逆矩阵发布 Physis-v0.1:世界模型从「预测下一帧」跳到「预测下一个物理状态」

逆矩阵科技联手智源研究院,发布全球首个通用世界基座模型 Physis-v0.1,主打物理正确、动作因果、长程一致与通用泛化。同步官宣超亿美元种子++轮融资,创始人陈博远判断窗口期已从36个月压到18个月。
世界模型赛道,进入「预测下一个物理状态」阶段
6 月 12 日的智源大会上,逆矩阵科技(Physis)联合北京智源研究院抛出了一个东西——悟界·Physis-v0.1,号称全球首个通用世界基座模型。两天后,36氪披露逆矩阵已完成超亿美元种子++轮融资,距上一轮千万美元首轮只过去了不到三个月,经纬、五源、光合参投,蚂蚁战投,高瓴和燕缘老股东继续加注。
节奏快得反常,但也说明了一件事:一级市场对世界模型的押注已经从「广撒网」切换到「向头部集中」。逆矩阵创始人陈博远在采访里给的判断更直接——通用世界基座模型的窗口期,已经从 36 个月压缩到 18 个月。这话翻译过来就是:再晚两个季度进场,基本就没你的事了。
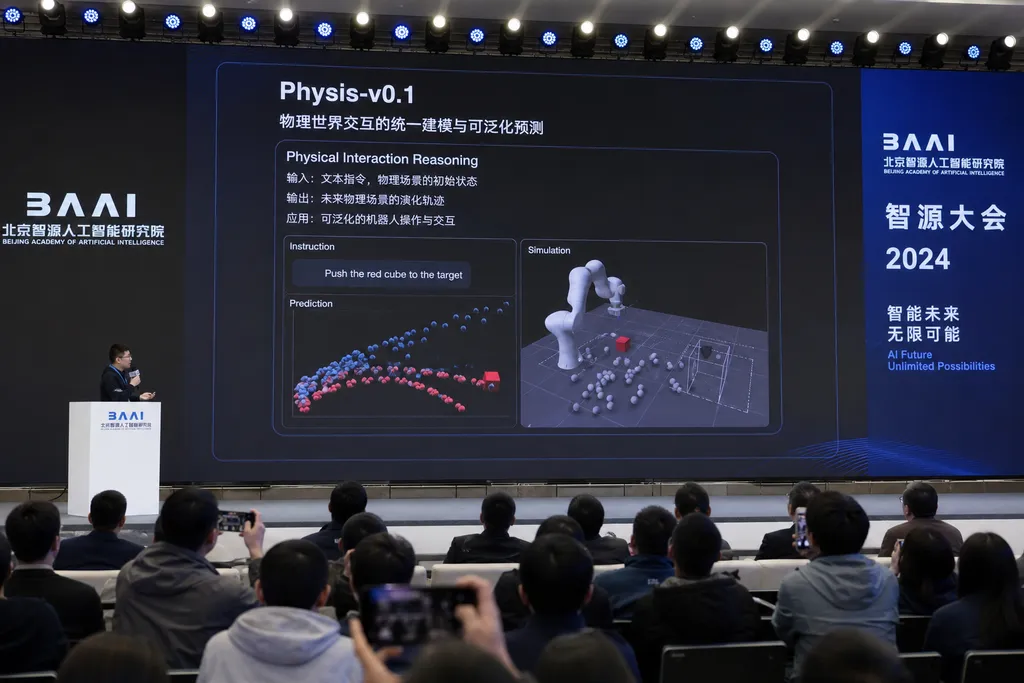
Physis-v0.1 到底是个什么东西
要看懂这个模型的位置,先得理清楚现在世界模型的四条主流路线。智源院长王仲远在发布现场把它们分得很清楚:
- 以语言为中心:VLM / VLA 模型,学的是「语言描述的世界」
- 以像素为中心:视频生成模型(Sora 那一路),学的是帧到帧的视觉演化
- 以三维结构为中心:重建类模型,学的是几何
- 以视觉表征为中心:JEPA 系列,LeCun 那一路的隐空间预测
这四条路线各自有各自的问题。最致命的是——它们要么只懂语言里的「世界」,要么只懂像素层面的「像」,没有一个真正学会了物理规律本身。王仲远在现场举了个特别尖锐的例子:视频模型可以生成天上飞的猪,这在数字世界是有趣,到物理世界里就是事故。
Physis-v0.1 的切入点是另起炉灶——它不预测下一个 token,也不预测下一帧像素,而是预测下一个物理状态。
技术上的关键改动在于引入了一个专属物理状态编码器,把视频、深度 RGB、3D 点云、力触反馈这些异构模态全部统一编码到一个标准化的物理隐空间里。换句话说,模型不再纠结「画面长什么样」,而是直接在「物体的位置、速度、受力、接触状态」这一层做演化预测。这跟以像素为中心的视频模型是两套范式。
官方给出的四项核心能力是:
- 物理正确:刚体、流体、接触、摩擦这些基础规律不能拍脑袋
- 动作因果可溯:给定动作输入,能反推每一步状态变化的因果链
- 长程一致:不会跑十几秒后物体突然「漂移」或穿模
- 通用泛化:一次预训练覆盖具身、工业仿真、游戏物理、科学预测多类场景
目前 v0.1 已经支持五十多个复杂物理场景的长程推理。
为什么这件事比想象中更重要
你可以把过去十年 AI 的进展拆成三次范式跃迁:
| 阶段 | 预测对象 | 代表 | |------|---------|------| | 1.0 | 下一个 token | GPT 系列 | | 2.0 | 下一帧像素 | Sora / 视频生成 | | 3.0 | 下一个物理状态 | Physis-v0.1 / RoboBrain Orca |
前两次范式跃迁,分别催生了一批平台级公司。陈博远在采访里说得很坦白:「这与语言模型从 GPT-3 到 ChatGPT 的路径高度吻合。」 投资人之所以愿意在两个月内连续投,本质就是在赌——世界模型的「ChatGPT 时刻」会在 18 到 24 个月内出现。
