IBM发布ALTK-Evolve:AI Agent边干边学的时代来了

IBM Research开源ALTK-Evolve框架,让AI Agent在执行任务过程中实时学习、自我进化,不再依赖离线微调。这可能是Agent从「工具」变成「同事」的关键一步。
IBM Research 上周正式开源了 ALTK-Evolve,一个让 AI Agent 在执行任务过程中持续学习的框架。说白了,就是让 Agent 不再是一个「用完即弃」的推理管道,而是一个能积累经验、越用越好的系统。
这件事值得认真聊聊。
问题出在哪
当前主流的 Agent 框架——不管是 LangChain、AutoGen 还是 CrewAI——本质上都是「无状态」的。每次调用,Agent 从零开始推理,哪怕同样的任务它昨天刚做过一遍。
这就像你公司新来了一个实习生,每天早上记忆都会被清空。你得反复教他同样的事情。
当然,你可以通过 RAG 给 Agent 挂一个外部知识库,或者用 few-shot 把历史案例塞进 prompt。但这些都是「被动记忆」——你手动整理、手动喂给它。Agent 自己不会从失败中学到什么,也不会把成功经验沉淀下来。
微调是另一条路,但成本高、周期长,而且一旦任务场景变了,之前的微调可能反而成了负担。
ALTK-Evolve 想解决的就是这个问题:让 Agent 在「干活的过程中」自己学。
ALTK-Evolve 到底做了什么
ALTK 是 Agent Long-Term Knowledge 的缩写,Evolve 则强调这套知识是动态演化的。整个框架的核心思路可以拆成三层:
1. 长期记忆层(Long-Term Memory)
这不是简单的向量数据库检索。ALTK-Evolve 维护了一套结构化的经验存储,每条记忆包含:
- 任务上下文(做了什么)
- 执行轨迹(怎么做的)
- 结果反馈(做得好不好)
- 抽象策略(从中提炼出的通用规则)
关键在最后一项。框架不只是记住「上次遇到这个问题我用了什么 prompt」,而是会把具体经验抽象成可迁移的策略。比如 Agent 在处理 CSV 数据清洗时发现「先检查编码再处理缺失值」的顺序更高效,这条策略会被提炼出来,下次遇到类似但不完全相同的任务时也能用上。
2. 在线学习循环(On-the-Job Learning Loop)
Agent 每完成一个任务(或者任务失败),都会触发一个学习循环:
- 回顾刚才的执行过程
- 对比预期结果和实际结果
- 识别哪些决策点是关键的
- 更新长期记忆中的策略权重
这个过程不需要人工介入,也不需要离线训练。它发生在推理时,用的就是 LLM 本身的能力。
你可以把它理解成一个「反思-总结-记住」的自动化流程。每次任务结束,Agent 花几秒钟复盘,然后把心得存起来。
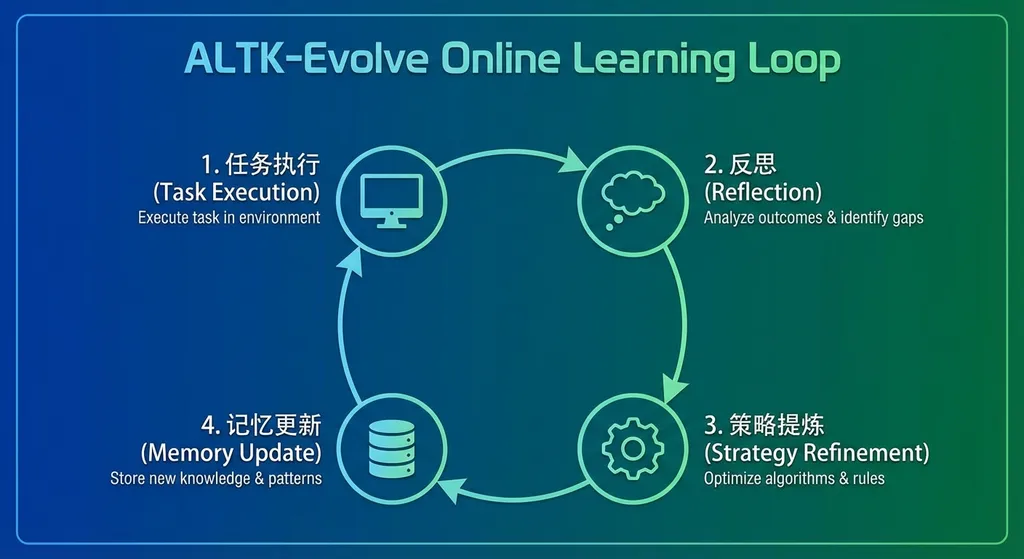
3. 策略进化机制(Strategy Evolution)
这是最有意思的部分。随着任务量增加,Agent 积累的策略会越来越多,其中有些可能互相矛盾。ALTK-Evolve 引入了一套策略进化机制:
- 高频被调用且效果好的策略,权重上升
- 反复导致失败的策略,权重下降甚至被淘汰
- 相似的策略会被合并、精炼
- 新策略会和旧策略竞争
有点像遗传算法的味道,但作用在「知识」层面而不是参数层面。Agent 的能力提升不是通过改变模型权重,而是通过优化它的「工作方法论」。
跟现有方案比怎么样
说实话,「让 Agent 有记忆」这个方向不是 IBM 首创。MemGPT(现在叫 Letta)很早就在做类似的事,Reflexion 框架也探索过 Agent 自我反思的路径。
但 ALTK-Evolve 有几个明显的差异点:
