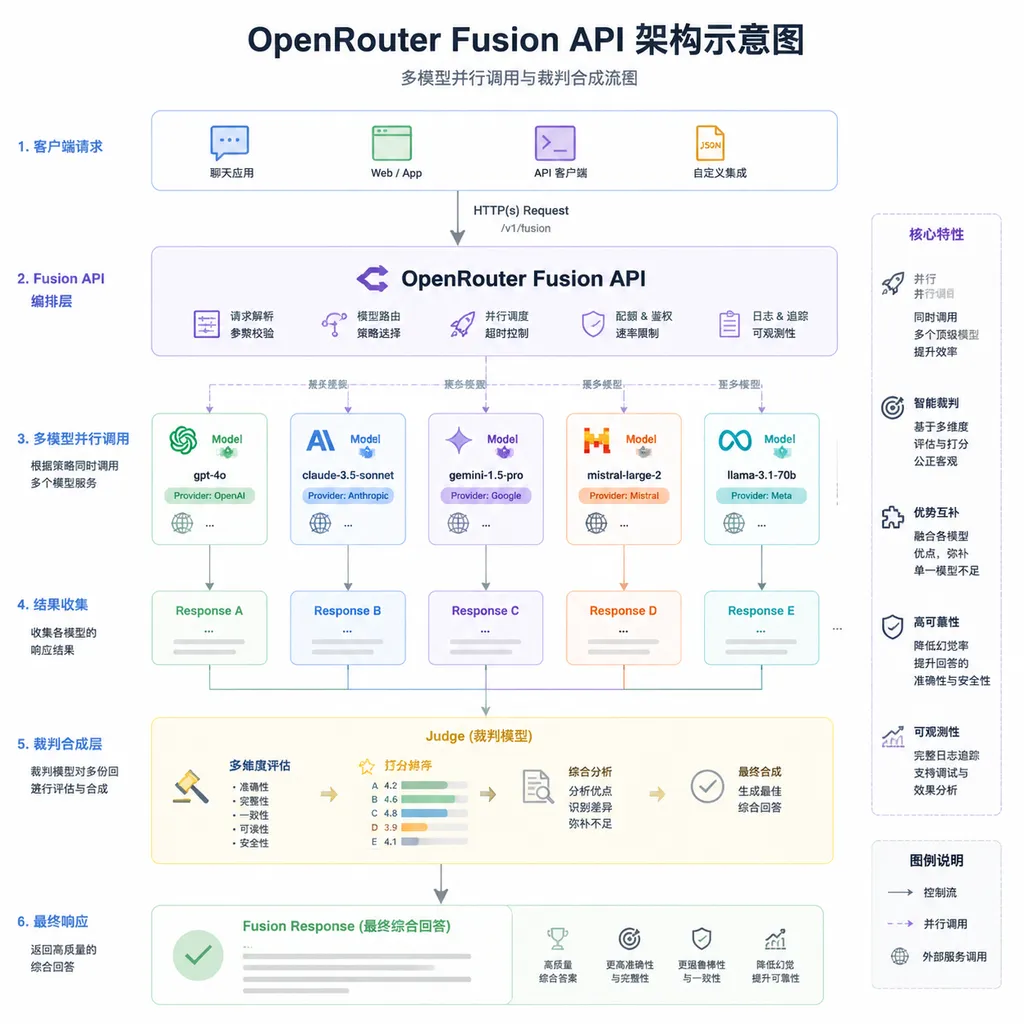
Fusion 到底怎么干活
官方文档把链路拆成了三步,逻辑很干净:
- 并行分发:用户的 prompt 同时打给 panel 里的所有模型,每个模型都自带 web search 能力,各自完成完整的推理与检索;
- 结构化评审:一个固定的裁判模型(目前默认是 Claude Opus 4.8)通读所有回答,输出一份结构化分析——哪些是共识、哪些互相矛盾、谁有独到见解、共同盲区在哪;
- 最终合成:由调用模型基于这份分析重新落笔,给出最终答复。
这个设计有意思的地方在于第二步。它不是简单的多数表决,也不是把回答拼接起来让模型「总结一下」,而是显式地让裁判去找 disagreement 和 blind spot。这件事在 agent 圈子里被叫做 self-consistency 或 ensemble reasoning,过去基本只在论文里和工程师自己手搓的 pipeline 里见到,OpenRouter 把它做成了一个 endpoint 级别的产品。
接入方式也极轻:API 调用里把模型名换成 openrouter/fusion 就行,剩下的并行分发、合成全在服务端跑完,一次调用拿结果。想让模型自己决定要不要组队的,也可以把 Fusion 挂进 tools 列表,让上层 agent 来调。完全不写代码的,直接打开 openrouter.ai/fusion 网页版选个预设套餐就能试。
跑分细看:组团真的能超过单个最强
这次基准用的是 Perplexity 出的 DRACO,专测深度研究能力,覆盖学术、金融、法律、医疗等 10 个领域,每道题约 39 条带权重的评分标准,答错扣分,靠堆字数刷不到分。100 道题的成绩单如下:
| 组合 | 成绩 | | --- | --- | | Fusion: Fable 5 + GPT-5.5(Opus 4.8 合成) | 69.0% | | Fusion: Opus 4.8 + GPT-5.5 + Gemini 3.1 Pro | 68.3% | | Fusion: Opus 4.8 + GPT-5.5 | 67.6% | | Fusion: Opus 4.8 × 2(同模型跑两遍) | 65.5% | | Solo: Claude Fable 5 | 65.3% | | Fusion: Gemini 3 Flash + Kimi K2.6 + DeepSeek V4 Pro(预算组) | 64.7% | | Solo: DeepSeek V4 Pro | 60.3% | | Solo: GPT-5.5 | 60.0% | | Solo: Claude Opus 4.8 | 58.8% | | Solo: Kimi K2.6 | 53.7% | | Solo: Gemini 3.1 Pro | 45.4% | | Solo: Gemini 3 Flash | 43.1% |
这张表里有三个点值得开发者好好看看。
