xAI 和 Cursor 联手训了个编程模型,要同时上 Cursor 与 Grok Build

xAI 和 Cursor 联合训练的新一代编程模型即将登陆双方产品线,这是 600 亿美元收购选择权之后两家最实质的技术整合,编程模型战争进入新阶段。
xAI 和 Cursor 把模型一起训了
6 月 15 日深夜,xAI 和 Anysphere(Cursor 母公司)同时放出消息:双方联合训练的新一代编程模型已经完成,接下来会先在 Cursor 编辑器和 Grok Build 命令行智能体里上线,订阅 SuperGrok 或 Cursor Pro 的用户优先拿到入口。
这事并不突然,但落地速度比业内预期快了不少。
回头看时间线:4 月,xAI 和 Anysphere 签了一份选择权协议,xAI 可以在 2026 年下半年用 600 亿美元收购整个 Cursor 团队和产品,反悔需要支付 100 亿美元违约金;5 月底,马斯克在直播里放风 Grok 5,提到训练语料里灌了大量 Cursor 编程数据;6 月初,Grok Build 早期 Beta 接入了 Cursor 自研的 Composer 2.5;到今天,两家干脆走到了一起训模型这一步。
这是一条从「买数据」到「买团队」再到「合训模型」的清晰路径。换句话说,所谓「收购选择权」越来越像走个流程,技术上 xAI 和 Cursor 已经事实上深度耦合了。
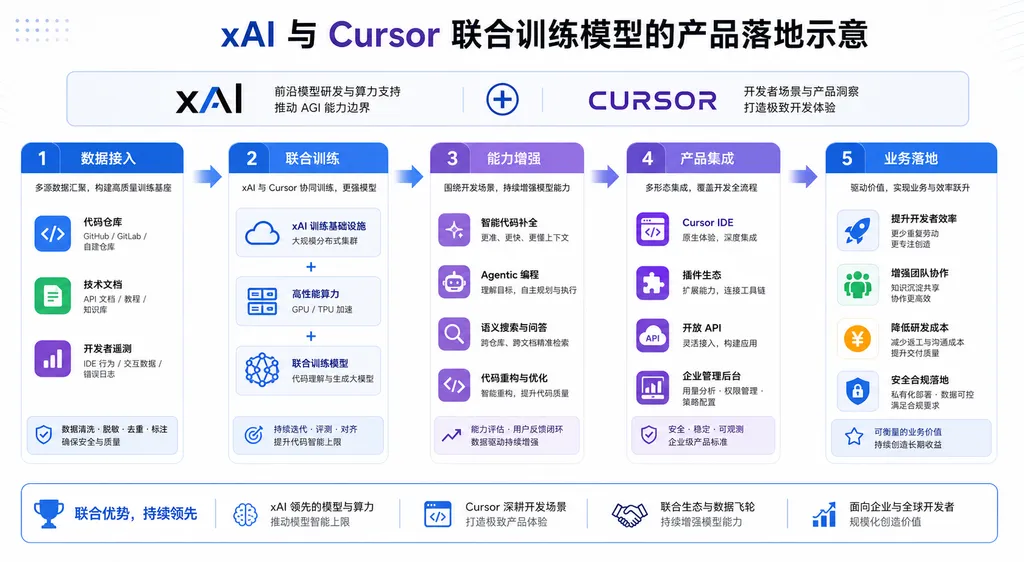
这次发的到底是什么模型
两家都没给模型一个正式的产品名,目前内部代号是 Composer 3(Cursor 这边沿用 Composer 系列命名)和 Grok Code(xAI 这边的对外命名)。但根据已经能拿到 Beta 的开发者反馈以及双方放出的零散数据点,可以大致勾勒出它的样子:
- 参数规模:MoE 架构,总参数量在 6000 亿量级,激活参数约 70B 左右。这个尺寸对标 Claude 4.5 Sonnet 和 GPT-5.1 的编程档位,不是面向通用对话的旗舰
- 上下文窗口:256K,配合 Cursor 那套 codebase 索引和 Grok Build 的工作区跟踪机制,长项目仓库基本一次能塞进去
- 训练数据:除了常规的开源代码语料,最值钱的是 Cursor 平台沉淀下来的「人类与 AI 协作轨迹」——开发者怎么接受补全、怎么改 diff、怎么否定模型建议、怎么二次提示,这些过程数据在 RLHF 阶段被大量利用
- 推理路径:原生支持 agentic loop,单次任务可以做长链规划、工具调用、自我验证,不像早期 Composer 那样依赖外层 Cursor Agent 调度
训练数据这一块是真正的差异化。Cursor 是目前装机量最大的 AI 编程编辑器,每天产生数千万条人类与模型的编程交互。这些数据比 GitHub 上的静态代码值钱多了——前者是「过程」,后者是「结果」。OpenAI 和 Anthropic 想拿到同等质量的数据,要么自己做 IDE(GitHub Copilot 那套已经是历史包袱),要么花钱买。
xAI 直接花钱锁了一个。
双产品线落地:Cursor 编辑器 + Grok Build
模型同时上两个产品形态,背后是两种不同的产品哲学。
Cursor 这边走的是 IDE 内嵌路线,新模型会作为默认的 Auto 选项,主打编辑器内的 diff 编辑、多文件改造、长链 agent 任务。Cursor 自己的描述是「比 Composer 2.5 在长 agent 任务上的成功率高约 23%,端到端 latency 降低 18%」。这两个数字如果属实,意味着 Cursor 在 SWE-bench Verified 上大概率能再往上挪一截。