第一,它不绑定特定模型。框架设计上是模型无关的,底层可以接 GPT-4o、Claude、Gemini,甚至开源的 Llama 和 DeepSeek。这一点很实用——你不会想因为换了个模型就丢掉 Agent 积累的所有经验。
第二,策略是可解释的。不像微调后的模型,你根本不知道它「学到了什么」,ALTK-Evolve 的策略存储是人类可读的。你可以审查 Agent 学到的规则,删掉不合理的,甚至手动添加新的。这对企业级应用来说非常重要。
第三,它和 IBM 的 watsonx 生态做了深度集成。从演示视频来看,ALTK-Evolve 已经跑在 IBM Bob(IBM 的 Agent 开发平台)上了,配合 watsonx Orchestrate 可以直接部署到生产环境。当然,框架本身是开源的,你完全可以独立使用。
不过也得说,这个框架目前还比较早期。从 Hugging Face 博客的描述来看,它在复杂多步骤任务上的表现提升明显,但在简单的单轮问答场景下,额外的学习开销反而可能拖慢响应速度。适用场景还是偏向那些需要反复执行、逐步优化的工作流。
实际跑起来是什么样的
从 IBM 放出的 demo 来看,一个典型的使用场景是这样的:
你让 Agent 帮你做数据分析。第一次,它可能会选择一个不太高效的处理路径,比如先做可视化再做清洗。任务完成后,学习循环介入,Agent 意识到「应该先清洗再可视化」,把这条策略记下来。
第二次遇到类似任务,Agent 直接采用优化后的路径。第三次、第四次,策略进一步精炼。到第十次的时候,Agent 处理这类任务的效率和准确率已经比第一次高出一大截。
这种「越用越顺手」的体验,才是 Agent 真正有价值的地方。
框架的安装和使用看起来不复杂。它以 Python 包的形式发布,核心依赖不多。如果你已经有一个基于 LLM 的 Agent 系统,集成 ALTK-Evolve 主要是在 Agent 的执行循环里加入记忆读写和学习触发的逻辑。
对开发者意味着什么
如果你正在做 Agent 相关的开发,ALTK-Evolve 提供了一个值得关注的思路:与其花大力气做 prompt engineering 或者攒训练数据去微调,不如让 Agent 自己在实战中学习。
这个框架底层调用的还是大模型的 API。由于它不绑定特定模型,你可以根据任务复杂度灵活切换——简单的反思总结用便宜的模型,关键决策用强模型。如果你需要在一个入口调用多家模型,OpenAI Hub 这类 API 聚合服务可以省不少事,一个 Key 就能切换 GPT、Claude、Gemini、DeepSeek 等主流模型,接口都是 OpenAI 兼容格式。
一个简化的集成示例,展示如何在 Agent 循环中接入 ALTK-Evolve 的记忆模块:
from openai import OpenAI
# 通过 OpenAI Hub 聚合调用,可随时切换底层模型
client = OpenAI(
base_url="https://api.openai-hub.com/v1",
api_key="your-openai-hub-key"
)
# 模拟 ALTK-Evolve 的记忆检索 + 任务执行 + 学习循环
def agent_with_learning(task: str, memory_store: list):
# Step 1: 从长期记忆中检索相关策略
relevant_strategies = retrieve_strategies(memory_store, task)
# Step 2: 将策略注入 system prompt
system_prompt = "你是一个持续学习的 AI Agent。\n"
if relevant_strategies:
system_prompt += "以下是你从过往经验中总结的策略,请参考执行:\n"
for s in relevant_strategies:
system_prompt += f"- {s}\n"