第一,顶配组团能突破前沿天花板。 Fable 5 + GPT-5.5 的 69.0% 比 Fable 5 单跑高出 3.7 分,说明就算手里有当前最强模型,多拉一个不同血统的伙伴进来,依然能加分。这背后是模型多样性带来的覆盖增益——两家公司用了不同的训练数据、不同的对齐方式、不同的工具调用风格,错的题不一样,对的题能互补。
第二,同模型自我组队也能涨。 Opus 4.8 × 2 这一组特别值得玩味,同一个模型跑两遍再融合,分数从 58.8% 涨到 65.5%,整整多了 6.7 分。这意味着 Fusion 的增益相当一部分根本不来自「多家模型」,而来自「融合」这个动作本身。同一个模型在不同 sampling 下会走出不同的推理路径、调用不同的工具、选取不同的资料,把这些差异 reconcile 一遍就是显著提升。这对于做 agent 的人是个非常实用的信号——你不一定要花钱接好几家 API,把同一个模型多跑几次再合成,可能就够了。
第三,预算组是真正的产品突破点。 Gemini 3 Flash + Kimi K2.6 + DeepSeek V4 Pro 三个高性价比模型组团跑到 64.7%,干掉了单跑 60.0% 的 GPT-5.5、58.8% 的 Opus 4.8,逼到离 Fable 5 只差 0.6 分。成本是 Fable 5 的一半左右。这条线意味着「不用最贵模型也能拿到前沿水准」第一次不是 PPT 上的口号,而是 endpoint 级别可以直接调用的现实。
顺便说一下那个 65.3% 的小尾巴
Fable 5 的 65.3% 其实只跑了 93 道题,剩下 7 道被它自家的内容过滤器拦截了。OpenRouter 没拿 Opus 4.8 去补这 7 道,所以这是 Fable 真实能力的样子,但相比跑满 100 道的对手确实占了一点小便宜。Fusion 把这件事变得无关紧要——组团里某个模型掉链子,还有别人顶上。这种容错性对于上生产线的应用其实是个隐性 KPI。
这件事对开发者意味着什么
过去几年,行业默认的路径是把单个模型堆到尽可能强:参数更大、训练更久、能力更前沿,仿佛 AGI 就是一条单模型不断变强的直线。Fusion 抛出的反命题是:把多个视角各异的模型组织起来协作,产出可以超过其中任何一个——和一支多样化的人类团队能解决任何单个天才都搞不定的问题,是一个道理。
对一线开发者来说,这意味着工程层面要重新思考几件事:
- 模型选型不再是单选题。 过去做应用要在「全程用最贵」和「全程用便宜」之间二选一,现在可以在任务粒度上动态组队。简单任务走单模型,复杂任务走 Fusion,路由策略本身成了一个工程问题。
- 延迟和成本要重新算账。 Fusion 把延迟变成 max(各模型) + 裁判时间,不是 sum,但 token 成本是叠加的。对深度研究、合规审查、医疗法律这种「错一次代价极大」的场景,多花点钱买正确率是划算的;对客服闲聊就别上了。
- Prompt 工程要适配多模型。 你写的 prompt 要能让 panel 里背景迥异的模型都能正确理解任务。过于依赖某家模型独有的 system prompt 技巧的写法,在 Fusion 下会失灵。