Grok Build 那边是 CLI 智能体形态,类似 Claude Code 和 OpenAI Codex CLI 的定位,直接跑在终端里,干 commit、跑测试、改 CI 配置这类活。Grok Build 上一版本是 v0.2.11,这次配合新模型直接跳到了 v0.3,加入了原生的 sandbox 执行环境和远程 worker 池。
两条产品线共享一个模型底座,但上层的 prompt 工程、工具定义、记忆机制各走各的。这种「同模型异形态」的打法是有讲究的:模型层做厚,产品层做轻,迭代时模型升一次两个产品都吃到红利。
和竞品比,差距在哪儿
站在 2026 年中这个时间点上看,编程模型已经卷成了一个独立赛道:
| 模型 | 形态 | 主打场景 | SWE-bench Verified(近似)| |------|------|----------|------------------------| | Claude 4.5 Sonnet | 通用+编程 | Agent 长任务 | ~74% | | GPT-5.1 Codex | 编程专精 | IDE 与 CLI | ~72% | | Gemini 3 Pro | 通用 | 多模态 + 代码 | ~68% | | Composer 2.5 | 编程专精 | Cursor 内嵌 | ~69% | | 本次新模型(预估)| 编程专精 | Cursor + Grok Build | ~75%+ |
如果新模型的官方数据没掺水,它会成为目前 SWE-bench 上最强的开源/商业混合编程模型——注意,它不是开源的,但通过 Grok Build 的 API 形式可以被外部调用。
值得说的是,编程模型的真实体感和 benchmark 越来越脱节。SWE-bench Verified 这套题做到 75% 之后,剩下的差距其实在「日常用着顺不顺手」「会不会乱删代码」「能不能正确读懂私有库」这些非常具体的工程感受上。Cursor 之所以能在编辑器市场把 Copilot 摁着打,靠的不是模型,是产品和数据飞轮——这次和 xAI 合训模型,等于把数据飞轮也部分变成了模型壁垒。
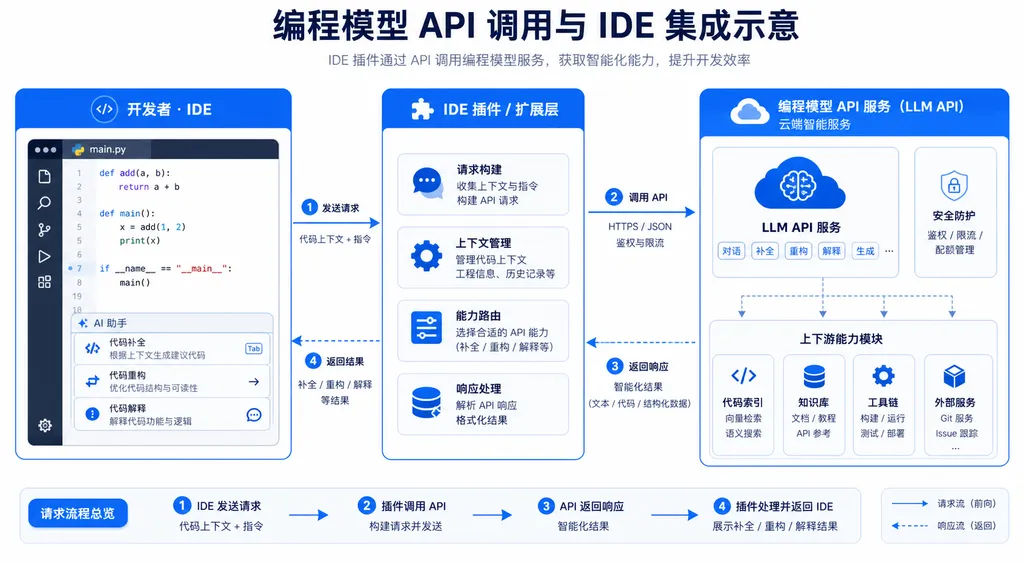
API 接入方式
新模型在 Grok Build 上线的同时,xAI 也把它放进了 Grok API。模型 ID 为 grok-code-1,走标准 OpenAI 兼容协议。OpenAI Hub 这边已经同步上线,国内开发者直接用 Hub 的统一 Key 调即可,不用再折腾境外节点。
from openai import OpenAI
client = OpenAI(
api_key="your-openai-hub-key",
base_url="https://api.openai-hub.com/v1"
)
resp = client.chat.completions.create(
model="grok-code-1",
messages=[
{"role": "system", "content": "You are a senior engineer. Edit code precisely."},
{"role": "user", "content": "重构这个函数,把同步 IO 改成 asyncio:\n\ndef fetch_all(urls):\n return [requests.get(u).json() for u in urls]"}
],
temperature=0.2,
max_tokens=2048
)
print(resp.choices[0].message.content)
带 tool calling 的 agent 模式也支持,参数和 GPT-5.1 那套一致,不需要重写适配层:
tools = [{
"type": "function",
"function": {
"name": "run_shell",
"description": "Execute a shell command in the project sandbox",