# Step 3: 执行任务(可灵活切换模型)
response = client.chat.completions.create(
model="gpt-4o", # 或 claude-sonnet-4-20250514、gemini-2.5-pro、deepseek-chat
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": task}
]
)
result = response.choices[0].message.content
# Step 4: 触发学习循环——让模型反思并提炼策略
reflection = client.chat.completions.create(
model="gpt-4o-mini", # 反思环节可以用更轻量的模型
messages=[
{"role": "system", "content": "回顾以下任务和执行结果,提炼一条可复用的策略。"},
{"role": "user", "content": f"任务:{task}\n结果:{result}"}
]
)
new_strategy = reflection.choices[0].message.content
# Step 5: 更新长期记忆
memory_store.append(new_strategy)
return result
这只是一个极简示意。真正的 ALTK-Evolve 在策略存储、检索、进化方面做了大量工程优化,但核心循环就是这个逻辑:执行 → 反思 → 记忆 → 下次更好。
冷静看几个问题
任何新框架都不该被无脑吹。ALTK-Evolve 有几个需要观察的点:
记忆污染问题。如果 Agent 从一次错误的执行中提炼出了错误的策略,这条「坏经验」会不会在后续任务中持续产生负面影响?框架虽然有策略淘汰机制,但在早期数据量不大的时候,一条坏策略的影响可能被放大。
成本问题。每次任务结束后的反思环节,本质上是额外的 LLM 调用。如果你的 Agent 每天执行上千次任务,这个开销不可忽视。当然,你可以用更便宜的模型来做反思,或者设置触发条件(比如只在任务失败时才学习),但这些都需要根据实际场景调优。
多 Agent 协作场景下的知识共享。目前看起来 ALTK-Evolve 的记忆是单 Agent 维度的。如果你有一个多 Agent 系统,Agent A 学到的经验能不能自动同步给 Agent B?这个问题博客里没有详细展开。
还有一个更根本的问题:LLM 自己做的「反思」到底靠不靠谱?模型总结出来的策略,有可能是正确的归因,也有可能是「幻觉式归因」——它以为某个步骤是关键的,但实际上不是。这个问题在 Reflexion 等早期工作中就被讨论过,ALTK-Evolve 是否有更好的解决方案,还需要看更多的实验数据。
往大了说
2026 年 Agent 赛道最明显的趋势,就是从「能用」走向「好用」。去年大家还在讨论 Agent 能不能完成复杂任务,今年的焦点已经转向了怎么让 Agent 更可靠、更高效、更省钱。
ALTK-Evolve 代表的方向——在线学习、经验积累、策略进化——很可能是下一阶段 Agent 框架的标配能力。不一定是 IBM 这套实现最终胜出,但这个思路是对的。
一个不会学习的 Agent,本质上就是一个花哨的 API wrapper。一个能从经验中进化的 Agent,才有可能真正成为你的「AI 同事」。
IBM 这次把框架开源了,代码在 GitHub 上可以直接拉。如果你在做 Agent 相关的项目,建议花半天时间跑一下 demo,感受一下「Agent 越用越聪明」到底是什么体验。
参考来源:
- ALTK-Evolve GitHub 仓库 — IBM Research 开源的 ALTK-Evolve 框架源码及文档