- 评估体系要升级。 单模型时代的 eval set 是「问题—回答」对,Fusion 时代你得评估整个 panel 的协作质量,包括裁判模型有没有偏袒、有没有把错误共识当成正确答案。
国产模型的新位置
预算组那 64.7% 里,Kimi K2.6 和 DeepSeek V4 Pro 都是国产开源路线的代表。这件事的潜台词是:走开源、走性价比路线的国内模型公司,不必再在「单模型刷榜」上和闭源巨头硬碰,靠组合机制就能交付接近前沿的结果。
这对国内做 AI 应用的团队是个直接的利好。月之暗面和 DeepSeek 这两家原本在单模型基准上和 Anthropic、OpenAI 还有差距,但放进 Fusion 这种 ensemble 框架里,他们的「便宜」直接转化成了「ROI 更高」。Fable 5 全球停服的这个空窗期,可能正好是国产组合方案抢市场的窗口。
一些尚未解决的问题
Fusion 不是银弹,几个问题目前还没看到清晰的答案:
- 裁判模型本身的偏差。 用 Opus 4.8 当裁判,会不会系统性偏向 Claude 系答案?OpenRouter 没公开做过 cross-judge 的对照实验。
- 任务边界。 DRACO 测的是深度研究,对编码、agent 工具调用这类任务,Fusion 的增益是否同样显著,还没有公开数据。
- 流式输出体验。 三步链路里前两步必须串行等待,第三步才能开始生成,首 token 延迟比单模型高得多。对话类产品要不要用 Fusion,得自己掂量。
- 失败模式。 当所有 panel 模型都答错或都答得很烂时,裁判合成出来的东西可能是个「自洽但全错」的答案,反而比单模型更难发现问题。
OpenAI Hub 这边的情况
Fusion 对应的所有底层模型——Claude Opus 4.8、GPT-5.5、Gemini 3.1 Pro/Flash、Kimi K2.6、DeepSeek V4 Pro——OpenAI Hub(openai-hub.com)都已经在售,国内直连,一个 Key 切换,兼容 OpenAI 格式。如果你想在国内环境复现 Fusion 这种多模型协作 pipeline,自己用同一个 Key 在服务端并行调几个模型,再写一个简单的合成逻辑,体验和 OpenRouter Fusion 几乎一致,而且对 panel 组合、裁判 prompt 的控制度更高。对于不想被 OpenRouter 那一层封装锁住的团队来说,是个更灵活的选项。
写在最后
Fusion 真正的价值不是那一行能跑出 69% 的成绩,而是它把「多模型协作」从工程师私藏的 trick,变成了一个可被产品化、可被定价、可被路由的基础设施。
竞争的焦点正在悄悄挪位:谁能把一群参差不齐的模型调度好、融合好,可能和谁能训出最强的单个模型,变得同样重要。 OpenRouter 这次抢先卡位了 Harness 这一层,接下来看其他聚合平台和 Anthropic、OpenAI 自家会不会跟进类似能力。
至少在今天,做 AI 应用的人多了一个工具,也多了一种思路。
参考来源
- IT之家:全球最大 AI 聚合平台上线"拼好模"——Fusion API 发布详情与跑分数据汇总