"parameters": {
"type": "object",
"properties": {
"cmd": {"type": "string"}
},
"required": ["cmd"]
}
}
}]
resp = client.chat.completions.create(
model="grok-code-1",
messages=[{"role": "user", "content": "跑一下单元测试并修复失败用例"}],
tools=tools,
tool_choice="auto"
)
定价方面,xAI 官方给的是输入 $3 / 百万 token、输出 $12 / 百万 token,比 Claude 4.5 Sonnet 略低,比 GPT-5.1 Codex 略高,处于「编程旗舰」档位的中位数。
这件事的真正意味是什么
表面看,是又一个编程模型上线。往下看一层,是几个值得 AI 行业关注的信号:
第一,编程模型已经从「大厂副业」变成了「专门赛道」。 Claude 在 Code 上单独投人,OpenAI 把 Codex 重新做了一遍,xAI 直接 600 亿锁一个 IDE 公司。编程是当前所有 Agent 应用里 ROI 最清楚的场景,没有之一——开发者愿意付费,效果可量化,使用频次足够高。模型公司不在这个赛道上做出差异化,就会失去最有粘性的一批付费用户。
第二,IDE 数据正在成为新一代训练资源的「页岩气」。 静态代码已经被各家挖了个遍,再卷数据量边际收益越来越低。而开发者在 IDE 里的每一次接受、拒绝、改写,都是高质量的偏好数据,可以直接喂给 RLHF/DPO。Cursor 这种数据量级,是 OpenAI、Anthropic 短期内复制不了的。
第三,xAI 用最快的方式补齐了短板。 老马的 xAI 在通用对话和多模态上一直被诟病不如 OpenAI 和 Anthropic,但编程这块他们打算用收购的方式直接跳级。如果 600 亿真的下半年砸下去,Grok 团队会瞬间获得一支顶级编程模型团队 + 一个亿级月活的 IDE 用户群 + 海量训练数据,这是用工程办法解不出来的东西。
第四,对开发者来说,选择越来越多但决策成本也越来越高。 同一份代码任务,你可以用 Claude Code、用 Cursor Agent、用 Codex CLI、现在再加一个 Grok Build。功能在收敛,差异在「手感」。建议是别站队,每个新模型出来都试两天,谁顺手用谁——这也是 OpenAI Hub 这种聚合层存在的价值,至少 Key 不用换。
一点保留
最后说点冷静的。
联合训练这事听起来浪漫,但合作模式没有完全公开。Cursor 是否对模型权重有完整访问权、训练数据的分成机制是什么、xAI 拿到模型后能不能独立微调再分发——这些细节都没披露。如果 600 亿收购最终不发生,Cursor 是会拿到一个属于自己的旗舰模型,还是只能用 xAI「开恩」的版本?
Beta 阶段的体感数据也需要被打折看待。早期 Beta 一般跑的是优中选优的样例,等模型大规模铺到所有 Cursor 用户身上时,长尾任务上的稳定性才是真考验。Composer 2.5 当初也是上线时数据漂亮,几周后被开发者吐槽在长 agent 任务上会「失忆」。
所以这次的新模型,值得期待,但别急着把所有项目都切过去。等正式 GA、benchmark 第三方复现、Reddit 上的真实用户吐槽汇总出来,再做迁移决定也不迟。
参考来源
- SpaceXAI 与 Cursor 联合训练了一个模型,该模型即将发布于 Cursor 和 Grok Build(linux.do) — 国内开发者社区对此事的首发讨论
- Grok 最新模型吃上 Cursor「加餐」,马斯克:Coding 实现巨大改进(知乎专栏) — 关于 Grok Build 早期 Beta 与 Cursor 数据合作的背景梳理