这不是空喊。具身智能、自动驾驶、工业仿真、药物发现这些场景,瓶颈其实都卡在同一件事上:现有大模型不理解物理规律,输出的结果在虚拟空间看着合理,丢到真实世界里就翻车。机器人抓杯子稍微角度不对就掉、自动驾驶在极端工况下不可预测,本质上都是这个缺口。
而通用世界基座模型一旦做成,就是给所有需要物理交互的下游任务提供一个统一底座——这件事一旦跑通,相当于把今天散落在 RL、仿真、SLAM、控制、CV 里的一堆中间件给吃掉。
同步发布的还有 RoboBrain Orca
这次智源把 Physis-v0.1 当作底座推出,配套发布的还有一个叫悟界·RoboBrain Orca 的具身大脑——同样以「下一个物理状态预测」为核心,但更靠近落地:「想、看、动」三位一体,目标是让机器人能在物流、酒店服务这类真实场景里做长时间自主作业。
你可以理解为:Physis 负责理解世界怎么演化,RoboBrain Orca 负责让一个具体的机器人在这个世界里干活。这种「底座 + 具身大脑」的双层架构,跟一年前 Figure、1X 那种端到端 VLA 路线明显不一样——前者押的是通用基座,后者押的是单机闭环。
团队和路线图
逆矩阵的组队方式有点反传统。陈博远、吉嘉铭都是北大青年学者,团队一半是学者(含奥赛金牌、省市状元、顶会一作),一半是来自一线大厂的工程老炮。组织上没有层级、没有季度 KPI,按陈博远的说法是「靠技术判断而非行政命令对齐方向」——这其实跟早期 OpenAI、DeepMind 的氛围更像。
路线图上,团队的节奏是这样的:
- 2026 年中:发布 Physis-v0.1,作为通用基座的第一个公开切片
- 2026 年底:发布旗舰模型,过程中会放出开源切片和技术报告
- 资金用途:预训练研发、规模化训练体系建设
这里有个细节值得注意——团队明确说会开源切片。在世界模型这个赛道,国内目前没有真正能用的开源底座。如果年底真能放出可复现的训练栈和权重,对整个具身智能社区就是个相当大的变量。
几句不那么客气的判断
抛开融资金额的热闹,几点冷静的看法:
第一,「全球首个通用世界基座模型」这个说法要打个折扣。Google DeepMind 的 Genie、英伟达的 Cosmos、World Labs 都在做类似的事,只是技术路径不同。Physis 的差异化在于物理隐空间而不是像素隐空间,这是技术选择,但「首个」更多是一个营销话术。
第二,v0.1 离能用还有距离。50 多个场景的长程推理听起来不少,但物理世界的 corner case 是无限的——刚体之外,流体、可形变物体、布料、粒子,每一类都是一个新的硬骨头。年底的旗舰版能不能把这些 cover 住,才是真正的考验。
第三,18 个月窗口期这个判断我倾向于认同。世界模型这件事跟语言模型最大的不同是——数据形态高度多样、评测体系还没标准化。先做出一个被广泛认可的 benchmark + 底座的团队,就会拿走大部分话语权。这事跟 ChatGPT 当年的逻辑一样,先到先得。
第四,对国内开发者最实际的影响是:等年底切片开源之后,具身智能这边的训练成本可能会被显著拉低——不用再自己从零搭物理仿真+视觉表征+动作预测的全链路,直接微调底座就行。
世界模型这一仗,国内这次算是真的没掉队。Physis-v0.1 是不是终局先不论,但「预测下一个物理状态」这个范式被立住了,接下来就是看谁先把它跑到 ChatGPT 的那个临界点。
参考来源
- 知乎:如何看待智源研究院发布通用世界基座模型 Physis-v0.1 — 社区围绕 Physis-v0.1 技术路径和与 JEPA、Genie 对比的讨论
- Hugging Face Models — 关注后续开源切片与权重发布动态


